



Falco Feeds extends the power of Falco by giving open source-focused companies access to expert-written rules that are continuously updated as new threats are discovered.

Introduction
At Sysdig, we've built our solution from the ground up to provide deep visibility into containerized environments with no plugins or instrumentation required. We've taken these same principles and applied them to our recently announced StatsD support. We noticed that the current StatsD deployment strategies had serious limitations when it comes to collecting custom metrics from inside containers, and we set out to build a simple yet powerful way to extract custom application metrics from containerized environments – with no additional configuration required. It just works automatically, without you having to lift a finger.
Read on to learn more about current StatsD deployment strategies and how we've designed our StatsD implementation in a unique way.
State of the art: StatsD deployment strategies in containerized environments
The most standard StatsD deployment strategy consists in a StatsD collector that resides on a different machine, and aggregates the traffic from all of the StatsD sources. In this image, for example, we have three different containers, each of which with an application emitting StatsD traffic toward the collector.
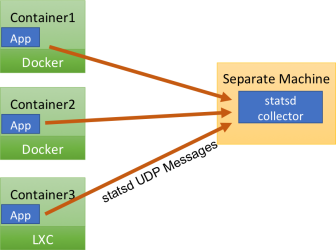
Usually, the collector's machine is reachable through a static IP address or an ad hoc DNS entry. This is how most Open Source StatsD deployments are done. It works well, but has a couple of limitations:
- every single StatsD metric update has to travel across the network, which imposes a tradeoff between the frequency of metric updates and the network bandwidth that gets consumed. \r
- StatsD metrics travel on the network separately from other metrics gathered from the machine or container, decreasing the opportunity to compress and efficiently transmit performance data.
- it's impossible to automatically tag and context-enhance the metrics for successive segmentation, because the information on which container/host/application has generated the metric is lost. \r
For these reasons, several commercial implementations adopt a different model: they have a local collector on each machine. This local collector assembles different types of metrics (StatsD, but also system information, process information, application information, and so on) into samples that get shipped to a general purpose monitoring backend at regular intervals, for example every minute. This model is shown in the next image, and has the advantage of being more efficient, especially in bigger deployments. Because metrics are aggregated and compressed before being sent to the monitoring backend. It's also simple, because you don't have to configure a target for StatsD: it just goes to localhost.

Only problem? This model works well in traditional virtualized environments, but tends to be a pain with containers. Adding a metric collection agent to every container is inefficient, complicates deployments, and is just not adherent to the container philosophy of having one process per container.
As a consequence, a third strategy is gaining adoption, shown in this picture:
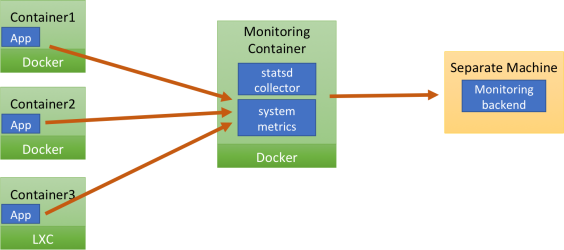
The StatsD collector resides on the same machine, but in a separate container. This separate container is often also in charge of collecting system metrics, stitching everything together and sending samples to a general purpose backend at regular intervals. This is a good compromise, definitely much better than having a StatsD daemon on each container, but it's still far from ideal. In particular, the apps in the containers need to know where they should send the StatsD UDP payloads. This can be done in a couple of ways:
- through a mechanism called linking, which involves exporting the IP address of the monitoring container to the other containers as an environment variable. This mechanism is quite rudimentary and pretty fragile. For example, it makes it hard to update the monitoring container, because that will almost certainly change its IP address and destroy the linking. \
- by assigning a static IP to the monitoring container. This has all the limitations involved with using static IP addresses, including having to having to come up with a way to avoid address conflicts if you want a monitoring container on each physical host. \r
So, too bad: we are left without good, easy options. Or maybe not?
The Sysdig Monitor approach
When we designed our highly requested StatsD integration, we had containerized environments in mind from day one. We came up with a patent pending approach we called passive StatsD collection (or, as I prefer to call it, StatsD teleport). Let me show you how it works:
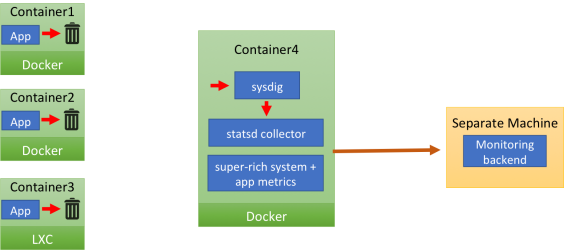
The careful reader has surely noticed that there are no arrows connecting the app containers and the monitor container. That's because the applications inside the containers send their StatsD messages to localhost. This means: no need to hardcode a collector IP address. However there's no StatsD collector on localhost, so the UDP payload just gets dropped (the image depicts it as the message going to a trashcan). The same message "magically" appears in the monitoring container (container4). Once there, it's is received by sysdig, which feeds it to the local StatsD collector, after enriching it with a set of tags (container name, ID and image name) that will enable segmentation. The StatsD messages are merged with Sysdig Monitor's incredibly detailed system, network and application metrics and then they are compressed and shipped to the Sysdig Monitor backend, once per second.
You're probably wondering: "How do StatsD messages go from the application container to the Sysdig Monitor one"? Let's add detail to the previous image:

What happens is that all network transmission made from inside the application containers, including StatsD messages, including the ones sent to a non existent destination, generate a system call. The sysdig cloud agent can capture these system calls from a separate container, where the StatsD collector is listening. In practice, sysdig acts as a transparent proxy between the application and the StatsD collector, even if they are in different containers. sysdig also knows which container the system call is coming from, and uses that information to transparently tag the StatsD message.
Benefits
We believe our approach brings the benefits of a local StatsD collector, without the typical drawbacks related to containers integration. In particular, the benefits include:
- no need to instrument the container in any way.
- super simple "push to localhost" approach.
- no network configuration required, no need to deal with DNS or static IP addresses.
- local aggregation with minimal bandwidth overhead.
- out of the box container/host tagging.
- aggregation of StatsD metrics with best in class container system, network and application metrics.
- it just works. Note how the passive collection system works even if you are already exporting StatsD metrics to an existing collector. In that case, Sysdig Monitor will capture them as well, with minimal overhead and with no disruption to the current export
Conclusion
As you can see, we've designed our StatsD support with complex, containerized environments in mind. We make it extremely simple to get visibility into custom metrics without having to devote any configuration effort whatsoever, we just magically see all of the metrics being sent to your StatsD server. To test drive this magic StatsD support yourself, sign up for a free trial today and let us know what you think!