
The Sysdig Platform
From prevention to defense, our CNAPP helps you prioritize the risks that matter most – now.
Now Is the Time to Unify Your Cloud Security
In the cloud, every second counts. We’re the industry’s only cloud security platform that delivers the breadth of coverage and depth of insights required to protect your cloud environments. Secure Every Second with Sysdig.

Security for Every Part of Your Cloud Journey
Cloud Detection & Response
Stop attacks faster with real-time detection and end-to-end coverage.
Vulnerability Management
Scan for vulnerabilities in seconds and get a comprehensive vulnerability assessment.
Posture Management
Get a single view of risk and instantly identify posture drift across cloud environments.
Permissions & Entitlements
Identify users and identities with excessive permissions and instantly manage access.
Secure Every Second in the Cloud
with Runtime Insights
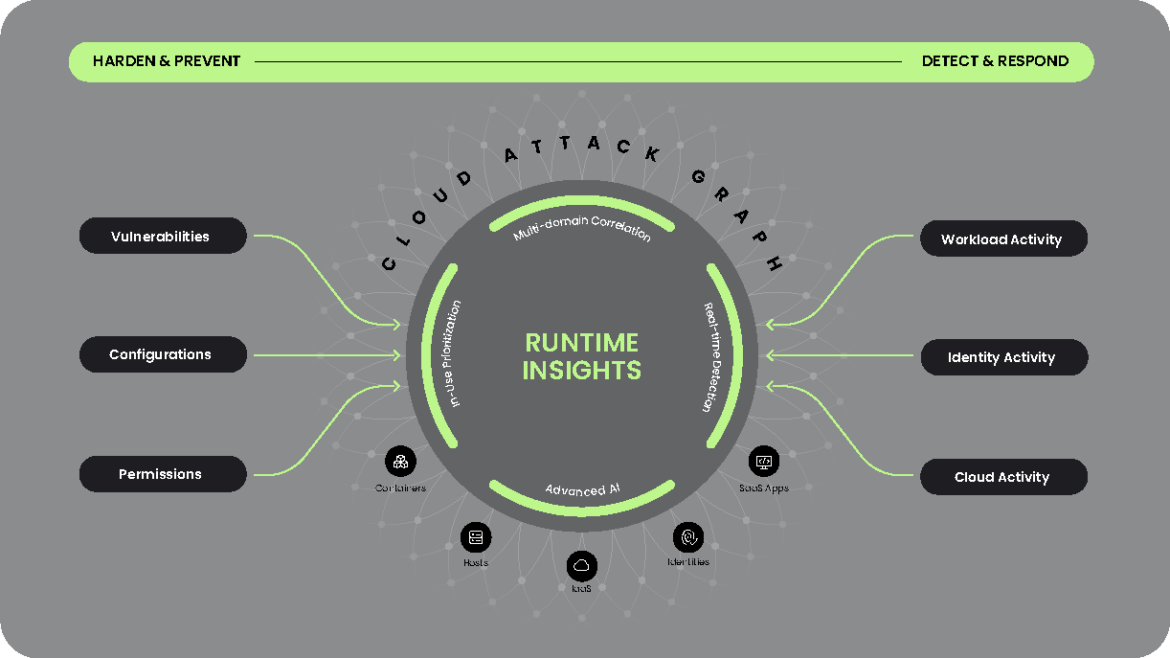
Runtime insights leverages knowledge of what’s in use to prioritize risks that matter and provide context to remediate them.
Prevent, Detect, and Respond to Attacks
Runtime insights help you quickly prioritize and mitigate risk, detect and respond to threats, and scale cloud security.
Instantly Know Your Real Risks
The Cloud Attack Graph helps security teams correlate, contextualize, and prioritize data from multiple sources to identify real risks in seconds.
Identify, Prioritize, and Remediate Misconfiguration
Seamlessly prioritize risks, enhance mitigation effectiveness, and bolster your enterprise security strategy and posture with real-time context.
Industry Leading Security

Based on Open Standards
We built the Sysdig platform on an open source stack to accelerate innovation and drive standardization. Maximize your coverage with community-sourced detection rules that are easily customizable.

Integrations
Our cloud and container security solutions integrate with the platforms and tools that drive your modern application infrastructure.




Take the Next Step!
See how you can secure every second in the cloud.