



Falco Feeds extends the power of Falco by giving open source-focused companies access to expert-written rules that are continuously updated as new threats are discovered.

Why response matters in Kubernetes
In modern Kubernetes environments, detecting threats is only half the battle. What truly matters is how quickly and effectively you can respond, should a threat be detected. With workloads spinning up and down in seconds, and containers often leaving behind little trace, the window for meaningful action is narrow. Sysdig’s 555 Benchmark for Cloud Detection and Response shows that fast detection alone isn’t enough. You need to detect, investigate, and respond in under 10 minutes. In this blog, we will take you through a Kubernetes detection and response workflow to show how Sysdig’s inline response actions deliver better outcomes with speed and confidence.
Faster response times have a direct impact on Mean Time to Contain (MTTC), reducing the window in which attackers can move laterally or exfiltrate data. By shortening MTTC, teams minimize risk exposure and limit the blast radius of an incident.
We recently published a blog on inline response actions for host environments. In this blog, we will explore a Kubernetes-specific response workflow using Sysdig’s latest inline capabilities.
Introducing inline Kubernetes actions
Inline response actions enable you to take immediate, context-aware action directly from a Sysdig event, so you can respond to threats or issues without switching tools. From taking a volume snapshot to isolating the network, automated and precise response actions are essential to reduce dwell time, contain incidents, and keep Kubernetes environments secure.
Accessing workloads to investigate and respond to security incidents often requires help from other teams with different skill sets. This dependency slows down response efforts and adds unnecessary complexity for security teams. Kubernetes makes the challenge even harder by introducing additional layers of abstraction and operational intricacy.
Responding to incidents typically requires:
- Having the right access to target resources
- Knowing how to locate and connect to those resources
- Understanding Kubernetes specifics, such as which commands to run and how
- Navigating the risk of unintentionally impacting production environments
Sysdig addresses this by expanding response capabilities directly to the areas where security teams struggle most. With Sysdig, access and connectivity are handled automatically, and the need for deep Kubernetes expertise is greatly reduced. This minimizes the risk of mistakes and accelerates your ability to respond effectively across your managed on-prem and cloud Kubernetes environments (e.g., GCP, AZURE, AWS, Oracle, etc.).
Let’s walk through a real-world incident response scenario using the Sysdig Threat Management Dashboard. We’ll show how contextual insights and inline actions streamline investigation and remediation, putting your team on their way to meeting the 555 benchmark.
Walkthrough: Real-world high-severity Kubernetes threat
As we review the Sysdig Threat Management dashboard, our attention is grabbed by a high severity Kubernetes threat being detected on a workload labeled “Potential Malware Activity.”
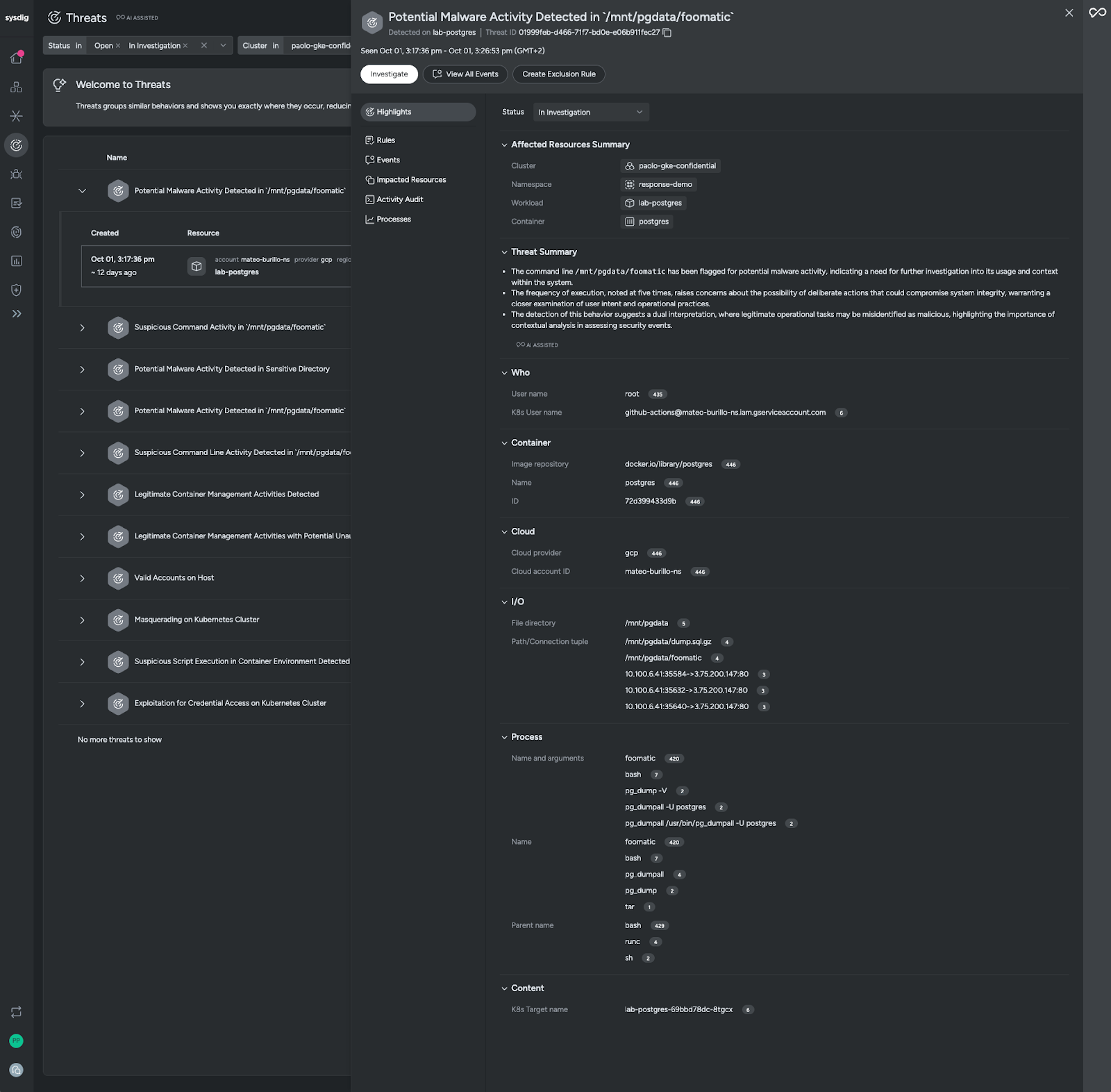
Critical context at your fingertips
Clicking into the threat detection, we rapidly gain critical context via the threat summary provided by Sysdig Sage™. We learn:
- The command line
/mnt/pgdata/foomatichas been flagged for potential malware activity, indicating a need for further investigation into its usage and context within the system. - The frequency of execution, noted at five times, raises concerns about the possibility of deliberate actions that could compromise system integrity. This warrants a closer examination of user intent and operational practices.
- The detection of this behavior suggests a dual interpretation, where legitimate operational tasks may be misidentified as malicious, highlighting the importance of contextual analysis in assessing security events.
Drilling deeper
Context below the threat summary will give us additional clues to understand the who, what, where, when, and how of this potential threat:
- The github-action service account executed something.
- Some connections were made to the HTTP port.
pg_dumpallwas executed along with tar and a suspicious foomatic utilization.
Defining the scope of impact
As we dig in, we will look to understand the scope of impact, and especially the specific resources involved. In this example, we note that the impacted resource is a Kubernetes Deployment of Postgres in GKE.

Evaluating correlated events
After understanding what resources were impacted, we pivot into the individual but related events that made up the threat. Our detections show a flurry of outbound connections to C2 servers, performed by foomatic, the same unknown potentially malicious executable shown in the Threat Summary.
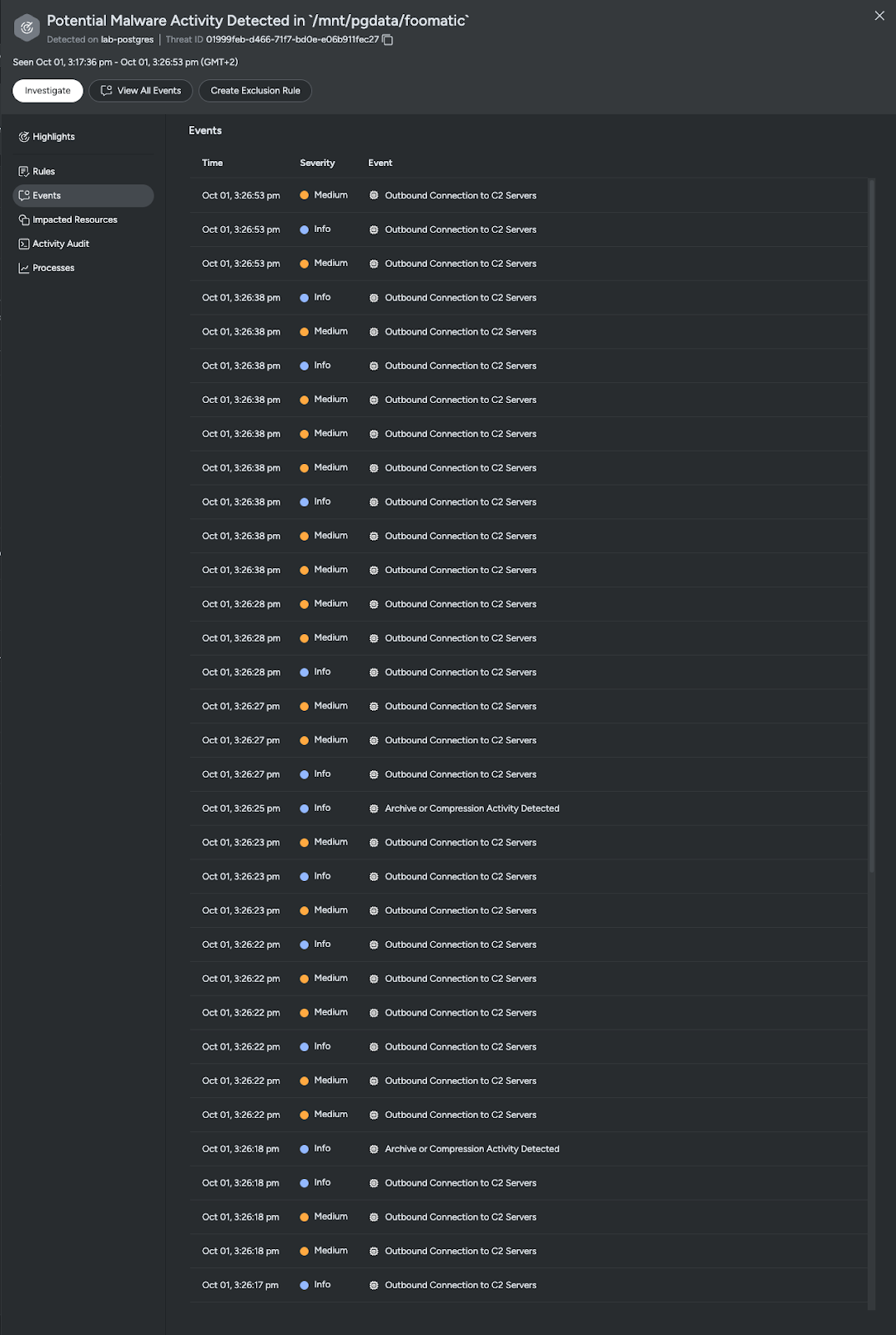
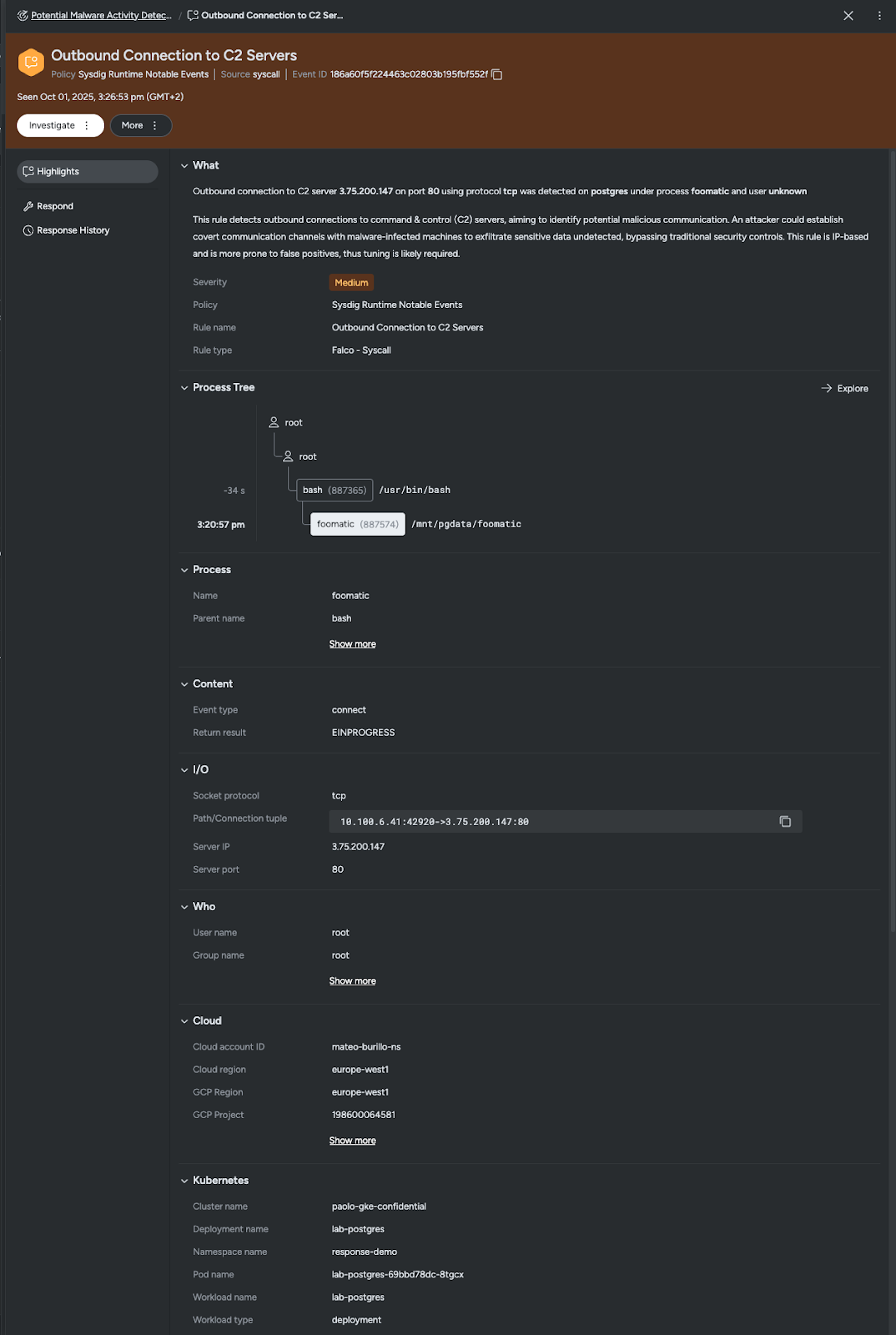
Evaluating potentially explosive combos
Checking into further events in the C2 connections, we see the potential correlation between postgresql deployment in alignment with behaviors where `foomatic` was leveraged. This is alarming, as other events have triggered for `foomatic` as the result of its malware designation.

With the observed information, we can say with high confidence that this is not a benign action or a false positive.
Collecting Kubernetes forensic data with Sysdig
Our next workflow step is to collect forensic data, so that after we remediate the threat we have sufficient artifacts to perform an accurate post-mortem analysis. The new Kubernetes response capabilities broaden the available actions you can execute inline with just a few clicks. For impactful collections, Sysdig has new capabilities:
- Volume snapshot: Capture the content of a volume that can later be mounted and analyzed, allowing you to perform cleanup activities. A secondary use case is to collect the volumes without the attacker knowing so they cannot just delete their tracks, further compromising forensic analysis.
- Get logs: Access the Kubernetes logs from applications, showing authentications and other behaviors that can be used to better understand the course of action during an attack.
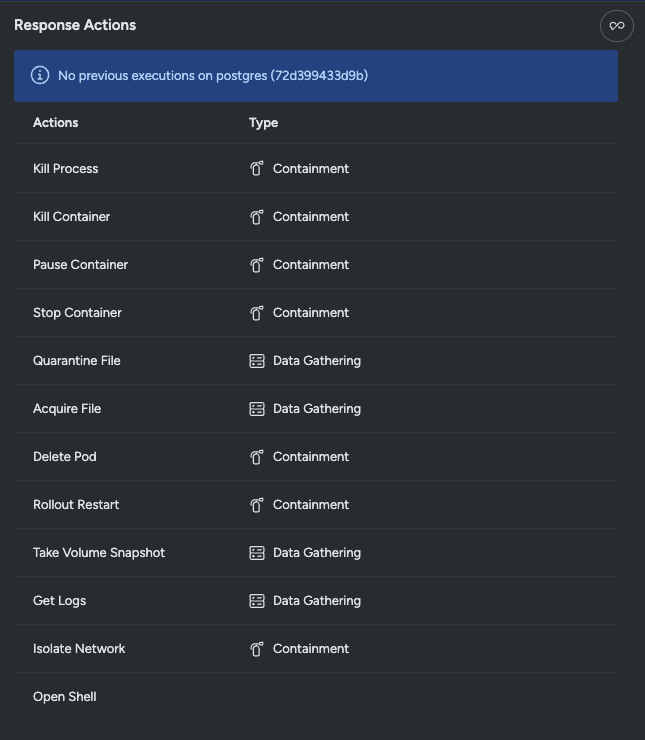
Knowing that malware from inside a workload was executed, we should immediately take a snapshot of the volume from the postgresql victim workload.
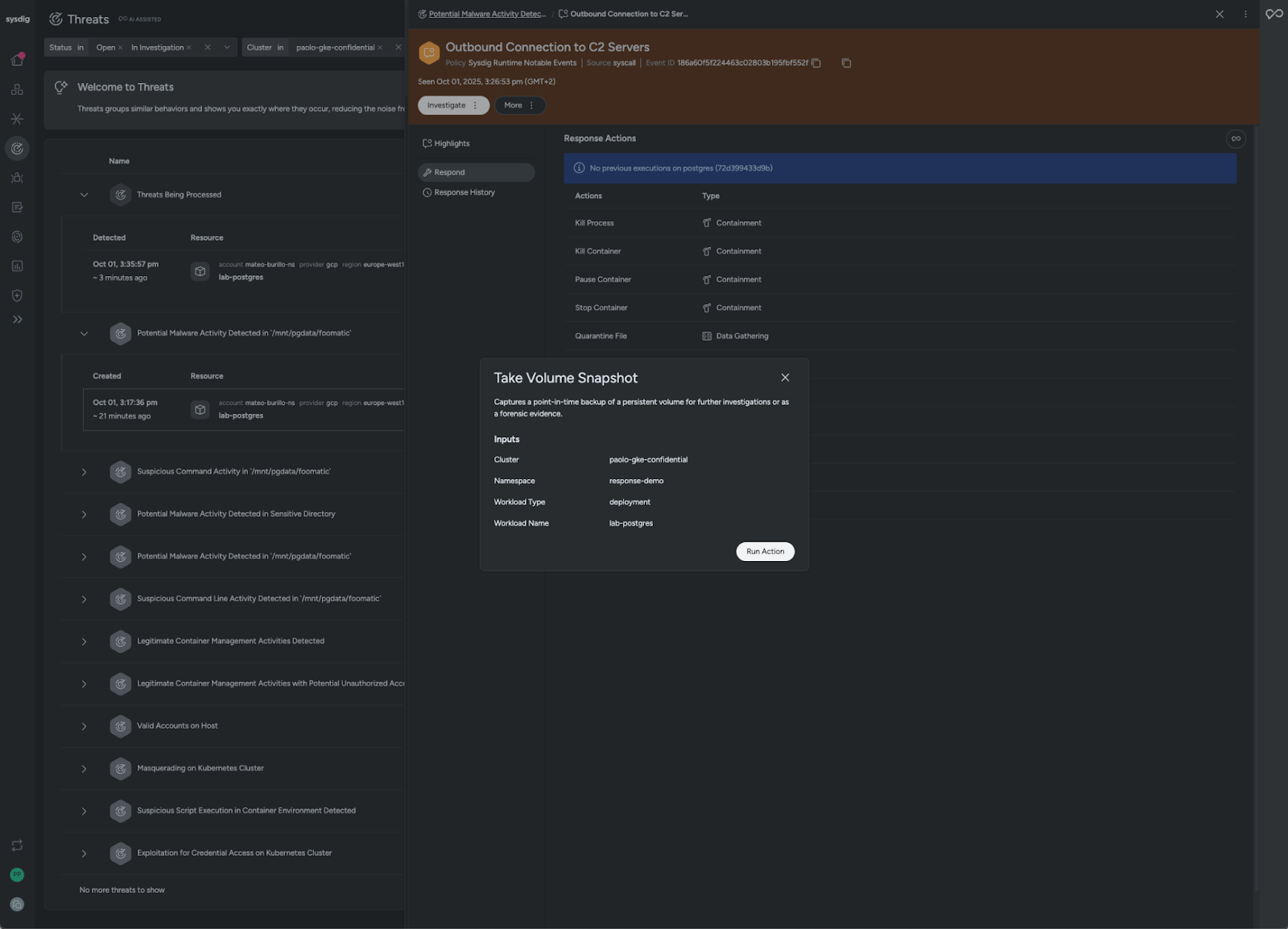
This snapshot allows us to reconstruct the attack, assess its impact, and improve defenses to prevent recurrence.
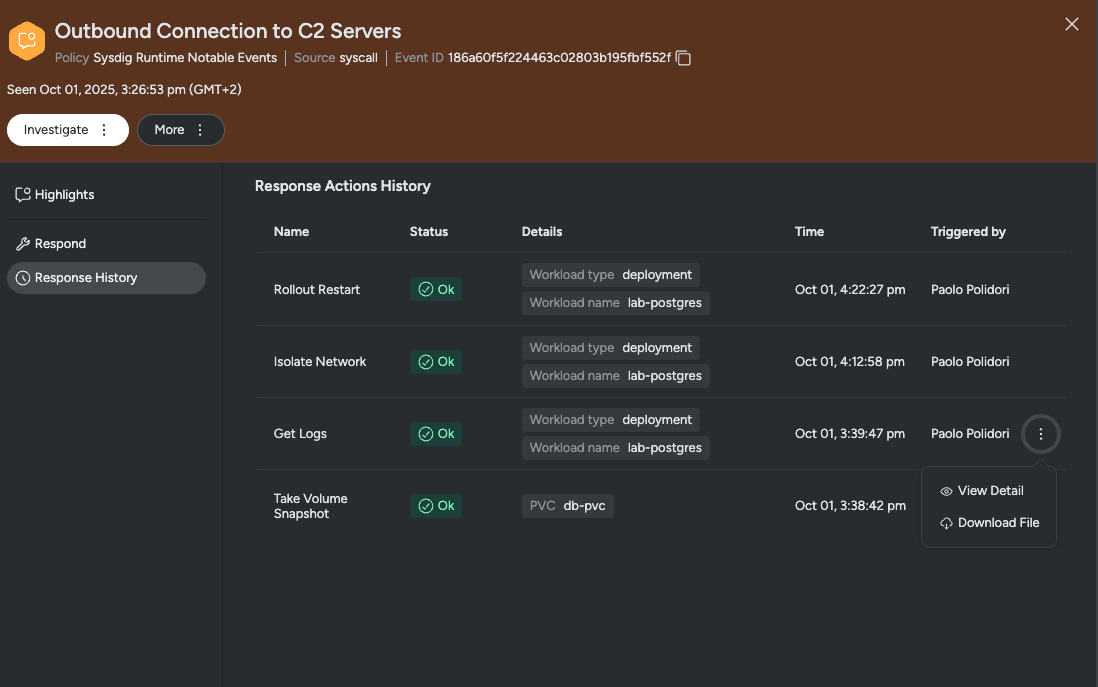
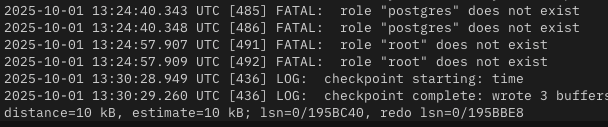
Digging deeper, we will use Get Logs to see how the attacker interacted with the deployment. During this analysis, we see multiple failed authentication attempts. This likely indicates attempted data exfiltration.
Threat containment and recovery: How Sysdig accelerates response actions
Regardless of whether data was exfiltrated or not, this behavior needs to be stopped. Previously, this would have required teams to have extensive domain expertise capabilities, including:
- Kubernetes knowledge, to execute the right commands with the right syntax without risking unwanted disruptions
- Infrastructure knowledge, i.e., where things are located and how to access a cluster
Teams also needed to either have the right permissions, or involve people who have those permissions.
How Sysdig streamlines the containment
Sysdig’s new Kubernetes actions make this process faster and simpler with some powerful containment actions:
- Rollout restart: Clean up the pods of a workload, forcing them to be recreated from a fresh state without disrupting normal operations.
- Delete pod: Eliminate a compromised workload. This is useful in case of non-critical standalone pods that can be eliminated without impacting production environments, as well as pods that are not part of a workload, like in CronJobs. This is also helpful when you want to enact a more precise workload cleanup on single pods.
- Isolate network: Block connections, incoming or outgoing, broadly to all connections or more narrowly to specific ports/IPs.
Real-world containment example
In this scenario, we wouldn't expect a database to perform HTTP connections, so we can safely stop the connection to the C2 IP, since we’re now sure it’s an undesired connection. To take a bolder approach, we could block all connections to port 80, or even block all outgoing connections, as a database hardly needs them. In this scenario, we wanted to take a safe and conservative approach, so we decided to stop connections to the exact IP and port.
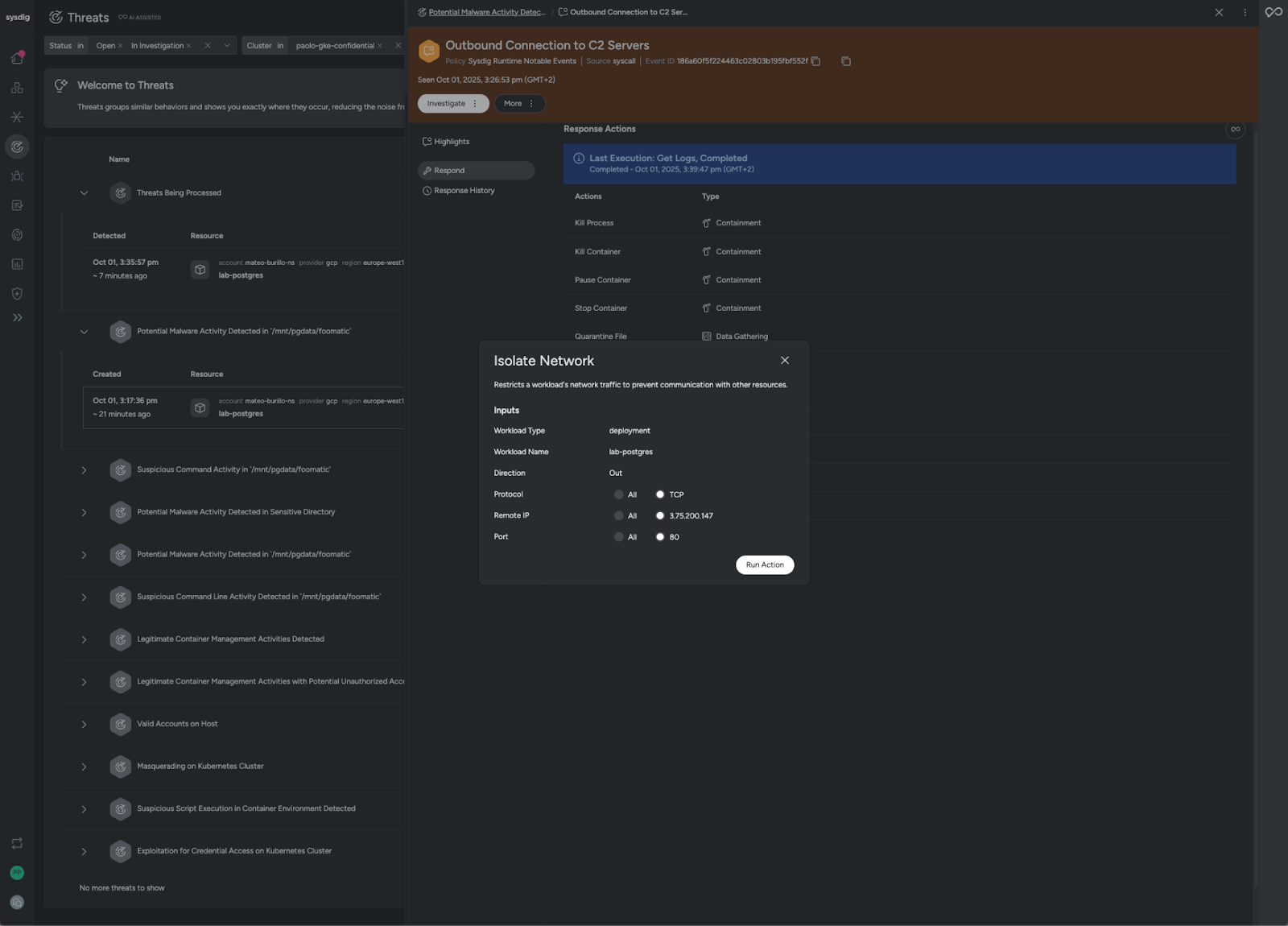
Stopping the connections to the exact IP and port should be more than adequate to stop the threat. However, because we already collected the necessary forensic data, we can restart the workload to remove any persistence and reduce the risk of repeat attacks. Using these new features, teams can shorten the time between detection and resolution, enabling security teams to act with precision and confidence at cloud-native speed.

Final thoughts
Responding quickly and confidently to Kubernetes threats requires more than just detection; it demands fast, contextually informed action. With workloads changing constantly and threats hiding in ephemeral environments, traditional incident response approaches can no longer keep up.
Sysdig’s new inline Kubernetes response capabilities extend detection with powerful, targeted actions that help teams investigate, contain, and remediate threats, without requiring deep Kubernetes expertise or cumbersome cross-team dependencies.
These capabilities slash mean time to contain (MTTC) by enabling instant, in-context action. Teams can stop threats faster, limit damage, and reduce risk before it spreads.
By providing automated tools like volume snapshots, log retrieval, and network isolation, Sysdig empowers security and platform teams to reduce dwell time, prevent attacker persistence, and strengthen defenses against future attacks.