



Falco Feeds extends the power of Falco by giving open source-focused companies access to expert-written rules that are continuously updated as new threats are discovered.

Starting the journey for Elasticsearch monitoring is crucial to get the right visibility and transparency over its behavior.
Elasticsearch is the most used search and analytics engine. It provides both scalability and redundancy to provide a high-availability search. As of 2023, more than sixty thousand companies of all sizes and backgrounds are using it as their search solution to track a diverse range of data, like analytics, logging, or business information.
By distributing data in JSON documents and indexing that data into several shards, Elastic search provides high availability, quick search, and redundancy capabilities.
In this article, we will evaluate the most important Prometheus metrics provided by the Elasticsearch exporter.
You will learn what are the main areas to focus on when monitoring an Elasticsearch system:
- Start monitoring Elasticsearch with Prometheus.
- How to monitor Golden Signals.
- How to monitor infra metrics.
- How to monitor index performance.
- How to monitor search performance.
- How to monitor cluster performance.
- Advanced monitoring and next steps
How to start monitoring ElasticSearch with Prometheus
As usual, the easiest way to start your Prometheus monitoring journey with Elasticsearch is to use PromCat.io to find the best configs, dashboards, and alerts. The Elasticsearch setup guide in Promcat includes the Elasticsearch exporter with a series of out-of-box metrics that will be automatically scrapped to Prometheus. It also includes a collection of curated alerts and dashboards to start monitoring Elasticsearch right away.
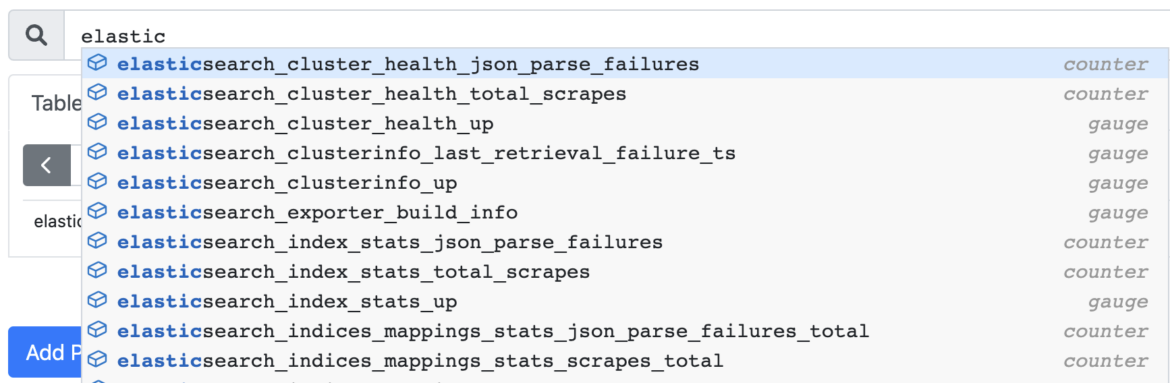
You can combine these metrics with the Node Exporter to get more insights into your infrastructure. Also, if you're running Elasticsearch on Kubernetes, you can use KSM and CAdvisor to combine Kubernetes metrics with Elasticsearch metrics.
How to monitor Golden Signals in Elasticsearch
To review a bare minimum of important metrics, remember to check the so-called Golden Signals:
- Errors.
- Traffic.
- Saturation.
- Latency.
These represent a set of the essential metrics to look for in a system, in order to track black-box monitoring (focus only on what's happening in the system, not why). In other words, Golden Signals will measure symptoms, not solutions to the current problem. This could be a good starting point for creating an Elasticsearch monitoring dashboard.
Errors
elasticsearch_cluster_health_status
Cluster health in Elasticsearch is measured by the colors green, yellow, and red, as follows:
- Green: Data integrity is correct, no shard is missing.
- Yellow: There's at least one shard missing, but data integrity can be preserved due to replicas.
- Red: A primary shard is missing or unassigned, and there's a data loss.
With elasticsearch_cluster_health_status, you can quickly check the current situation for Elasticsearch data on a particular cluster. Remember that this won't retrieve the actual causes of the data integrity loss, just that you need to act in order to prevent further problems.
Traffic
elasticsearch_indices_search_query_total
This metric is a counter with the total number of search queries executed, which by itself won't give you much information as a number.
Consider as well using rate() or irate(), to detect sudden changes or spikes in traffic. Dig deeper into Prometheus queries with our Getting started with PromQL guide
Saturation
For a detailed latency analysis, check the section on How to monitor Elasticsearch infra metrics.
Latency
For a detailed latency analysis, check the section on How to monitor Elasticsearch index performance.
How to monitor Elasticsearch infra metrics
Infrastructure monitoring focuses on tracking the overall performance of the servers and nodes of a system. As with similar cloud applications, most of the effort will be spent on monitoring CPU and Memory consumption.
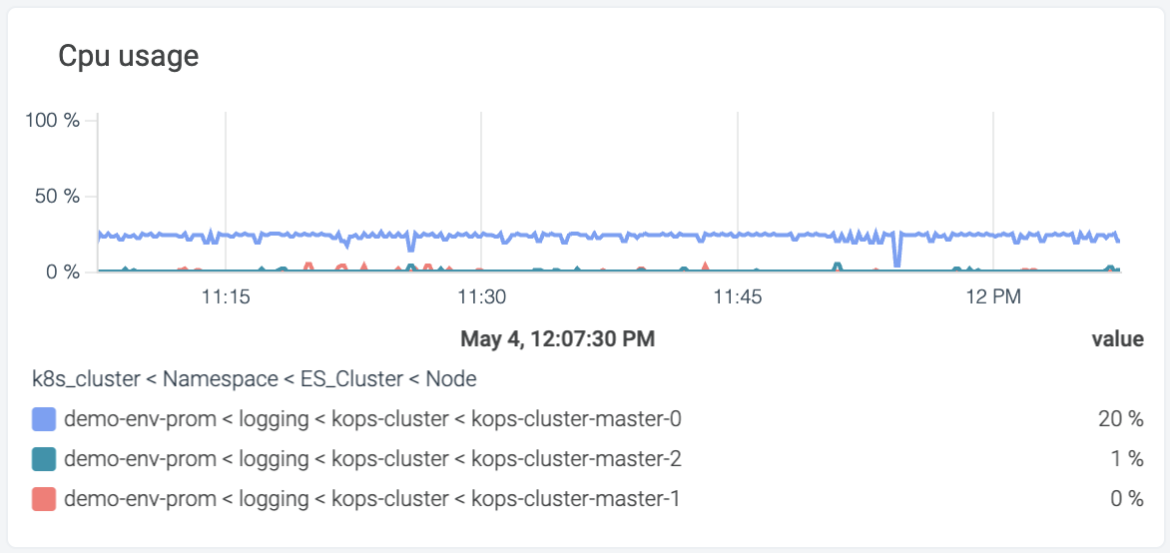
Monitoring Elasticsearch CPU
elasticsearch_process_cpu_percent
This is a gauge metric used to measure the current CPU usage percent (0-100) of the Elasticsearch process. Since chances are that you're running several Elasticsearch nodes, you will need to track each one separately.
elasticsearch_indices_store_throttle_time_seconds_total
In case you're using a file system as an index store, you can expect a certain level of delays in input and output operations. This metric represents how much your Elasticsearch index store is being throttled.
Since this is a counter metric that will only aggregate the total number of seconds, consider using rate or irate for an evaluation of how much it's suddenly changing.
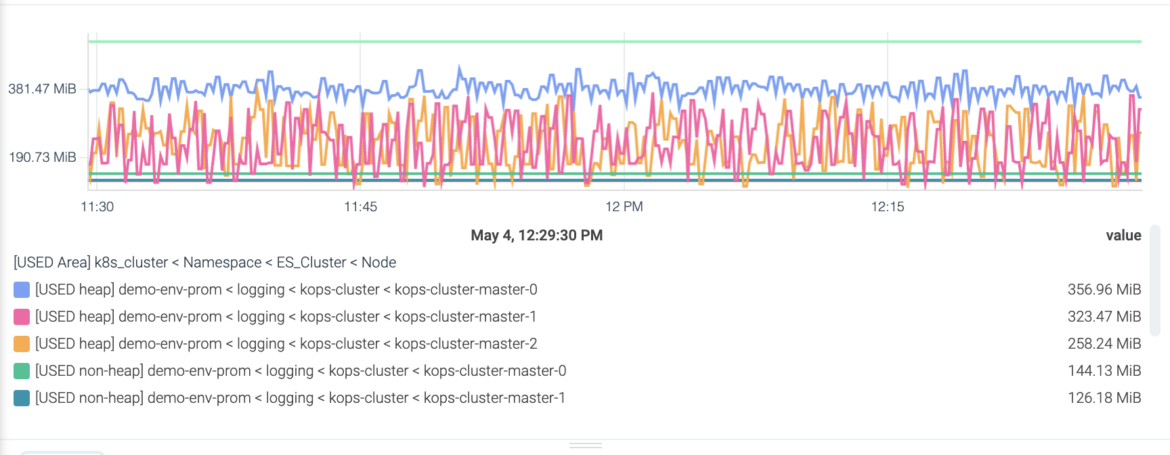
Monitoring Elasticsearch JVM Memory
Elasticsearch is based on Lucene, which is built in Java. This means that monitoring the Java Virtual Machine (JVM) memory is crucial to understand the current usage of the whole system.
elasticsearch_jvm_memory_used_bytes
This metric is a gauge that represents the memory usage in bytes for each area.
How to monitor Elasticsearch index performance
Indices in ElasticSearch partition the data as a logical namespace. Elasticsearch indexes documents in order to retrieve or search them as fast as possible.
Every time a new index is created, you can define the number of shards and replicas for it:
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}elasticsearch_indices_indexing_index_time_seconds_total
This metric is a counter of the seconds accumulated spent on indexing. It can give you a very approximated idea of the Elasticsearch indexing performance.
Note that you can divide this metric by elasticsearch_indices_indexing_index_total in order to get the average indexing time per operation.
elasticsearch_indices_refresh_time_seconds_total
For an index to be searchable, Elasticsearch needs a refresh to be executed. This is set up with the config index.refresh_interval, which is set by default to one minute.
This metric elasticsearch_indices_refresh_time_seconds_total represents a counter with the total time dedicated to refreshing in Elasticsearch.
In case you want to measure the average time for refresh, you can divide this metric by elasticsearch_indices_refresh_total.
How to monitor Elasticsearch search performance
While Elasticsearch promises near-instant query speed, chances are that in the real world, you may feel that is not the case. The number of shards, the storage solution chosen, or the cache configuration might impact search performance, and it's crucial to track what is the current behavior.
Additionally, the usage of wildcards, joins or the number of fields being searched will affect drastically the overall processing time of search queries.
elasticsearch_indices_search_fetch_time_seconds
A counter metric aggregating the total amount of seconds dedicated to fetching results in search.
In case you want to retrieve the average fetch time per operation, just divide the result by elasticsearch_indices_search_fetch_total.
How to monitor Elasticsearch cluster performance
Apart from the usual cloud requirements, an Elasticsearch system would like to look at:
- Number of shards.
- Number of replicas.
As a rule of thumb, the ratio between the number of shards and GB of heap space should be less than 20.
Note as well that it's suggested to have a separate cluster dedicated to monitoring.
elasticsearch_cluster_health_active_shards
This metric is a gauge that will indicate the number of active shards (both primary and replicas) from all the clusters.
elasticsearch_cluster_health_relocating_shards
Elasticsearch will dynamically move shards between nodes based on balancing or current usage. With this metric, you can control when this movement is happening.
Advanced Monitoring
Remember that the Prometheus exporter will give you a set of out-of-the-box metrics that are relevant enough to kickstart your monitoring journey. But the real challenge comes when you take the step to create your own custom metrics tailored to your application.
REST API
Additionally, mind that Elasticsearch provides a REST API that you can query for more fine-grained monitoring.
VisualVM
The Java VisualVM project is an advanced dashboard for Memory and CPU monitoring. It features advanced resource visualization, as well as process and thread utilization.
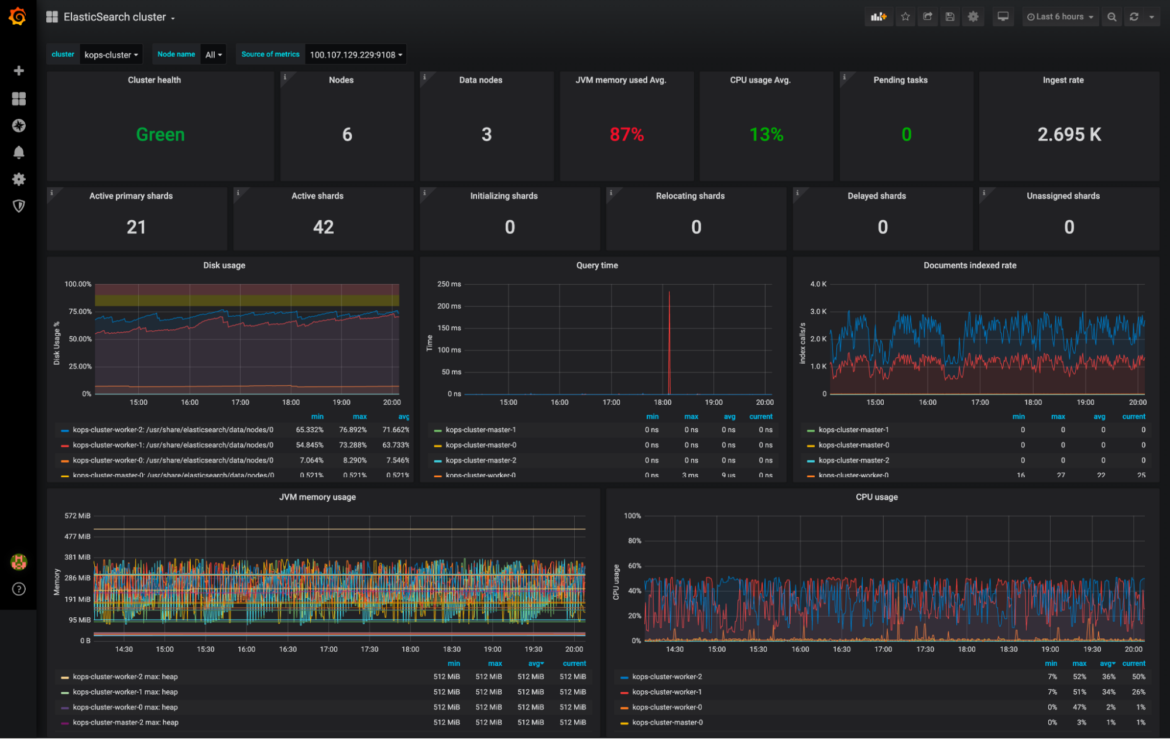
Download the Dashboards
You can download the dashboards with the metrics seen in this article through the Promcat official page.
This is a curated selection of the above metrics that can be easily integrated with your Grafana or Sysdig Monitor solution.
Conclusion
Elasticsearch is one of the most important search engines available, featuring high availability, high scalability, and distributed capabilities through redundancy.
Using the Elasticsearch exporter for Prometheus you can kickstart the monitoring journey in an easy way, by automatically receiving the important metrics directly.
As with many other applications, CPU, and Memory are crucial to understand system saturation. You should be aware of the current CPU throttling and the memory handling of the JVM.
Finally, it's important to dig deeper into the particularities of Elasticsearch, like indices and search capabilities, to truly understand the challenges of monitoring and visualization.