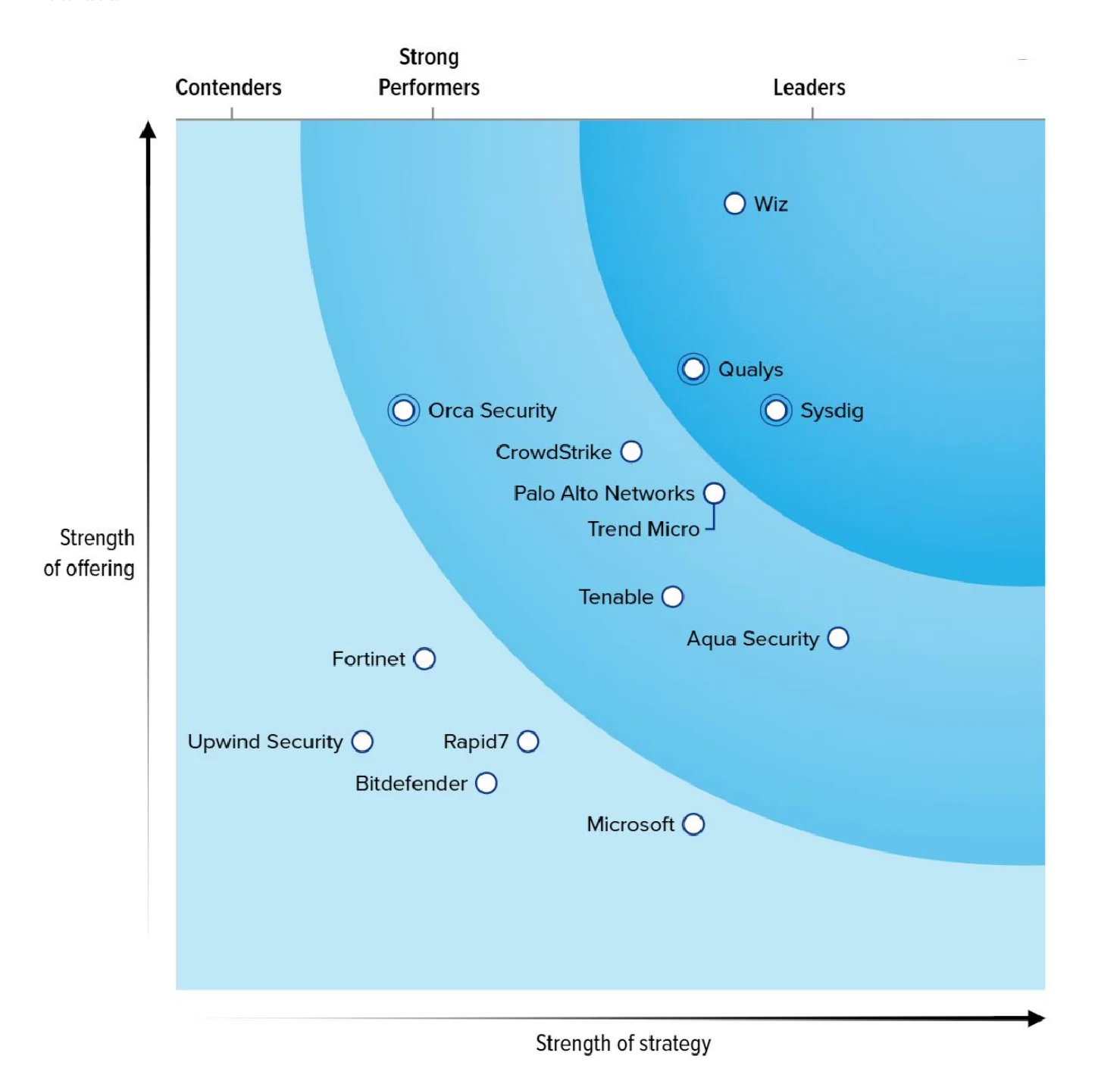
Forrester names Sysdig a Leader in CNAPP
Runtime redefines cloud security, the right way.
Secure the cloud
the right way withagentic AI.open innovation.runtime insights.agentic AI.
Sysdig delivers real-time security with zero compromise.
From protection to prevention, Sysdig secures the complete cloud lifecycle.
Introducing the industry's first agentic cloud security platform — powered by Sysdig Sage™.
Sysdig Sage is the first AI analyst built for cloud security — driven by specialized agents that think, reason, and act like a real security team.
Runtime is no longer optional.
We're a leader in real-time AI cloud defense.
Join the Sysdig Open Source Community.

In security,
there’s no room for compromise.
But security teams face constant pressure to
At the same time,
developers must
Both teams move fast, but they’re disconnected
So they compromise with good enough security.
Secure the cloud the right way
Secure
the cloud
the right way
The value of not
compromising on security.
Teams using Sysdig save time, fix faster, and defend smarter –
without slowing down innovation.



Empowering development and security teams together – the right way

Neo4j provides critical insights to organizations in some of the world’s most heavily regulated industries, including NASA and major U.S. banks. A security breach on their platform could have serious consequences.

Integrations
Sysdig helps teams work smarter, respond in real time, and build a more resilient security ecosystem.
Get security right.
Runtime redefines cloud security, the right way



99% of customers recommend Sysdig

AI unlocks value and new security risks