


Falco Feeds extends the power of Falco by giving open source-focused companies access to expert-written rules that are continuously updated as new threats are discovered.

At Sysdig, we have built a cloud-native intelligence platform to create a single, more effective way to monitor and secure your critical applications. We want to empower our users to quickly identify critical events and focus on events that need the most attention from you.
\r\r
As a result, our product and design teams have spent countless hours understanding how power users are triaging their events and used this learning to design an intuitive, streamlined events workflow. As part of this events workflow, all of your alerts, Docker, Kubernetes and custom events are combined in a single event feed.
\r\r
Feature Overview
\r\r
Event Feed
\r\r
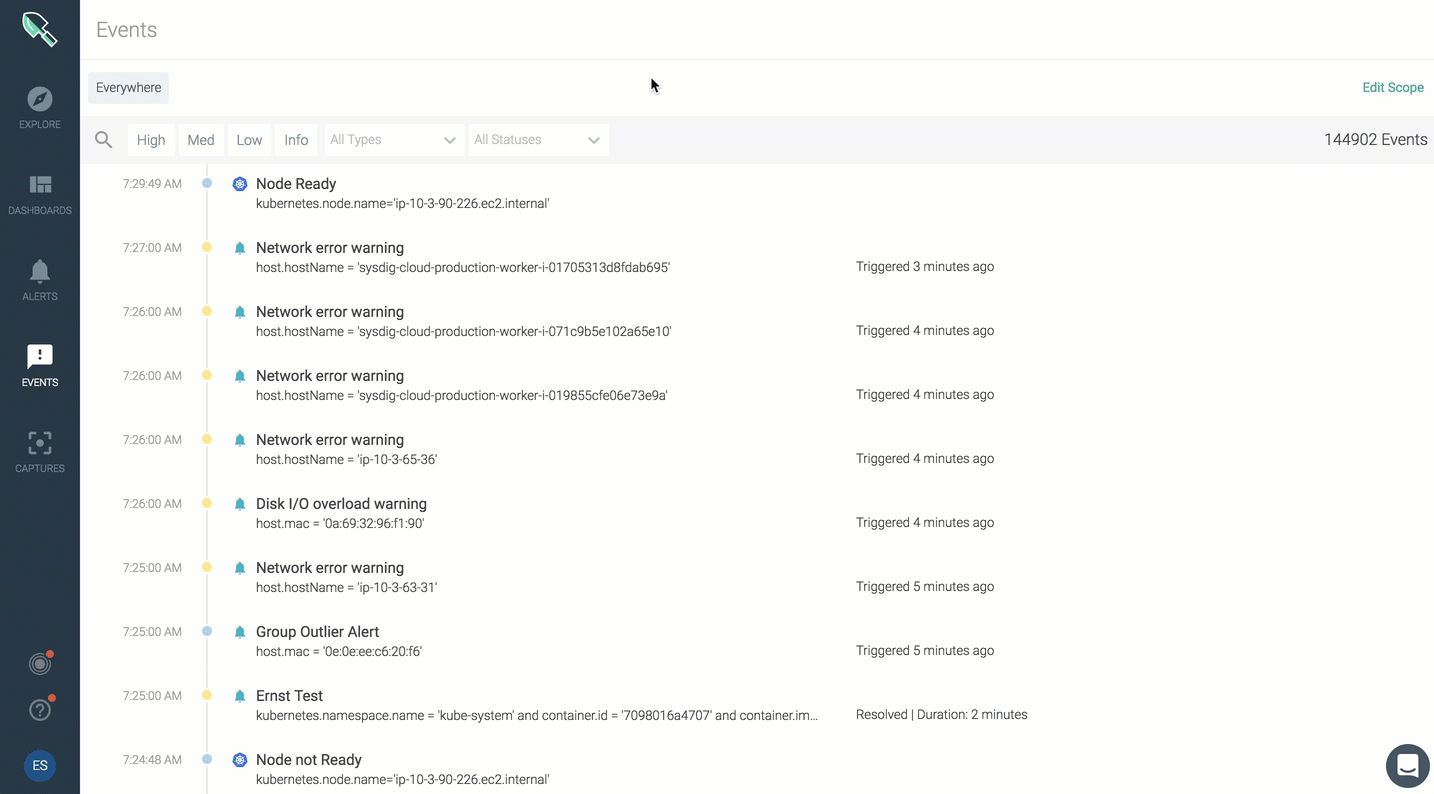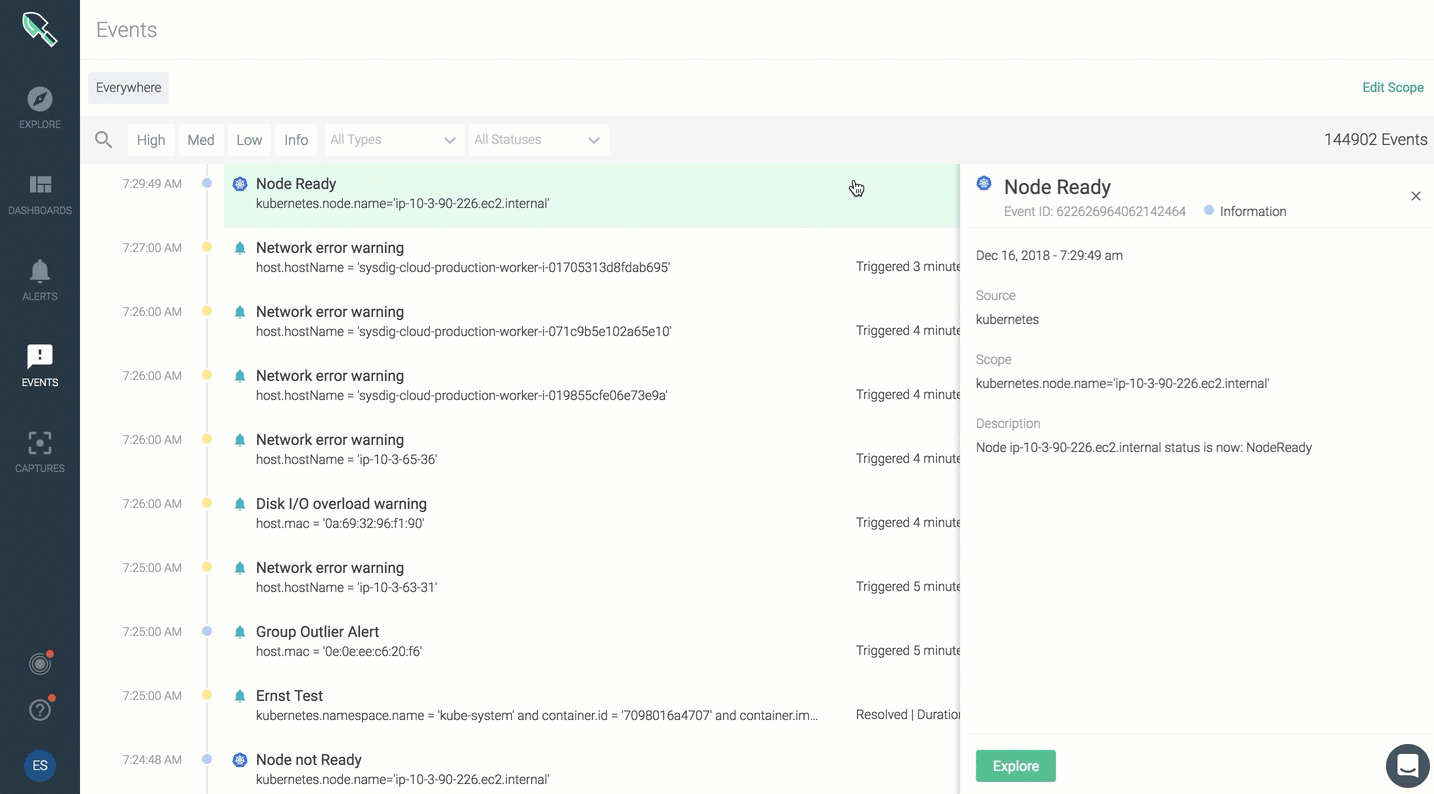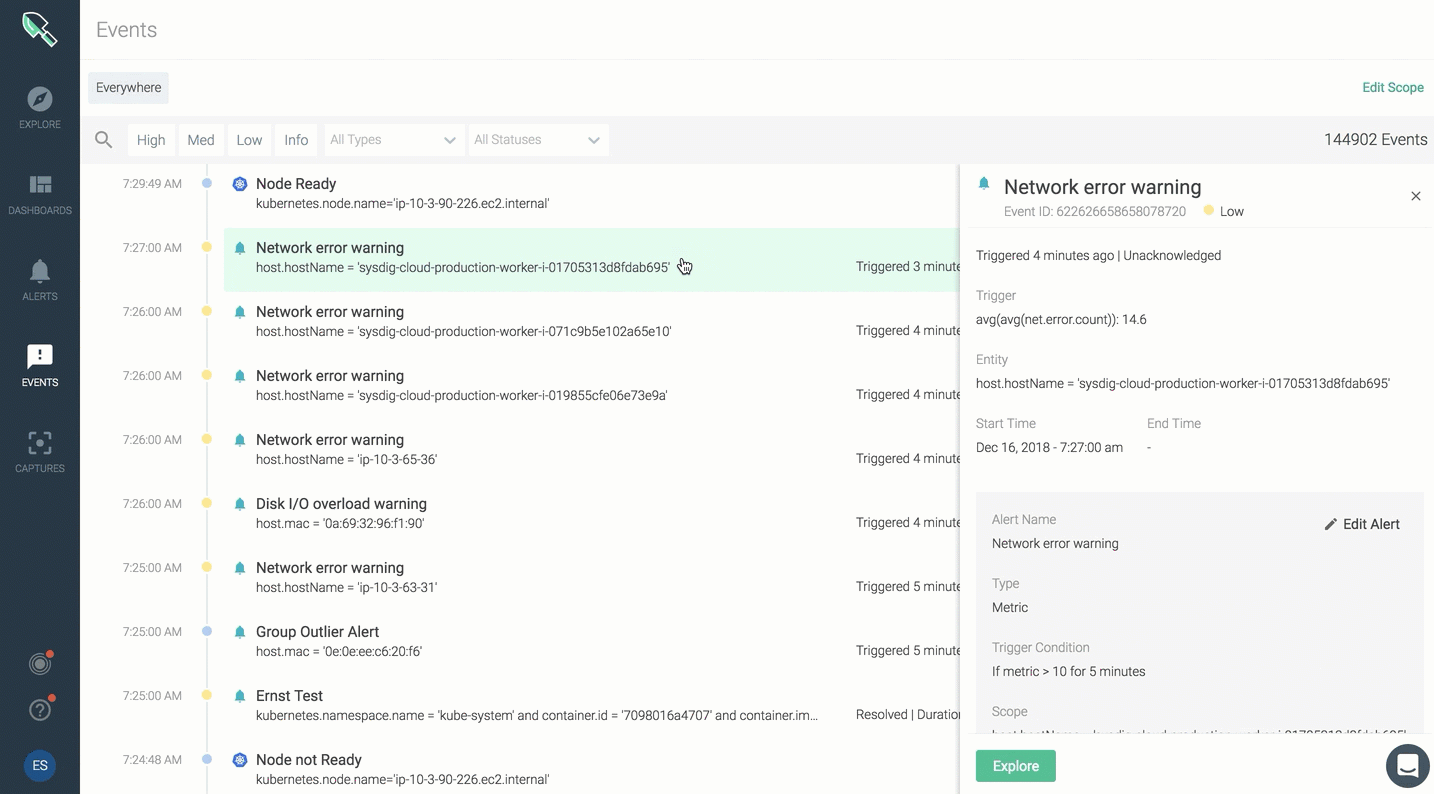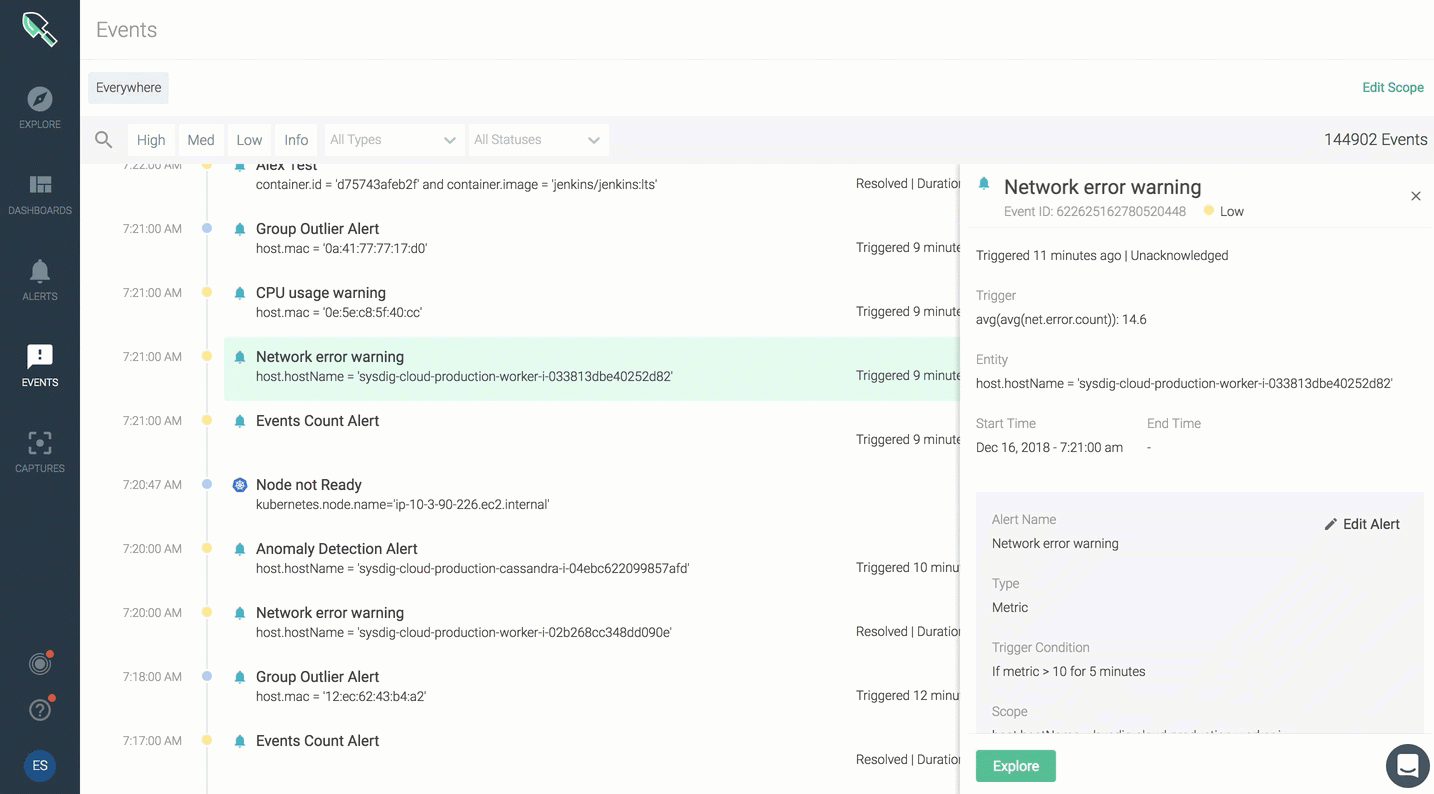
The event feed will provide a summary view of all events. You can click on any event to dig into type, scope, metric, trigger condition, additional details.
\r\r
\r\r
Scope for Events
\r
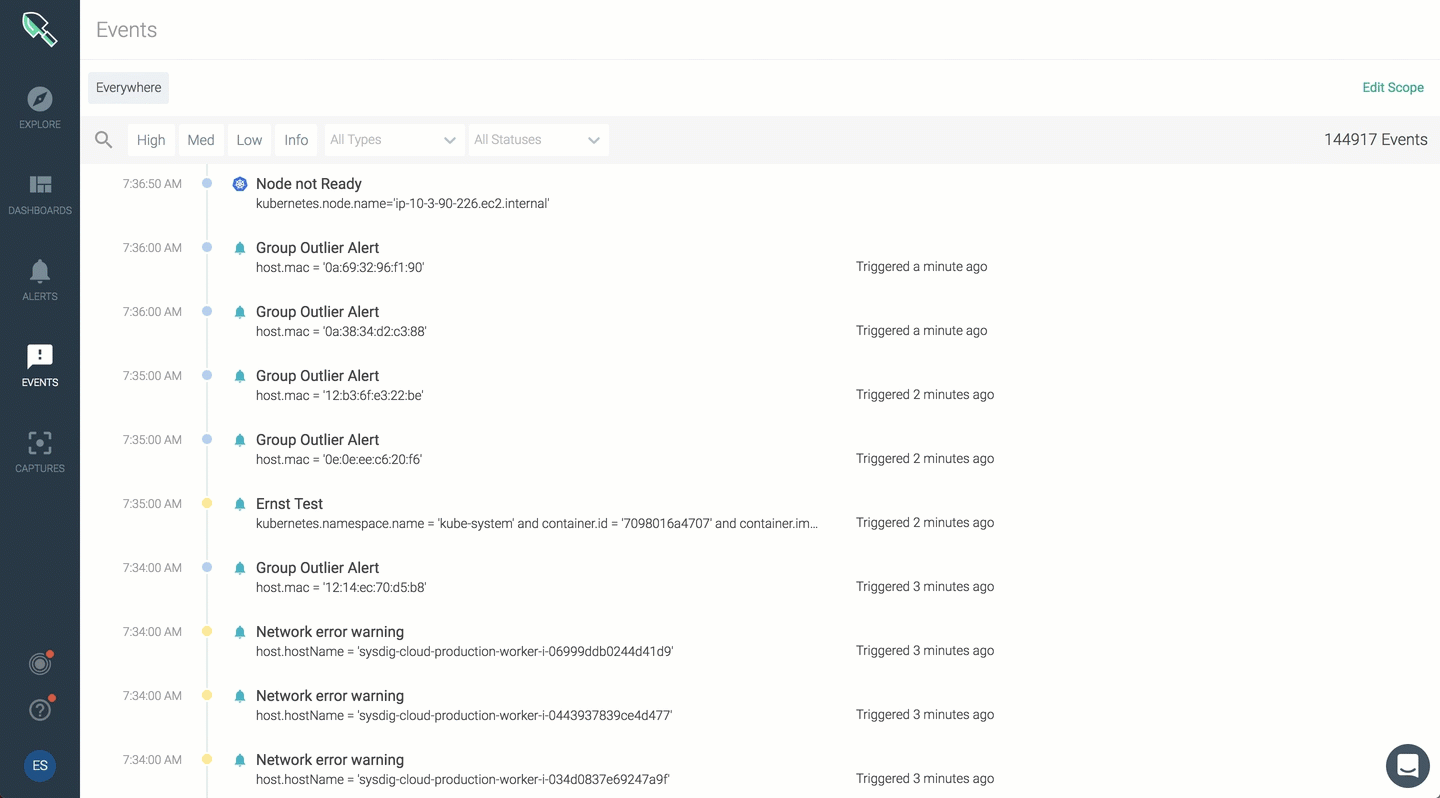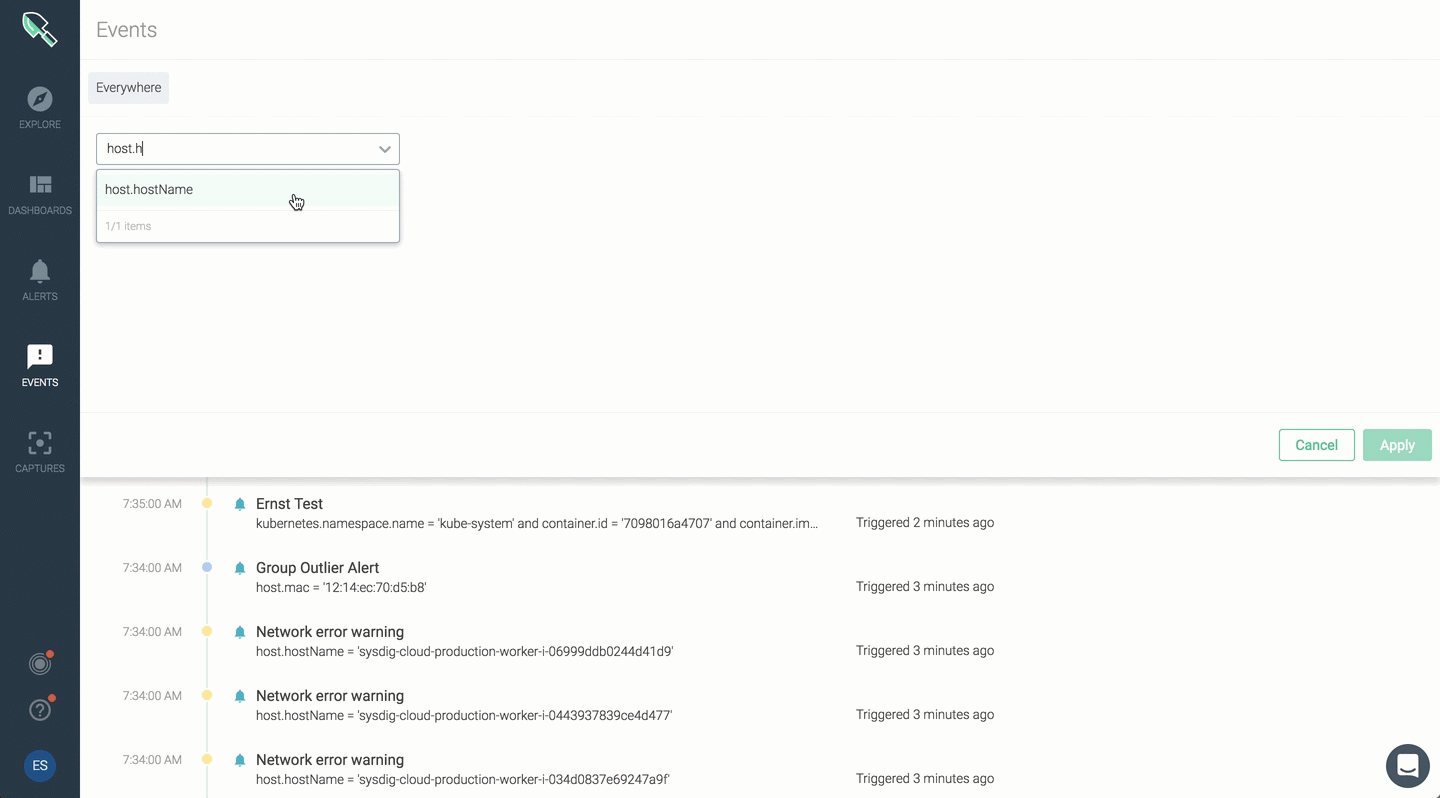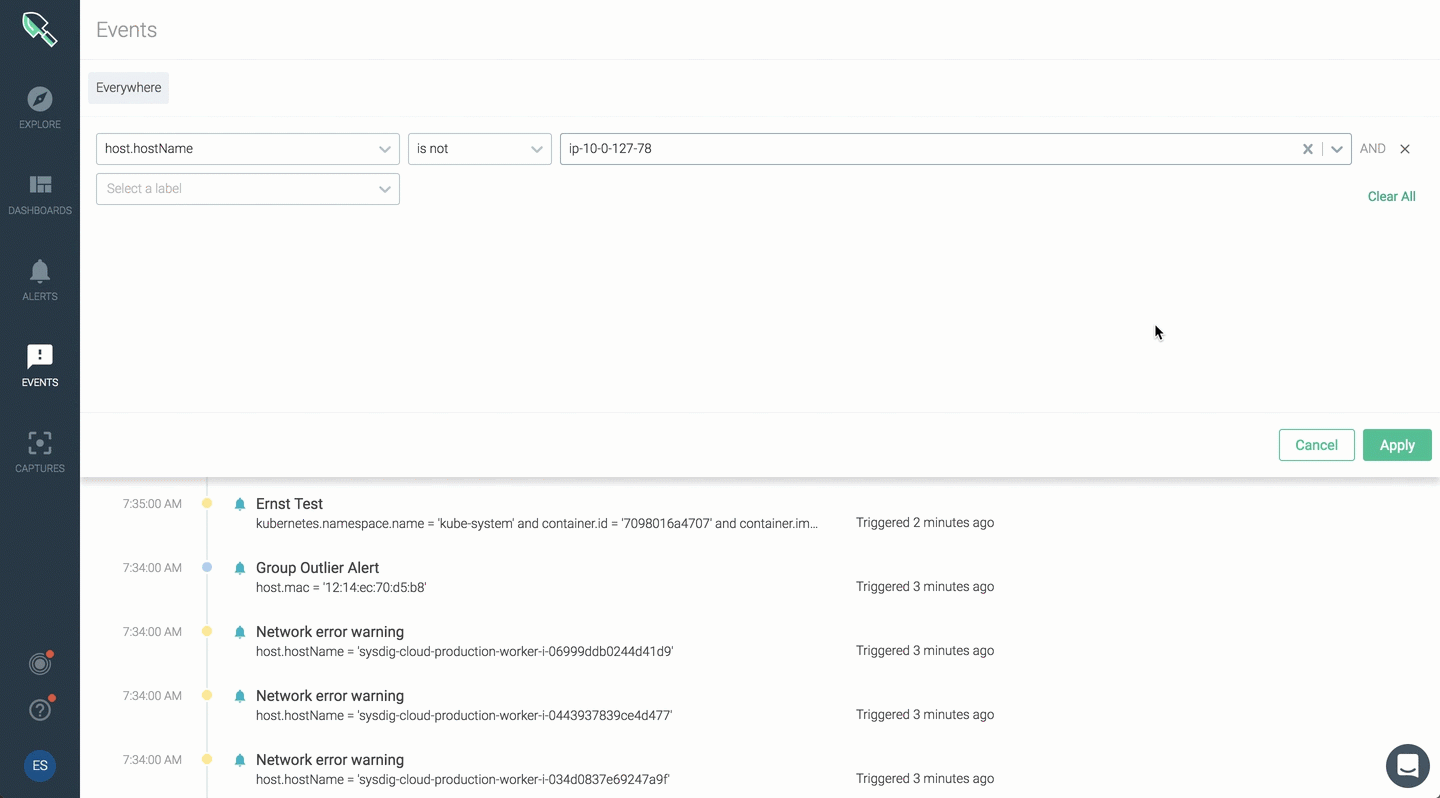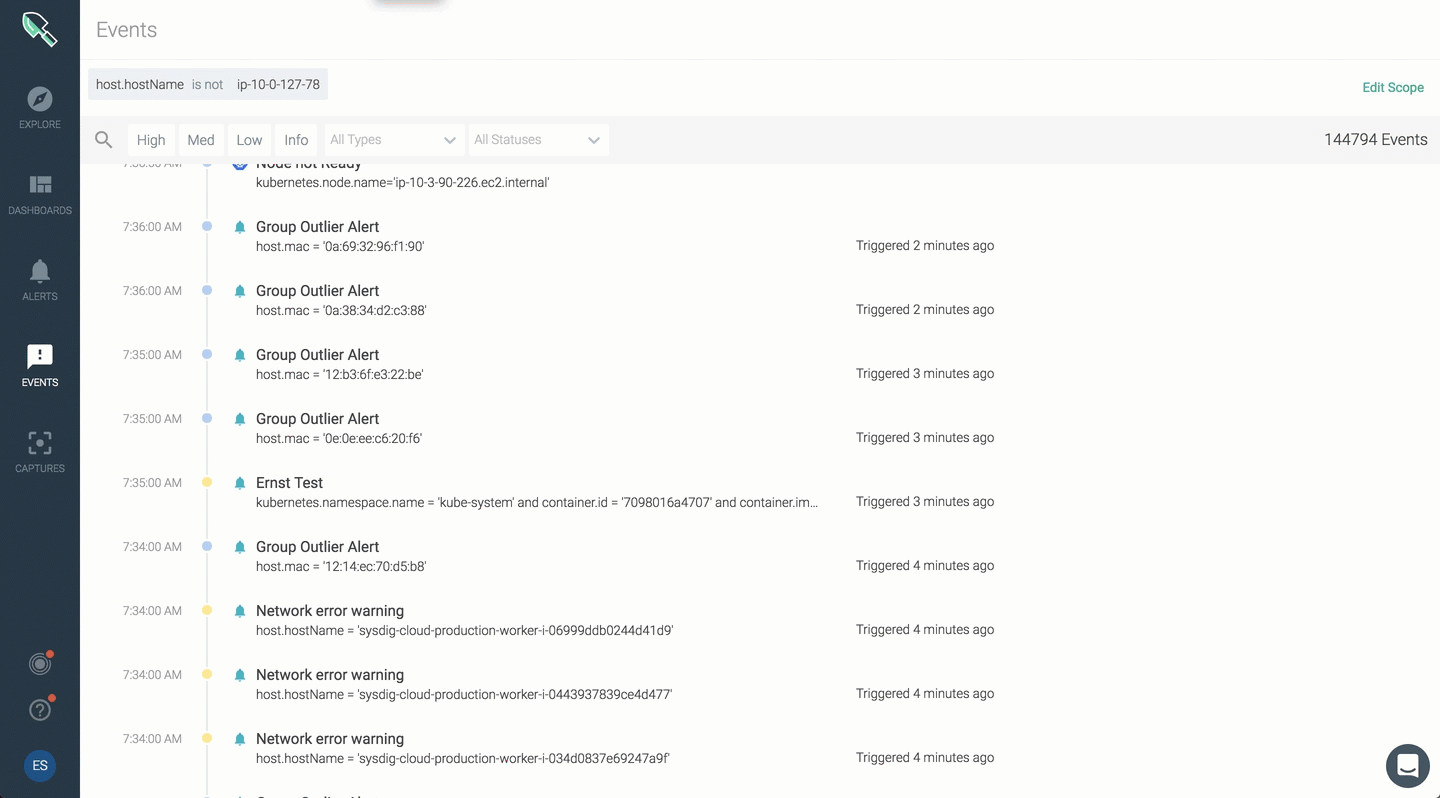
You can now apply scope for your event feed and narrow events for a specific range.
\r\r
\r\r
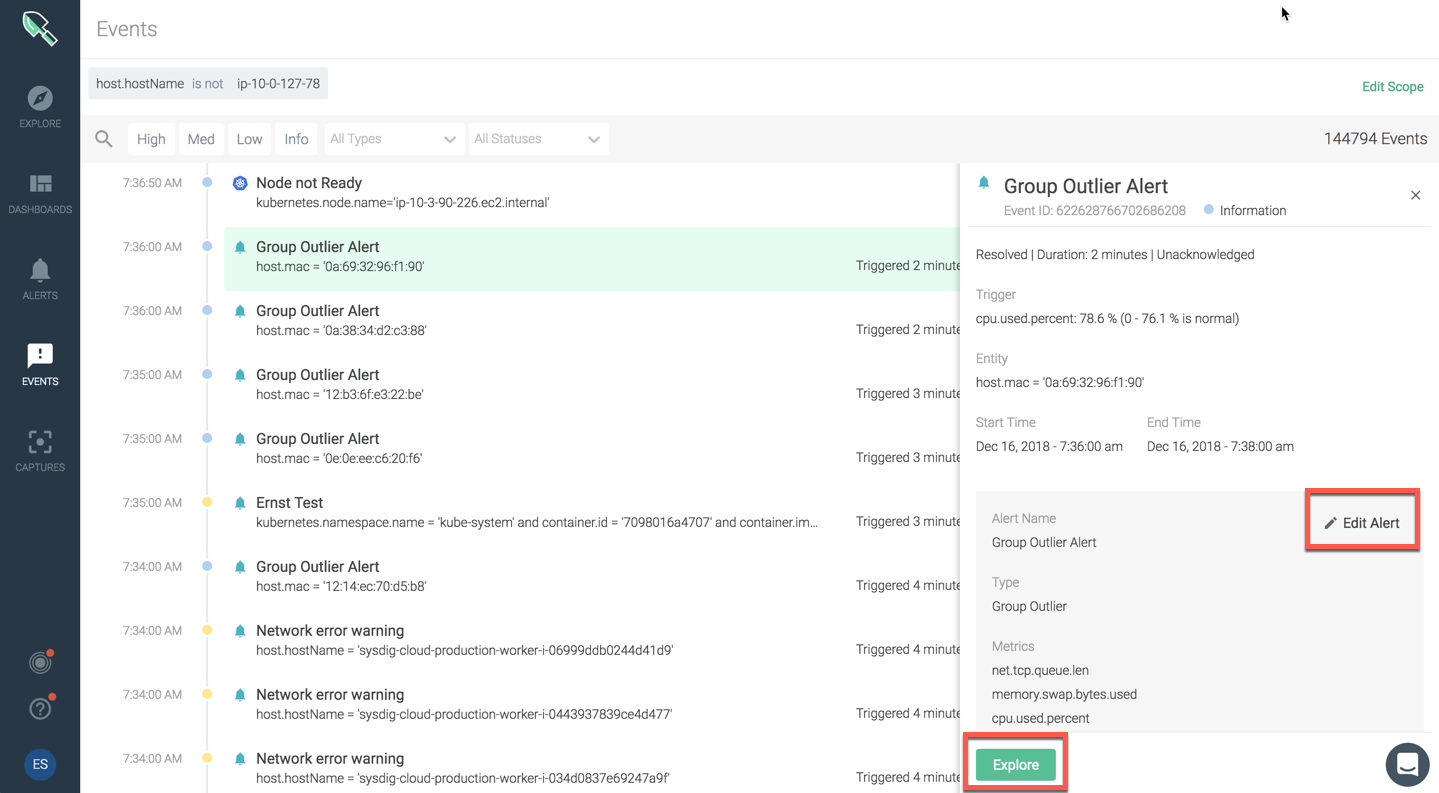
Explore Events
\r\r
For custom events, there is an easy option to create an Alert from the event. You can also open explore to investigate further.
\r\r
\r\r
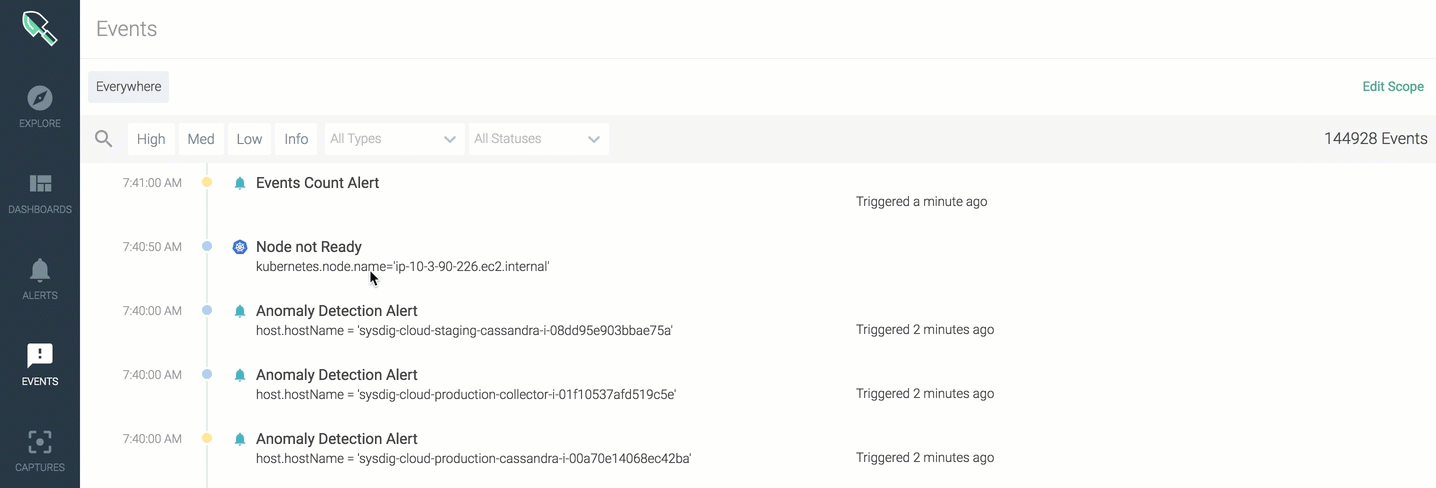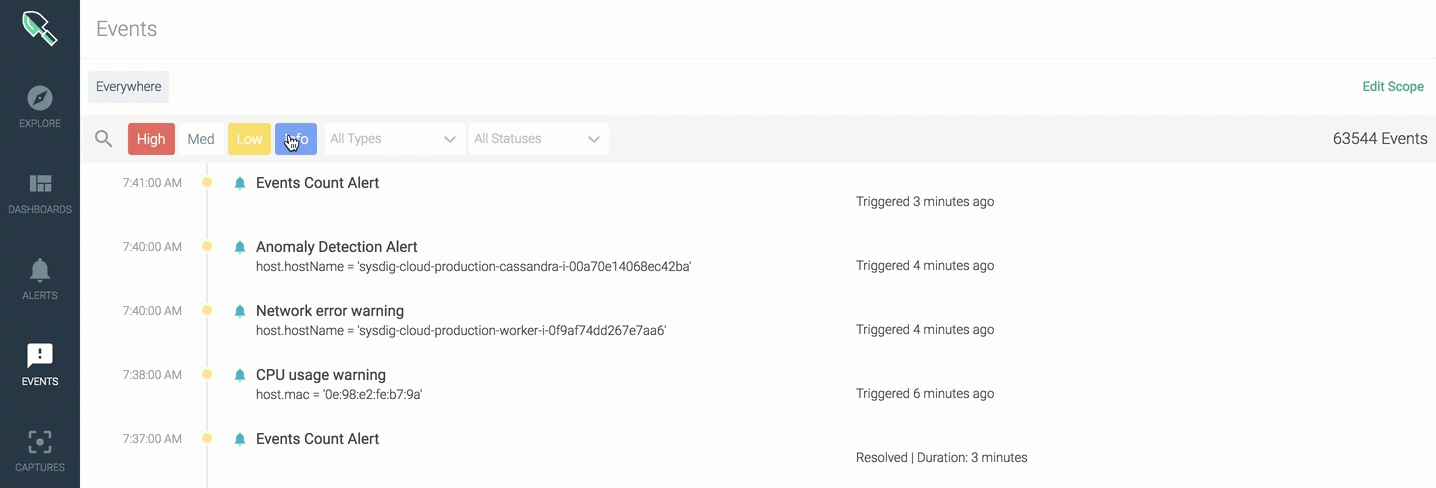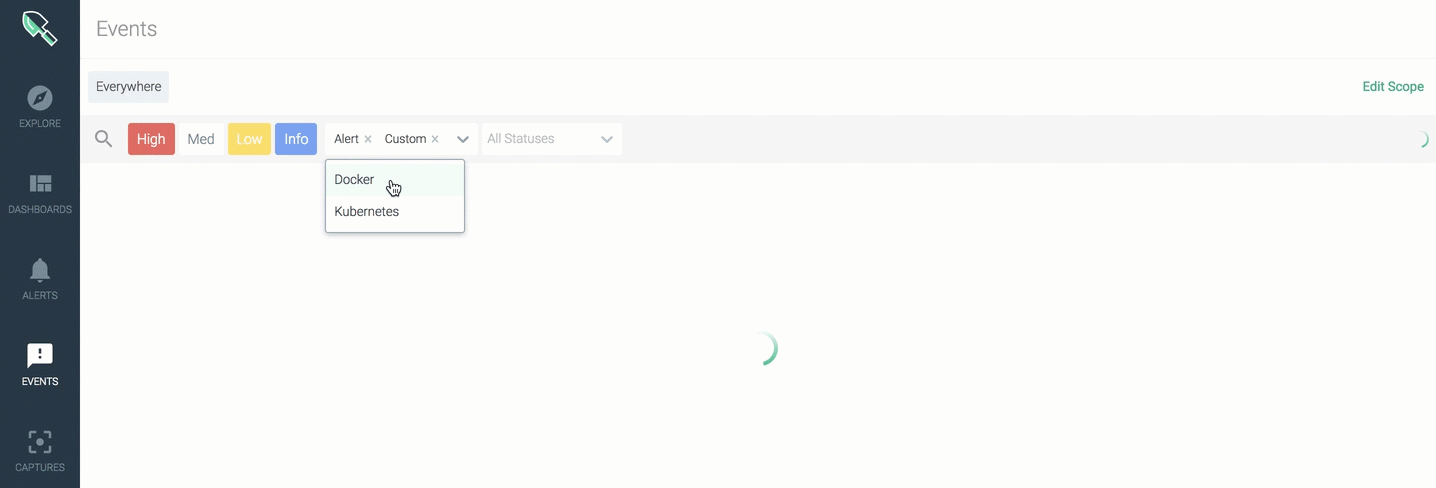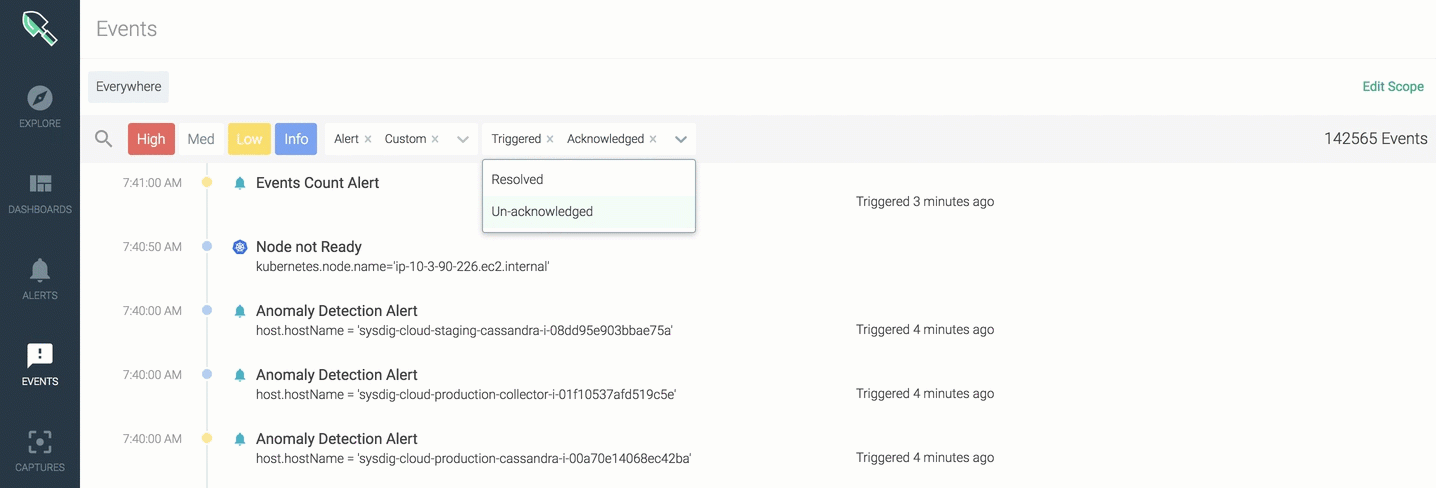
Quick Filters
\r
You can apply quick filters to include any:
\r
Events
\r
- Alert \r
- Custom \r
- Docker \r
- Kubernetes
\r\r
Severity
\r
- High \r
- Medium \r
- Low
\r\r
Status
\r
- Triggered \r
- Resolved \r
- Acknowledged \r
- Unacknowledged
\r\r
\r\r
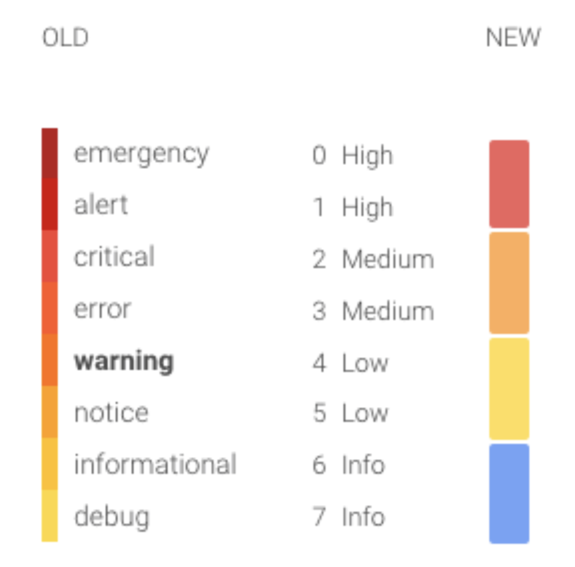
Severity Levels
\r
We have ramped up our thinking around severity levels and wanted to make sure to make it easy for you to monitor/flag these instances based on their severity levels and eliminating any vagueness. We are introducing four new severity levels: High, Medium, Low and Info. Mapping of old to new severity levels is as shown below
\r\r
\r\r
Please Note:
\r\r
If you are using API to query for severity levels, we will continue to respond to the request by sending both old and new severity levels, so your scripts will continue to work as is. API response snippet is shown below:
\r
{\r
…\r
"severity": 5,\r
"severityLabel": "LOW",\r
…\r
}\r
\r\r
We are also renaming statuses for events. When an alert value crosses a threshold, the corresponding alert event will have TRIGGERED status, and when the alert value goes below a threshold, an alert event will transition to RESOLVED status. You can ACKNOWLEDGE/UNACKNOWLEDGED an alert event to help you focus on events that matter the most.
\r\r
These are the first significant set of updates that should help you triage your events more effectively. New events workflows will be available in our December SaaS and OnPrem releases. We will continue to make refinements in the coming months and look forward to your feedback!