



Falco Feeds extends the power of Falco by giving open source-focused companies access to expert-written rules that are continuously updated as new threats are discovered.

In the rapidly evolving digital landscape, malicious actors constantly adapt their strategies to infiltrate our systems. Traditional endpoint detection mechanisms are no longer sufficient to protect our applications and workloads against advanced threats. To effectively address this concern, it has become imperative to embrace a broader approach to threat detection. This entails a paradigm shift towards incorporating both agent-based and agentless detection methods.
In this blog post, we explore the concept of expanding the scope of threat detection through the principles of "shift-left" and "shield-right." The "shift-left" approach involves proactively preventing vulnerabilities as early as possible, using tools like vulnerability scanners, posture hardening, and permission management. On the other hand, "shield-right" focuses on real-time detection and response capabilities. While traditional endpoint security agents provide in-depth visibility during runtime, they are inadequate for detecting threats in real time within CI/CD pipelines and cloud environments.
Sysdig offers robust, end-to-end strategies that enable real-time threat detection, not only within the codebase but also across active workloads. By leveraging a versatile plugin architecture, Sysdig empowers developers and security teams to promptly identify and respond to suspicious behaviors as the complexity of their systems evolves.
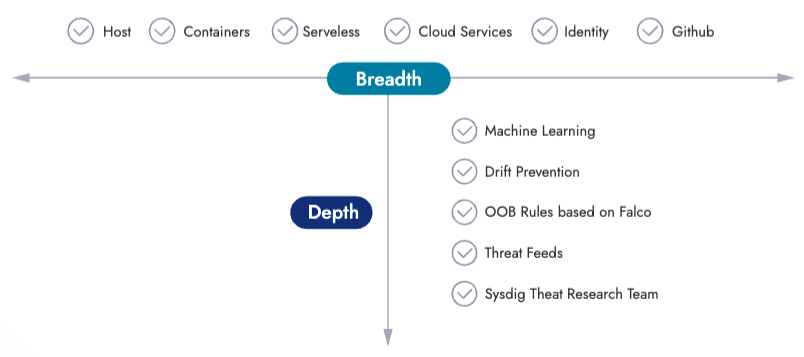
Now let's see how this strategy fits in a holistic approach that spans the entire software development lifecycle, empowering organizations to combat modern threats effectively.
Shift Left
First, let's explore the concept of shift left. This phrase emphasizes the early integration of security practices and detection mechanisms into the development lifecycle.
By embedding security controls and policies into the earliest stages of the software development process, potential vulnerabilities and malicious activities can be proactively identified and mitigated before they become significant threats. Many industry personnel will believe that the only concepts worth discussing at this stage are image signing and image scanning (for the most part).
And this is absolutely necessary!
This approach aims to address the existing security limitations, while organizations tend to focus excessively on code misconfiguration in code repositories, often overlooking more apparent threats like accidental data exposure.
One prevalent form of data exposure occurs when developers inadvertently push sensitive credentials, such as passwords and tokens, into publicly accessible repositories. Consequently, any developer, intended or not, could gain access to these secrets. Although this may be acceptable within a private repository limited to internal contributors/employees, the situation becomes precarious if the repository is accidentally changed from "Private" to "Public."
In such scenarios, Sysdig's agentless GitHub detections play a vital role of promptly detecting suspicious behaviors, enabling security teams to mitigate the risks associated with accidental data leaks. While we strongly recommend practices such as code scanning, image signing, and other shift-left methodologies, it is important to acknowledge that these tools, including traditional agent-based security solutions, cannot provide the necessary detection capabilities required for effective incident response in third-party platforms.
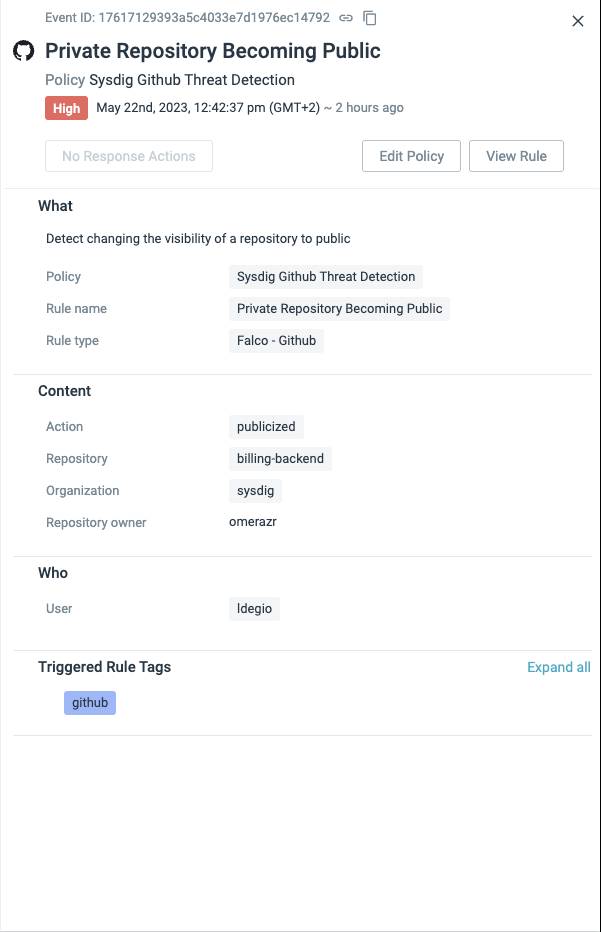
Sysdig goes beyond the open source Falco project by extending the capabilities of the GitHub plugin. This extension allows Sysdig to provide agentless detection rules in the familiar YAML format, which aligns with the expectations we have developed for Sysdig and Falco detection rules. By building upon Falco's foundation, Sysdig enables us to understand the underlying logic of the detection rules and easily customize them to suit our specific requirements.
- rule: Private Repository Becoming Public
desc: Detect changing the visibility of a repository to public
condition: github.type=repository and github.action=publicized
output: A repository went from private to public (repository=%github.repo
repo_owner=%github.owner org=%github.org user=%github.user)
priority: CRITICAL
source: githubShield Right
Now, let's shift our focus to the utilization of Kubernetes audit logs as a means to detect unwanted user activity within the Kubernetes environment. In the realm of shield right, Sysdig offers an innovative approach that extends threat detection beyond the development phase and into the live environment.
With shield right, organizations can benefit from Sysdig's continuous monitoring and analysis of running workloads. This empowers them to effectively identify and respond to real-world, end-to-end threats. We have previously explored how the dynamic and customizable threat detection rules within the Falco plugin architecture enable organizations to adapt to evolving threats and safeguard their systems against emerging attack vectors.
Sysdig and open source Falco are capable of detecting container and host activity based on system calls. For instance, we can observe real-time container deletions. However, this information alone lacks important context. It becomes crucial to ascertain whether a container was manually deleted or if it was part of an orchestration solution like Kubernetes. Furthermore, it is essential to determine whether the deletion of a container was associated with the deletion of its hosting pod, or if it resulted from changes in other abstraction layers, such as deployment or namespace modifications.
Sysdig's plugin architecture is not limited to agentless detection capabilities. Specifically, the Kubernetes plugin is designed to handle real-time events from the Kubernetes Audit logs, which provide invaluable context for shield-right detections. Let's illustrate this with an example:
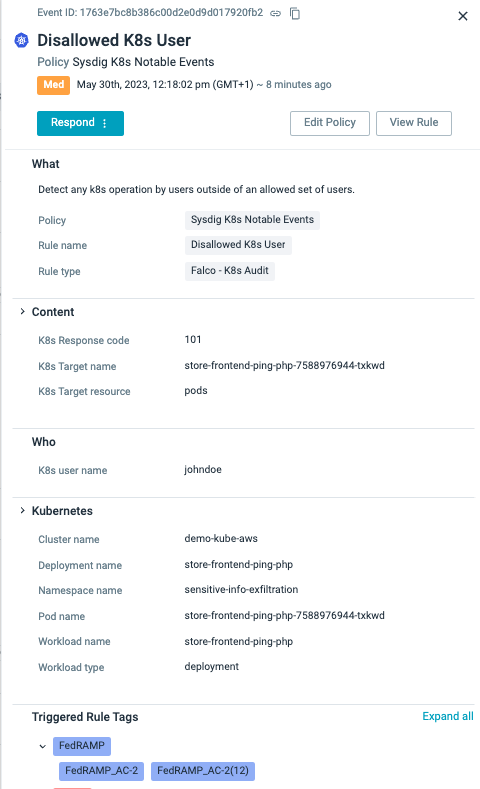
- rule: Disallowed K8s User
desc: Detect any k8s operation by users outside of an allowed set of users.
condition: kevt and non_system_user and not ka.user.name in (allowed_k8s_users) and not ka.user.name in (eks_allowed_k8s_users)
output: K8s Operation performed by user not in allowed list of users (user=%ka.user.name target=%ka.target.name/%ka.target.resource verb=%ka.verb uri=%ka.uri resp=%ka.response.code)
priority: WARNING
source: k8s_auditInstead of fixating solely on individual container IDs, which pose challenges in tracing due to the transient nature of containerization, our approach shifts towards monitoring the Kubernetes Audit logs to detect unwanted user and container activity. By analyzing these logs, we can track deployment changes and gain insights into the responsible party behind each change. This information, when correlated with real-time container context, enables us to differentiate between malicious and benign behavior. The inclusion of Kubernetes context through audit logs greatly enhances our understanding of the precise reasons behind the deletion and recreation of these workloads, empowering us to identify and address unwanted user actions effectively.
Identity Providers
Security shouldn't remain at just shift-left and shield-right ideology. Identity services, like Okta, are great for adding additional levels of security through Multi-Factor Authentication (MFA). As stated in the shield-left section, if a private repository housing sensitive credentials, such as Secrets, was accidentally or maliciously made public, how long would it take for your security team to be made aware of this data leak?
Similarly, if this adversary were to log into your IdP provider using stolen credentials from that repository, what is your current business strategy to detect this suspicious behavior? If you don't believe this is a real threat, on Oct. 7, 2022, the Japanese-based automotive manufacturer Toyota revealed it had accidentally exposed a credential allowing access to customer data in a public GitHub repo for nearly five years.
Thankfully, all these services tend to generate relevant real-time event streams for their activity. The hard part is knowing how to handle those events, and trigger alerts with the relevant content in real time.
Thankfully, Sysdig has a plugin for this!
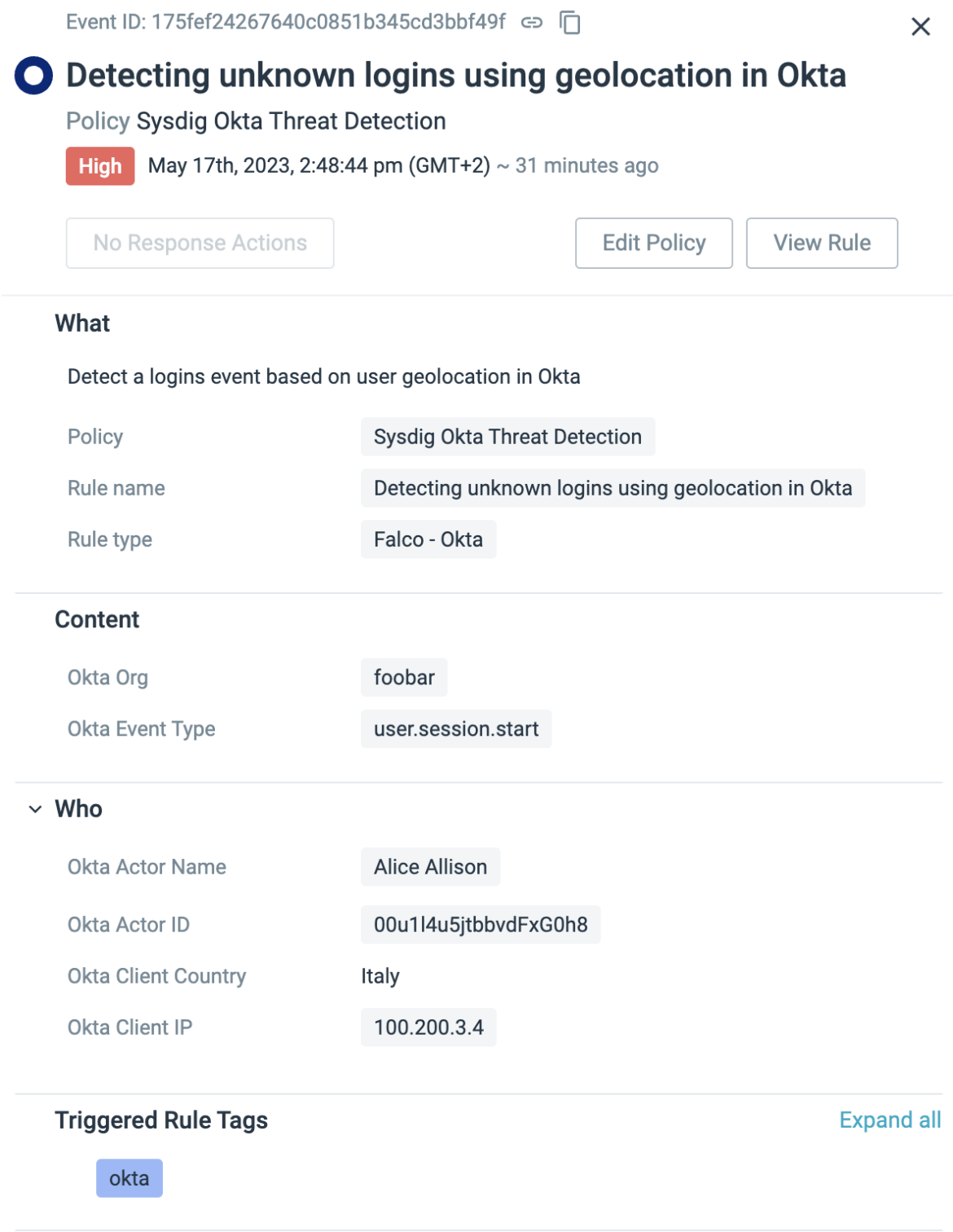
Similar to the unwanted user activity rule for Kubernetes, we have implemented a detection mechanism to identify unknown logins originating from IP addresses or regions that are not recognized for Okta logins. By creating a whitelist that includes countries such as Ireland, Malta, and Spain, any login attempt from a different country would be flagged as suspicious.
- rule: Detecting unknown logins using geolocation in Okta
desc: Detect a logins event based on user geolocation
condition: okta.evt.type = "user.session.start" and not user_known_countries
output: "A user logged in OKTA from a suspicious country
(user=%okta.actor.name, ip=%okta.client.ip, country=%okta.client.geo.country)"
priority: NOTICE
source: okta
tags: [mitre_defense_evasion]
With objects such as Macros and Lists, security teams can easily whitelist countries we are expecting to see Okta logins from, with no need for modifying the rule itself. This way, we can push consistent rules from staging to production and only modify list items for unique environments.
- macro: user_known_countries
condition: (okta.client.geo.country in (allowed_countries_list))
- list: allowed_countries_list
items: [ireland, malta, spain]Data Enrichment with Plugins
Real-time alerts are not enough for preventing end-to-end software threats. To really understand the root cause of an issue and respond in a timely fashion, we need to stitch our metadata context across the stack.
Falco and Sysdig achieve this through a sophisticated data enrichment engine.
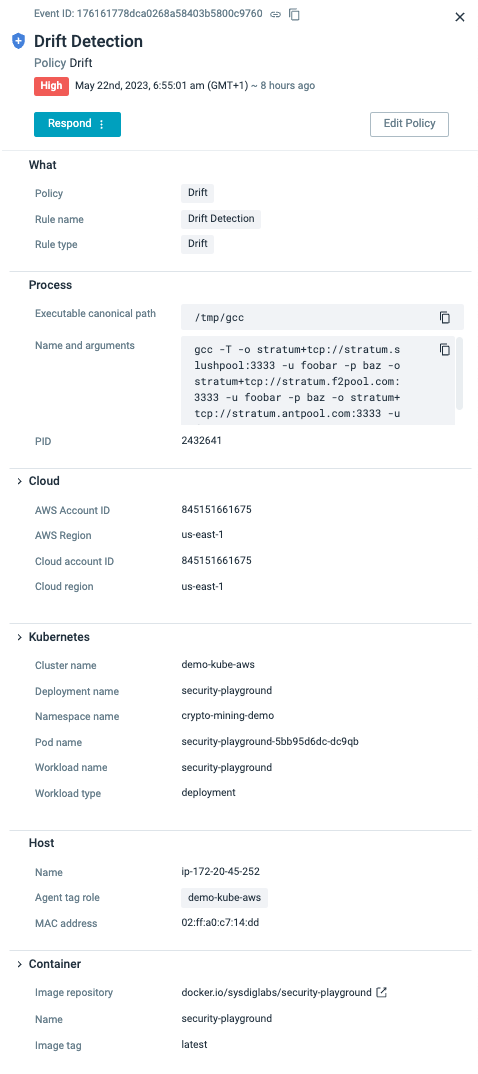
As mentioned earlier, plugins allow us to handle streamed events from different sources. However, plugins can also extend the incident response capabilities by defining new fields to describe how to use these new data sources. As you can see from the below screenshot, a simple drift detection policy has the Output context from the process, container, and host through system calls.
Already, we are seeing three examples of data sources where context is enriched. Through the plugin architecture, we can also enrich the alert with metadata context from the Kubernetes Audit logs stream, the Cloud audit logging service (in this case AWS CloudTrail), as well as the Identity Providers like Okta.
What information you choose to expose in the rule Output is entirely up to you. For example, here is a rule designed for detecting Execute Interactive Command inside an ECS Container. The output content is what we see in the alert. Of course, the more context we can cram into these rules, the better. Granted, it doesn't impact the performance of the rules engine. That's why we offer customization to the end-user with these alert outputs.
- rule: Execute Interactive Command inside an ECS Container
desc: Detect execution of an interactive command inside an ECS container.
condition: >-
aws.eventSource="ecs.amazonaws.com" and aws.eventName="ExecuteCommand" and
not jevt.value[/requestParameters/command] in (system_shells) and
jevt.value[/requestParameters/interactive]=true and not aws.errorCode exists
output: >-
An interactive command has been executed inside an ECS container (requesting
user=%aws.user, requesting IP=%aws.sourceIP, AWS region=%aws.region,
cluster=%jevt.value[/requestParameters/cluster],
container=%jevt.value[/requestParameters/container],
command=%jevt.value[/requestParameters/command],
priority: critical
source: aws_cloudtrailAs discussed, data enrichment in Falco and Sysdig refers to the process of providing the rule engine with event metadata obtained by decoding the raw data or collecting it from complementary sources, such as plugins. We can then use this metadata as fields in both rule conditions and the associated output formatting. The product organizes the collected metadata in a set of field classes so you can easily recognize which context they belong to, saving incident responders significant time and effort attempting to stitch together the context.
Conclusion
The need to widen the scope of threat detection has become a critical requirement in today's dynamic cybersecurity landscape. By embracing the shift-left and shield-right approaches offered by Falco's plugin architecture, organizations can detect and respond to suspicious behaviors during development and in live environments. Join us as we explore the practical implementation of these concepts and discover how Sysdig revolutionizes the way we protect our systems from real-world threats.
If you are further interested:
- Learn more about our newest cloud detection and response features in this article.
- Don't miss our webinar: Shift Cloud Security Left and Right with CNAPP, Powered by Runtime Insights.
- To learn more, request a demo.