



Falco Feeds extends the power of Falco by giving open source-focused companies access to expert-written rules that are continuously updated as new threats are discovered.

This article is part of our series on operating Kubernetes in production. Part 1 covered the basics of Kubernetes and monitoring tools; Part 2 covered Kubernetes alerting best practices. This part will cover Kubernetes troubleshooting, particularly service discovery, and the final section is a real-world use case of monitoring Kubernetes. Container orchestration platforms like Kubernetes, DC/OS Mesos or Docker Swarm help towards making your experience like riding an unicorn over a rainbow, but don't help much with troubleshooting containers:
- They are isolated, there is a barrier between you and the process you want to monitor and traditional troubleshooting tools run on the host doesn't understand containers, namespaces and orchestration platforms.
- They bring a minimal runtime, just the service and its dependencies without all the troubleshooting tools, think of troubleshooting with just busybox!
- They are scheduled across your cluster… containers move, scale up and down. Are highly volatile, appearing and disappearing as the process ends, gone.
- And talk to each other through new virtual network layers.
Today we will demonstrate through a real use case how to do troubleshooting in Kubernetes. We will cover troubleshooting across 3 different layers inside Kubernetes:
- Part1: Kubernetes troubleshooting: service discovery
- Part2: Kubernetes troubleshooting: DNS resolution
- Part3: Kubernetes troubleshooting: containers run by Docker
The scenario will use is a simple Kubernetes service with 3 Nginx pods and a client with curl. In the previous link you will find the backend.yaml file we will use for this scenario. If you are new to Kubernetes services, we explained how to deploy this service and learned how it works in Understanding how Kubernetes DNS Services work.To bring up the setup, will run:$ kubectl create namespace critical-appAnd then will spawn a client to load our backend service:
namespace "critical-app" created
$ kubectl create -f backend.yaml
service "backend" created
deployment "backend" created$ kubectl run -it --image=tutum/curl client --namespace critical-app --restart=Never Reverse engineering and troubleshooting #Kubernetes service discovery Click to tweet
Part 1: Kubernetes troubleshooting: service discovery
From our client container we could simply run a test by doing root@client:/# curl backend to see how our Kubernetes service works. But we don't want to leave things loose, and we thought that using fully qualified domain names for service discovery testing is a good idea. If we go and check Kubernetes documentation it says that every service gets this default DNS entry: my-svc.my-namespace.svc.cluster.local. So let's instead use the full domain name.Let's go back to the curl client container shell and run: root@client:/# curl backend.critical-app.svc.cluster.local. But this time curl hangs for 10 seconds and then correctly returns the expected website! As a distributed systems engineer, this is one of the worst things that can happen: you want something to fail or succeed straight away, not a wait of 10 seconds.To troubleshoot what's going on, we will use Sysdig. Sysdig is an open source linux visibility tool that offers native visibility into containers, including Docker, Kubernetes, DC/OS, and Mesos just to name a few. Combining the functionality of htop, tcpdump, strace, lsof, netstat, etc in one open source tool, Sysdig gives you all of the system calls and application data in the context of your Kubernetes infrastructure. Monitoring Kubernetes with Sysdig is a good introduction to using the tool with Kubernetes.To analyze what is going on, we will ask sysdig to dump all the information into a capture file:$ sudo sysdig -k http://127.0.0.1:8080 -s8192 -zw capture.scapI'll quickly explain each parameter here:-k http://localhost:8080 connects to Kubernetes API,-s8192 enlarges the IO buffers, as we need to show full content, otherwise gets cut off by default,-zw capture.scap compresses and dumps into a file all system calls and metadata.In parallel, we'll reproduce this hairy issue again running the curl command: # curl backend.critical-app.svc.cluster.local. This ensures that we have all the appropriate data in the file we captured above to reproduce the scenario and troubleshoot the issue.Once curl returns, we can Ctrl+C sysdig to stop the capture, and we will have a ~10s capture file of everything that happened in our Kubernetes host, including the service discovery process. We can now start troubleshooting the issue either in the cluster or out of band, basically anywhere we copy the file with sysdig installed$ sysdig -r capture.scap -pk -NA "fd.type in (ipv4, ipv6) and (k8s.ns.name=critical-app or proc.name=skydns)" | lessLet me explain each parameter here as well:-r capture.scap reads from a capture file,-pk prints Kubernetes fields in stdout,-NA shows ASCII output,And the filter between double quotes. Sysdig is able to understand Kubernetes semantics so we can filter out traffic on sockets IPv4 or IPv6, coming from any container in the namespace critical-app or from any process named skydns. We included proc.name=skydns because this is the internal Kubernetes DNS resolver and runs outside our namespace, as part of the Kubernetes infrastructure.
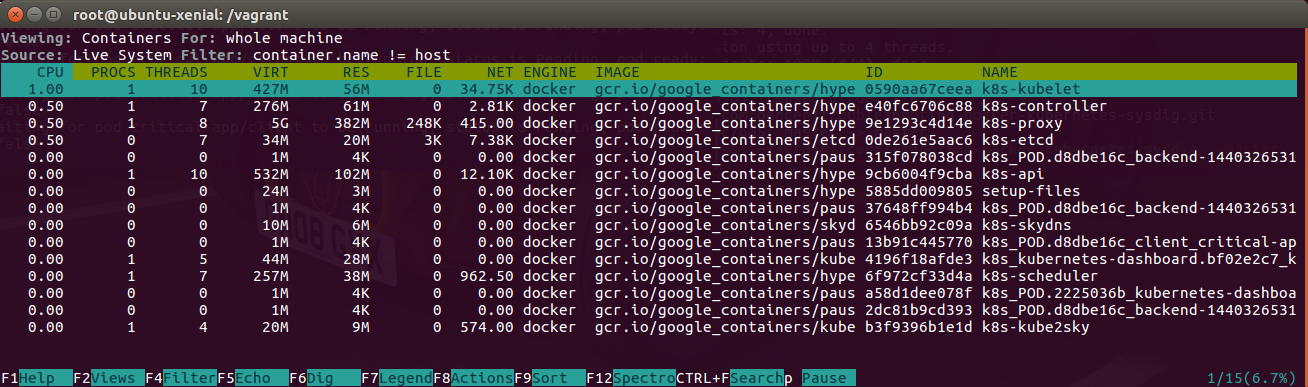
Sysdig also has an interactive ncurses interface htop alikeIn order to follow along with this service discovery troubleshooting example, you can download the capture file capture.scap and explore it yourself with sysdig.Immediately we see how curl tries to resolve the domain name but on the DNS query payload we have something odd (10049): backend.critical-app.svc.cluster.local.critical-app.svc.cluster.local. Seems like for some reason curl didn't understand I gave it a fully qualified domain name already and decided to append a search domain to it.[...]SkyDNS makes a request (10097) to /local/cluster/svc/critical-app/local/cluster/svc/critical-app/backend through the etcd API. Obviously etcd doesn't recognize that service and returns (10167) a "Key not found". This is passed back to curl via DNS query response.
10030 16:41:39.536689965 0 client (b3a718d8b339) curl (22370:13) < socket fd=3(<4>)
10031 16:41:39.536694724 0 client (b3a718d8b339) curl (22370:13) > connect fd=3(<4>)
10032 16:41:39.536703160 0 client (b3a718d8b339) curl (22370:13) < connect res=0 tuple=172.17.0.7:46162->10.0.2.15:53
10048 16:41:39.536831645 1 (36ae6d09d26e) skydns (17280:11) > recvmsg fd=6(<3t>:::53)
10049 16:41:39.536834352 1 (36ae6d09d26e) skydns (17280:11) < recvmsg res=87 size=87 data=
backendcritical-appsvcclusterlocalcritical-appsvcclusterlocal tuple=::ffff:172.17.0.7:46162->:::53
10050 16:41:39.536837173 1 (36ae6d09d26e) skydns (17280:11) > recvmsg fd=6(<3t>:::53)
[...][...]curl doesn't give up and tries again (10242) but this time with backend.critical-app.svc.cluster.local.svc.cluster.local. Looks like curl is trying a different search domain this time, as critical-app was removed from the appended domain. Of course, when forwarded to etcd (10274), this fails again (10345).
10096 16:41:39.538247116 1 (36ae6d09d26e) skydns (4639:8) > write fd=3(<4t>10.0.2.15:34108->10.0.2.15:4001) size=221
10097 16:41:39.538275108 1 (36ae6d09d26e) skydns (4639:8) < write res=221 data=
GET /v2/keys/skydns/local/cluster/svc/critical-app/local/cluster/svc/critical-app/backend?quorum=false&recursive=true&sorted=false HTTP/1.1
Host: 10.0.2.15:4001
User-Agent: Go 1.1 package http
Accept-Encoding: gzip
10166 16:41:39.538636659 1 (36ae6d09d26e) skydns (4617:1) > read fd=3(<4t>10.0.2.15:34108->10.0.2.15:4001) size=4096
10167 16:41:39.538638040 1 (36ae6d09d26e) skydns (4617:1) < read res=285 data=
HTTP/1.1 404 Not Found
Content-Type: application/json
X-Etcd-Cluster-Id: 7e27652122e8b2ae
X-Etcd-Index: 1259
Date: Thu, 08 Dec 2016 15:41:39 GMT
Content-Length: 112
{"errorCode":100,"message":"Key not found","cause":"/skydns/local/cluster/svc/critical-app/local","index":1259}
[...][...]curl will try once again, this time appending cluster.local as we can see the DNS query request (10418) to backend.critical-app.svc.cluster.local.cluster.local. This one (10479) obviously fails as well (10524), again.
10218 16:41:39.538914765 0 client (b3a718d8b339) curl (22370:13) < connect res=0 tuple=172.17.0.7:35547->10.0.2.15:53
10242 16:41:39.539005618 1 (36ae6d09d26e) skydns (17280:11) < recvmsg res=74 size=74 data=
backendcritical-appsvcclusterlocalsvcclusterlocal tuple=::ffff:172.17.0.7:35547->:::53
10247 16:41:39.539018226 1 (36ae6d09d26e) skydns (17280:11) > recvmsg fd=6(<3t>:::53)
10248 16:41:39.539019925 1 (36ae6d09d26e) skydns (17280:11) < recvmsg res=74 size=74 data=
0]backendcritical-appsvcclusterlocalsvcclusterlocal tuple=::ffff:172.17.0.7:35547->:::53
10249 16:41:39.539022522 1 (36ae6d09d26e) skydns (17280:11) > recvmsg fd=6(<3t>:::53)
10273 16:41:39.539210393 1 (36ae6d09d26e) skydns (4639:8) > write fd=3(<4t>10.0.2.15:34108->10.0.2.15:4001) size=208
10274 16:41:39.539239613 1 (36ae6d09d26e) skydns (4639:8) < write res=208 data=
GET /v2/keys/skydns/local/cluster/svc/local/cluster/svc/critical-app/backend?quorum=false&recursive=true&sorted=false HTTP/1.1
Host: 10.0.2.15:4001
User-Agent: Go 1.1 package http
Accept-Encoding: gzip
10343 16:41:39.539465153 1 (36ae6d09d26e) skydns (4617:1) > read fd=3(<4t>10.0.2.15:34108->10.0.2.15:4001) size=4096
10345 16:41:39.539467440 1 (36ae6d09d26e) skydns (4617:1) < read res=271 data=
HTTP/1.1 404 Not Found
[...][...]To the untrained eye, it might look that we have found the issue: a bunch of inefficient calls. But actually this is not true. If we look at the timestamps, the difference between the first etcd request (10097) and the last one (10479), the timestamps in the second column are less than 10ms apart. We are looking at an issue of seconds, not milliseconds – so where is the wait then?When we keep looking through the capture file, we can see that curl doesn't stop trying with DNS queries to SkyDNS, now with backend.critical-app.svc.cluster.local.localdomain (10703). This .localdomain is not recognized by SkyDNS as an internal domain for Kubernetes so instead of going to etcd for service discovery, it decides to forward this query to its upstream DNS resolver (10691).
10396 16:41:39.539686075 0 client (b3a718d8b339) curl (22370:13) < connect res=0 tuple=172.17.0.7:40788->10.0.2.15:53
10418 16:41:39.539755453 0 (36ae6d09d26e) skydns (17280:11) < recvmsg res=70 size=70 data=
backendcritical-appsvcclusterlocalclusterlocal tuple=::ffff:172.17.0.7:40788->:::53
10433 16:41:39.539800679 0 (36ae6d09d26e) skydns (17280:11) > recvmsg fd=6(<3t>:::53)
10434 16:41:39.539802549 0 (36ae6d09d26e) skydns (17280:11) < recvmsg res=70 size=70 data=
backendcritical-appsvcclusterlocalclusterlocal tuple=::ffff:172.17.0.7:40788->:::53
10437 16:41:39.539805177 0 (36ae6d09d26e) skydns (17280:11) > recvmsg fd=6(<3t>:::53)
10478 16:41:39.540166087 1 (36ae6d09d26e) skydns (4639:8) > write fd=3(<4t>10.0.2.15:34108->10.0.2.15:4001) size=204
10479 16:41:39.540183401 1 (36ae6d09d26e) skydns (4639:8) < write res=204 data=
GET /v2/keys/skydns/local/cluster/local/cluster/svc/critical-app/backend?quorum=false&recursive=true&sorted=false HTTP/1.1
Host: 10.0.2.15:4001
User-Agent: Go 1.1 package http
Accept-Encoding: gzip
10523 16:41:39.540421040 1 (36ae6d09d26e) skydns (4617:1) > read fd=3(<4t>10.0.2.15:34108->10.0.2.15:4001) size=4096
10524 16:41:39.540422241 1 (36ae6d09d26e) skydns (4617:1) < read res=267 data=
HTTP/1.1 404 Not Found
[...][...]Scanning down the timestamp column we see the first large gap when SkyDNS sends out a request and then hangs for about 4 seconds (10718-58215). Given that .localdomain is not a valid TLD (top level domain), the upstream server will be just ignoring this request. After the timeout, SkyDNS tries again with the same query (75923), hanging for another few more seconds (75927-104208). In total we have been waiting around 8 seconds for a DNS entry that doesn't exist and is being ignored.
10690 16:41:39.541376928 1 (36ae6d09d26e) skydns (4639:8) > connect fd=8(<4>)
10691 16:41:39.541381577 1 (36ae6d09d26e) skydns (4639:8) < connect res=0 tuple=10.0.2.15:44249->8.8.8.8:53
10702 16:41:39.541415384 1 (36ae6d09d26e) skydns (4639:8) > write fd=8(<4u>10.0.2.15:44249->8.8.8.8:53) size=68
10703 16:41:39.541531434 1 (36ae6d09d26e) skydns (4639:8) < write res=68 data=
Nbackendcritical-appsvcclusterlocallocaldomain
10717 16:41:39.541629507 1 (36ae6d09d26e) skydns (4639:8) > read fd=8(<4u>10.0.2.15:44249->8.8.8.8:53) size=512
10718 16:41:39.541632726 1 (36ae6d09d26e) skydns (4639:8) < read res=-11(EAGAIN) data=
58215 16:41:43.541261462 1 (36ae6d09d26e) skydns (4640:9) > close fd=7(<4u>10.0.2.15:54272->8.8.8.8:53)
58216 16:41:43.541263355 1 (36ae6d09d26e) skydns (4640:9) < close res=0
[...][...]But finally, it all works! Why? curl stops trying to patch things and applying search domains. It tries the domain name verbatim as we typed in the command line. The DNS request is resolved by SkyDNS through the etcd service discovery API request (104406). A connection is opened against the service IP address (107992), then forwarded to the pod with iptables and the HTTP response travels back to the curl container (108024).
58292 16:41:43.542822050 1 (36ae6d09d26e) skydns (4640:9) < write res=68 data=
Nbackendcritical-appsvcclusterlocallocaldomain
58293 16:41:43.542829001 1 (36ae6d09d26e) skydns (4640:9) > read fd=8(<4u>10.0.2.15:56371->8.8.8.8:53) size=512
58294 16:41:43.542831896 1 (36ae6d09d26e) skydns (4640:9) < read res=-11(EAGAIN) data=
75904 16:41:44.543459524 0 (36ae6d09d26e) skydns (17280:11) < recvmsg res=68 size=68 data=
[...]
75923 16:41:44.543560717 0 (36ae6d09d26e) skydns (17280:11) < recvmsg res=68 size=68 data=
Nbackendcritical-appsvcclusterlocallocaldomain tuple=::ffff:172.17.0.7:47441->:::53
75927 16:41:44.543569823 0 (36ae6d09d26e) skydns (17280:11) > recvmsg fd=6(<3t>:::53)
104208 16:41:47.551459027 1 (36ae6d09d26e) skydns (4640:9) > close fd=7(<4u>10.0.2.15:42126->8.8.8.8:53)
104209 16:41:47.551460674 1 (36ae6d09d26e) skydns (4640:9) < close res=0
[...][...]Looking at how things operate at the system level we can conclude that there are two different issues as the root cause of this problem. First, curl doesn't trust me when I give it a FQDN and tries to apply a search domain algorithm. Second, .localdomain should have never been there because it's not routable within our Kubernetes cluster.If for a second you thought this could have been done using tcpdump, you haven't tried yourself yet. I'm 100% sure is not going to be installed inside your container. You can run it outside from the host, but good luck finding the network interface matching the network namespace of the container that Kubernetes scheduled. If you don't buy me, keep reading: we are not done with the troubleshooting yet.
104406 16:41:47.552626262 0 (36ae6d09d26e) skydns (4639:8) < write res=190 data=
GET /v2/keys/skydns/local/cluster/svc/critical-app/backend?quorum=false&recursive=true&sorted=false HTTP/1.1
[...]
104457 16:41:47.552919333 1 (36ae6d09d26e) skydns (4617:1) < read res=543 data=
HTTP/1.1 200 OK
[...]
{"action":"get","node":{"key":"/skydns/local/cluster/svc/critical-app/backend","dir":true,"nodes":[{"key":"/skydns/local/cluster/svc/critical-app/back
end/6ead029a","value":"{"host":"10.3.0.214","priority":10,"weight":10,"ttl":30,"targetstrip":0}","modifiedIndex":270,"createdIndex":270}],
"modifiedIndex":270,"createdIndex":270}}
[...]
107992 16:41:48.087346702 1 client (b3a718d8b339) curl (22369:12) < connect res=-115(EINPROGRESS) tuple=172.17.0.7:36404->10.3.0.214:80
108002 16:41:48.087377769 1 client (b3a718d8b339) curl (22369:12) > sendto fd=3(<4t>172.17.0.7:36404->10.3.0.214:80) size=102 tuple=NULL
108005 16:41:48.087401339 0 backend-1440326531-csj02 (730a6f492270) nginx (7203:6) < accept fd=3(<4t>172.17.0.7:36404->172.17.0.5:80) tuple=172.17.0.7:36404->172.17.0.5:80 queuepct=0 queuelen=0 queuemax=128
108006 16:41:48.087406626 1 client (b3a718d8b339) curl (22369:12) < sendto res=102 data=
GET / HTTP/1.1
[...]
108024 16:41:48.087541774 0 backend-1440326531-csj02 (730a6f492270) nginx (7203:6) < writev res=238 data=
HTTP/1.1 200 OK
Server: nginx/1.10.2
[...]
Part 2: Kubernetes troubleshooting: DNS resolution
Let's have a look at what's in the resolv.conf file. The container could be gone already, or the file could have changed after the curl call. But we have a sysdig capture that contains everything that happened.Usually containers live as long as the process running inside them, disappearing when that process dies. This is one of the most challenging parts of troubleshooting containers. How we can explore something that's gone already? How we can reproduce exactly what happened? Sysdig capture files come extremely useful in these cases.Let's analyze the capture file but instead of filtering the network traffic, we will filter on that file this time. We want to see resolv.conf exactly as it was read by curl, to confirm what we thought, it contains the localdomain.$ sysdig -pk -NA -r capture.scap -c echo_fds "fd.type=file and fd.name=/etc/resolv.conf"Here's a new way to use sysdig:
------ Read 119B from [k8s_client.eee910bc_client_critical-app_da587b4d-bd5a-11e6-8bdb-028ce2cfb533_bacd01b6] [b3a718d8b339] /etc/resolv.conf (curl)
search critical-app.svc.cluster.local svc.cluster.local cluster.local localdomain
nameserver 10.0.2.15
options ndots:5
[...]-c echo_fds uses a Sysdig chisel – an add-on script – to aggregate the information and to format the output. Also the filter includes only IO activity on file descriptors that are a file and with the name /etc/resolv.conf, exactly what we are looking for.Through the syscalls, we see there is an option called ndots. This option is the reason why curl didn't trust our FQDN (fully qualified domain name) but tried to append all the search domain first. If you read the manpage, ndots forces libc that any resolution on a domain name with less than 5 dots won't be treated as a fqdn but will try to first append all the search domains. ndots is there for a good reason, so we can perform a curl backend. But who added localdomain there?
Part 3: Kubernetes troubleshooting: containers run by Docker
We don't want to finish our troubleshooting without finding the culprit for this localdomain. That way, we can blame software and not people :) Was Docker who added that search domain? Or Kubernetes instructing Docker when creating the container?Since we know that all control communication between Kubernetes and Docker is done through a Unix socket, we can use that to filter things out:$ sudo sysdig -pk -s8192 -c echo_fds -NA "fd.type in (unix) and evt.buffer contains localdomain"This time we will be capturing live with the help of an awesome filter, evt.buffer contains. This filter takes all the events buffers and if it contains the string we are looking for, will be considered for printing by our chisel that formats the output.Now I need to create a new client to spy on what happens at container orchestration time:$ kubectl run -it --image=tutum/curl client-foobar --namespace critical-app --restart=NeverI can see that hyperkube, which is part of Kubernetes, wrote on /var/run/docker.sock using Docker API an HTTP POST request to /containers/create. If we read through it, we will find how this request contains an option "DnsSearch":["critical-app.svc.cluster.local", "svc.cluster.local", "cluster.local", "localdomain"]. Kubernetes, we caught you!. Most probably it was there for some reason, like my local development machine having that search domain set up. In any case, that's a different story.[...]
------ Write 2.61KB to [k8s-kubelet] [de7157ba23c4] (hyperkube)
POST /containers/create?name=k8s_POD.d8dbe16c_client-foobar_critical-app_085ac98f-bd64-11e6-8bdb-028ce2cfb533_9430448e HTTP/1.1
Host: docker
[...]
"DnsSearch":["critical-app.svc.cluster.local","svc.cluster.local","cluster.local","localdomain"],
[...]
Conclusion
Reproducing exactly what happened inside container can be very challenging as they terminate when the process dies or just ends. Sysdig captures contain all the information through the system calls including network traffic, file system I/O and processes behaviour providing all the data required for troubleshooting.When troubleshooting in a container environment, being able to filter and add container contextual information like Docker container names or Kubernetes metadata makes our lives significantly easier.Sysdig is available in all the main Linux distros, for OSX and also Windows. Download it from here to get the last version. Sysdig is an open source tool but the company behind the project also offers a commercial product to monitor and troubleshoot containers and microservices across multiple hosts.Let's check out the final part of our series, Monitoring Kubernetes at WayBlazer (a use case study).