


Falco Feeds extends the power of Falco by giving open source-focused companies access to expert-written rules that are continuously updated as new threats are discovered.

本文の内容は、2022年11月23日にVICTOR HERNANDOが投稿したブログ(https://sysdig.com/blog/how-to-monitor-kubelet/)を元に日本語に翻訳・再構成した内容となっております。
Kubernetesを本番環境で運用する場合、Kubeletの監視は欠かせません。Kubeletは、Kubernetesクラスター内の非常に重要なサービスです。
このKubernetesコンポーネントは、Podで定義されたコンテナが実行され、健全であることを保証する役割を担っています。スケジューラがPodを実行するノードを指定するとすぐに、Kubeletはその割り当てを受け、Podとそのワークロードを実行します。

Kubernetes Kubeletで問題に直面した場合、できるだけ早く対処して問題を解決することが本当に重要で、そうしないとKubernetesノードがNotReady状態になってしまいます。アウトオブボックスで提供されるメトリクス計測のおかげで、Kubeletを監視することができますが、メトリクスは大量にあります! このうちどれを見直せばいいのでしょうか?
Kubeletを監視する方法と、最も重要なKubeletメトリクスが何であるかを知りたい場合は、読み続けて、障害を回避するためにどのように準備できるかを発見してください。
Kubeletとは何ですか?
Kubernetes Kubeletは、コントロールプレーンとワーカーノードの両方で、すべてのノードのプライマリノードエージェントとして実行されます。
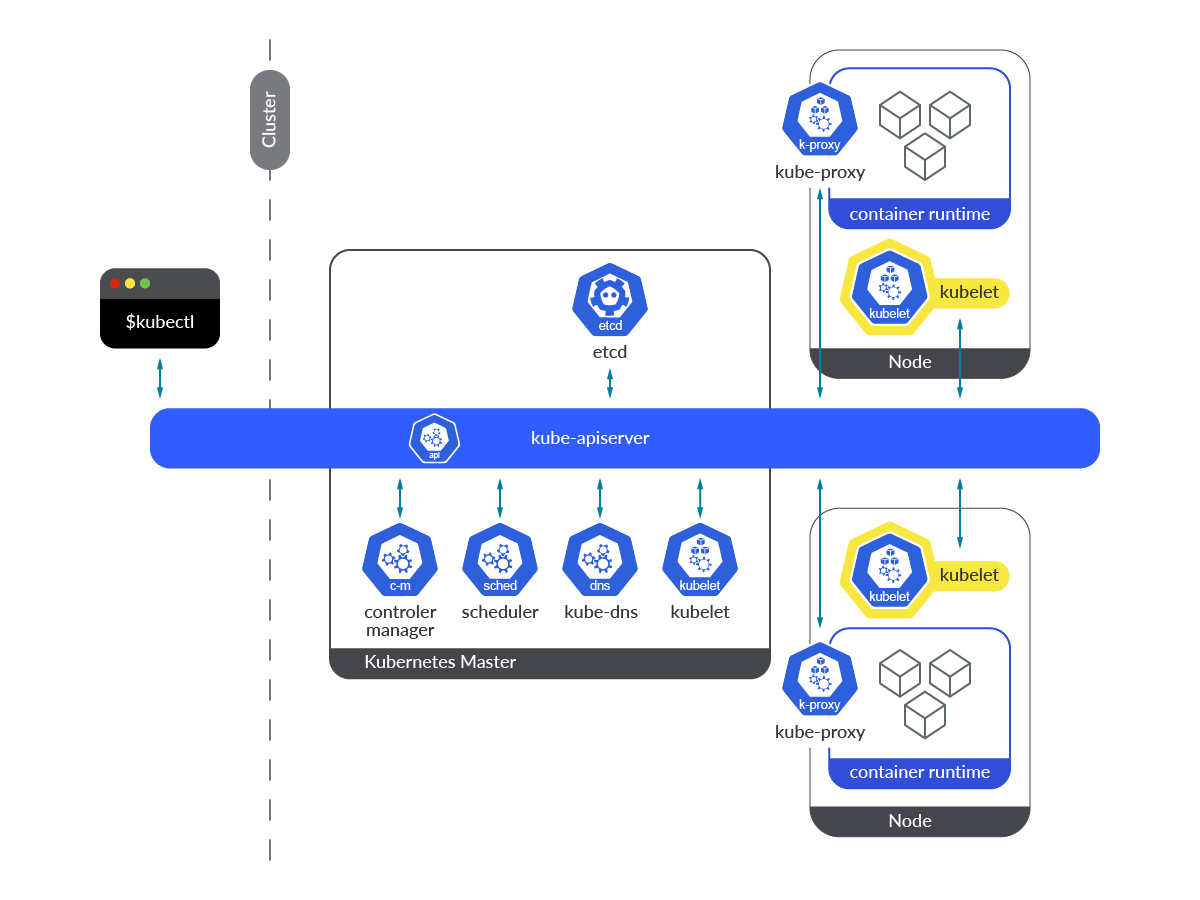
この図では、Kubeletがどこで動作しているかがすぐにわかると思います。これは、コントロールプレーンとワーカーノードの両方で動作するコンポーネントです。
Kubelet は宣言的な方法で動作し、PodSpec を受け取り、そこで定義されたコンテナが現在実行中で、健全な状態であることを確認します。その性質上、OS自体のサービスとして動作するエージェントであるため、クラスター内でKubernetesのエンティティとして動作する他のコンポーネントとは大きく異なっています。
Kubeletサービスは、恒久的に稼働している必要があります。こうすることで、特定のノードでPodが実行されるようにスケジュールされると同時に、Kubernetes APIから新しいPodSpecの定義を取得することができるようになります。Kubeletが正常に動作していない、クラッシュした、または何らかの理由でダウンした場合、Kubernetesノードは NotReady 状態になり、そのノードで新しいPodが作成されることはありません。
また、Kubeletがダウンしている時や正常に動作していない時の注意点として、 Liveness やReadiness のプローブが実行されないため、Kubeletダウン時にPod上で既に動作しているワークロードに障害が発生したり正常に動作しない場合、再起動されず、当該アプリケーションの安定性や可用性、性能に影響が出ることが挙げられます。
Kubeletの監視方法
Prometheusのノードロールは、クラスタノードごとに1つのターゲットを検出し、アドレスはKubeletのHTTPポートにデフォルトで設定されるので、PrometheusインスタンスからKubeletメトリクスをスクレイピングする方法として、このPrometheusロールに依存することは可能です。
Kubeletはインストルメント化されており、デフォルトでポート10250を通じて/metricsエンドポイントを公開し、Podsのボリュームや内部操作に関する情報を提供します。このエンドポイントは簡単にスクレイピングでき、必要な証明書を使用してHTTPSプロトコルでエンドポイントにアクセスする必要があるだけです。
Kubeletのメトリクスを取得したり、ノード自体にアクセスしたり、Podにsshしたりするために、このサービスは 0.0.0.0 アドレスでリスニングしているので、接続性という意味では全く制約がありません。Podがホストネットワークにアクセスできる場合は、 localhost も使ってアクセスできます。
PrometheusインスタンスでKubeletメトリクスエンドポイントをスクレイピングしたい場合は、 prometheus.yml 設定ファイルのscrape_configs セクションに以下の設定を追加すればOKです。
そして、新しい設定を適用して、 prometheus-server Podを再作成します。

これで、Prometheusインスタンスで利用できるKubeletのメトリクスが表示されるようになりました。
Kubeletを監視する:どのメトリクスを確認するのか?
すでにPrometheusインスタンスが稼働し、Kubeletメトリクスをスクレイプするように設定されています。では、次は何をすればいいのでしょうか?
監視すべき主要な Kubelet メトリクスについて説明しましょう。
免責事項:Kubeletメトリクスは、Kubernetesのバージョンによって異なる場合があります。ここでは、Kubernetes 1.25を使用しました。Kubeletで利用できる最新のメトリクスは、Kubernetes GitHub repoで確認できます。
Number of Kubelet instances: ここでは、Kubernetesクラスターで稼働しているKubeletインスタンスの数を簡単にカウントする方法が紹介されています。 kubelet_node_name メトリクスを合計するだけです。このPromQLクエリーの期待値は、クラスターのノード数です。
sum(kubelet_node_name)
Ready ノードの数をカウントする別の方法です:注:Readyでないノードの数を取得したい場合は、 status="false"でフィルタリングしてください。
sum(kube_node_status_condition{condition="Ready", status="true"})
kubelet_running_pods: Kubeletは、ノードで稼働しているPodの数を把握することができます。この値を定期的に確認し、ノードごとのPod制限に達していないか、またはこの数値がKubernetesクラスターの予想範囲内であるかを測定します。
kubelet_running_containers: このメトリクスは前のものとよく似ていますが、各ノードのコンテナ数をカウントしています。情報は、3つの異なる container_state:created、exited、runningに分類されます。このメトリクスを使用して、各ノードで実行されているコンテナの数を把握し、セットアップに基づいてコンテナの数が期待通りであるかどうかを測定します。
volume_manager_total_volumes: Kubeletは、コントローラーが示すボリュームをマウントするため、そのボリュームに関する情報を提供することができます。このメトリクスは、Podの作成時にマウントされていないボリュームの問題を特定し、診断するのに便利です。各 plugin_name は desired_state_of_world と actual_state_of_world という 2 つの異なる state フィールドを提供します。そうすれば、両方の値が混在していても、簡単に不一致を探すことができます。
以下、Kubeletが実行した各操作のGolden Signalsメトリクス(kubelet_runtime_operations_total, kubelet_runtime_operations_errors_total, and kubelet_runtime_operations_duration_seconds_bucket)が表示されていることがわかります。一方、Kubeletのサチュレーション状態は、利用可能なシステムメトリクスの一部で測定できます。
kubelet_runtime_operations_total: このメトリクスは、各タイプの実行時操作の総数(container_status, create_container, exec, exec_sync, image_status,list_containers, list_images, list_podsandbox, remove_container, etc)を提供します。
これはカウンターのメトリクスですが、rate関数を使ってKubeletのランタイムオペレーションの平均増加率を計算することができます。
sum(rate(kubelet_runtime_operations_total{job="kubernetes-nodes"}[5m])) by (operation_type, instance)

Kubelet実行時操作の平均増加率を計算するためにrate関数を使用できます。
kubelet_runtime_operations_errors_total:ランタイムレベルのオペレーションで発生したエラーの数。コンテナランタイムの問題など、ノードの低レベルの問題を示す指標となりえます。先ほどのメトリクスと同様に、kubelet_runtime_operation_errors_total はカウンタなので、rate関数を使用してエラーの平均増加量を時系列で測定することができます。
kubelet_runtime_operations_duration_seconds_bucket: このメトリクスは、すべての操作の時間を測定します。パーセンタイルを計算するのに便利です。
インスタンスと操作タイプ別のKubelet実行時操作時間の99パーセンタイルを計算したい場合があります。
histogram_quantile(0.99, sum(rate(kubelet_runtime_operations_duration_seconds_bucket{instance=~".*"}[5m])) by (instance, operation_type, le))

このクエリーを使用して、Kubelet実行時操作期間の99パーセンタイルを表示します。
次のメトリクスは、Podの開始率とその持続時間に関する情報を提供します。これらのメトリクスは、コンテナランタイムの問題の良い指標となり得ます。
kubelet_pod_start_duration_seconds_count: このメトリクスは、Pod の開始操作に関するカウントを提供します。
kubelet_pod_worker_duration_seconds_count: 1つのPodに対する作成、同期、更新操作の回数です。
kubelet_pod_start_duration_seconds_bucket: このメトリクスは、Kubeletが初めてPodを見てからPodの実行が開始されるまでの継続時間(秒)をヒストグラムで表示します。
ノードごとのPod開始時間秒数の95パーセンタイルが取得できます。
histogram_quantile(0.95,sum(rate(kubelet_pod_start_duration_seconds_bucket{instance=~".*"}[5m])) by (instance, le))
kubelet_pod_worker_duration_seconds_bucket: このメトリクスは、Podを同期するのにかかる時間を秒単位で提供します。情報は、作成、更新、同期の3種類に分かれています。
Kubelet Podのワーカー期間メトリクスについても、パーセンタイルを確認する価値があるかもしれません。こうすることで、すべてのノードで異なるオペレーションがどのように実行されているかをより理解することができます。
histogram_quantile(0.99, sum(rate(kubelet_pod_worker_duration_seconds_bucket{instance=~".*"}[5m])) by (instance, operation_type, le))

KubeletのPodワーカーの継続時間メトリクスに対するパーセンタイルの取得
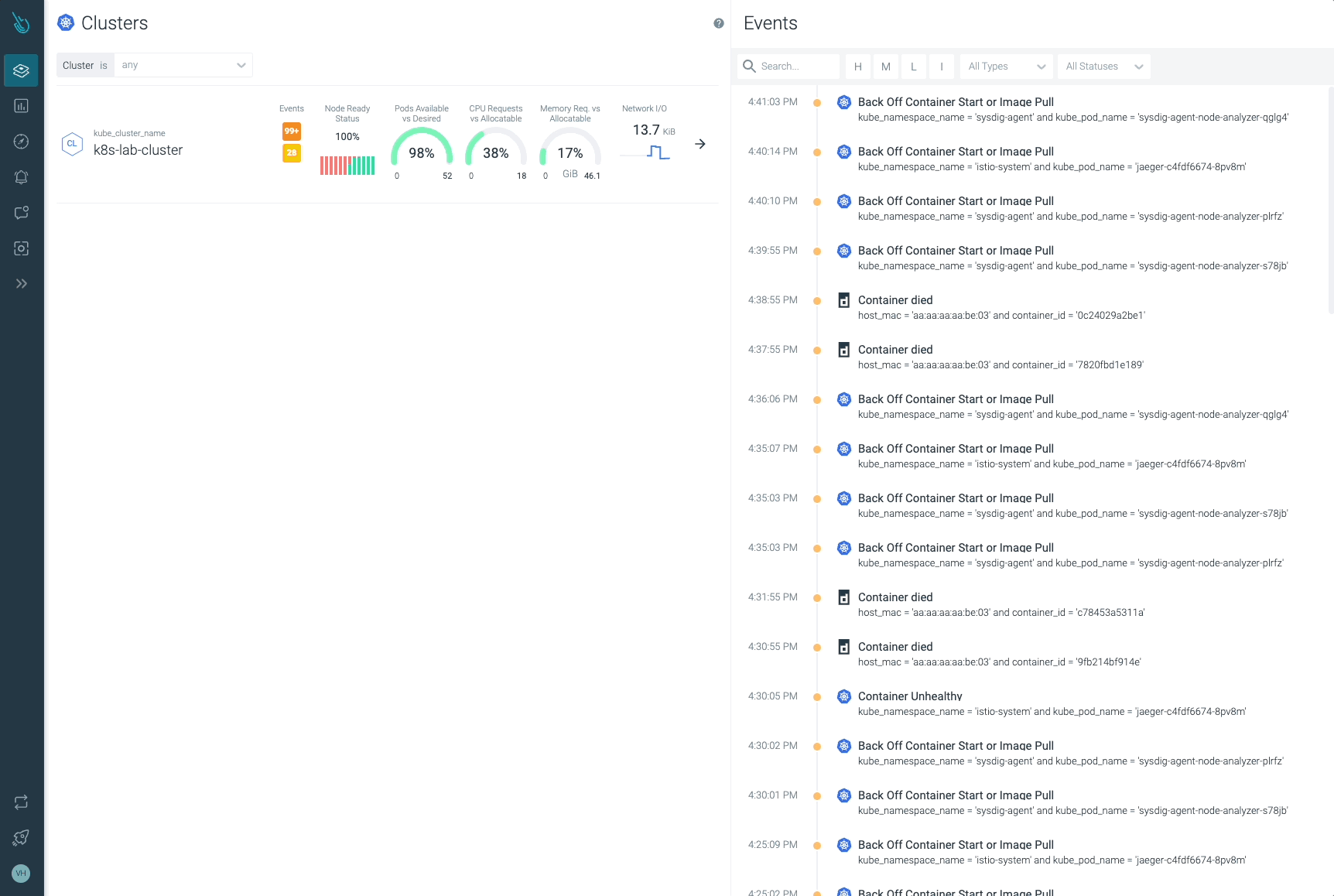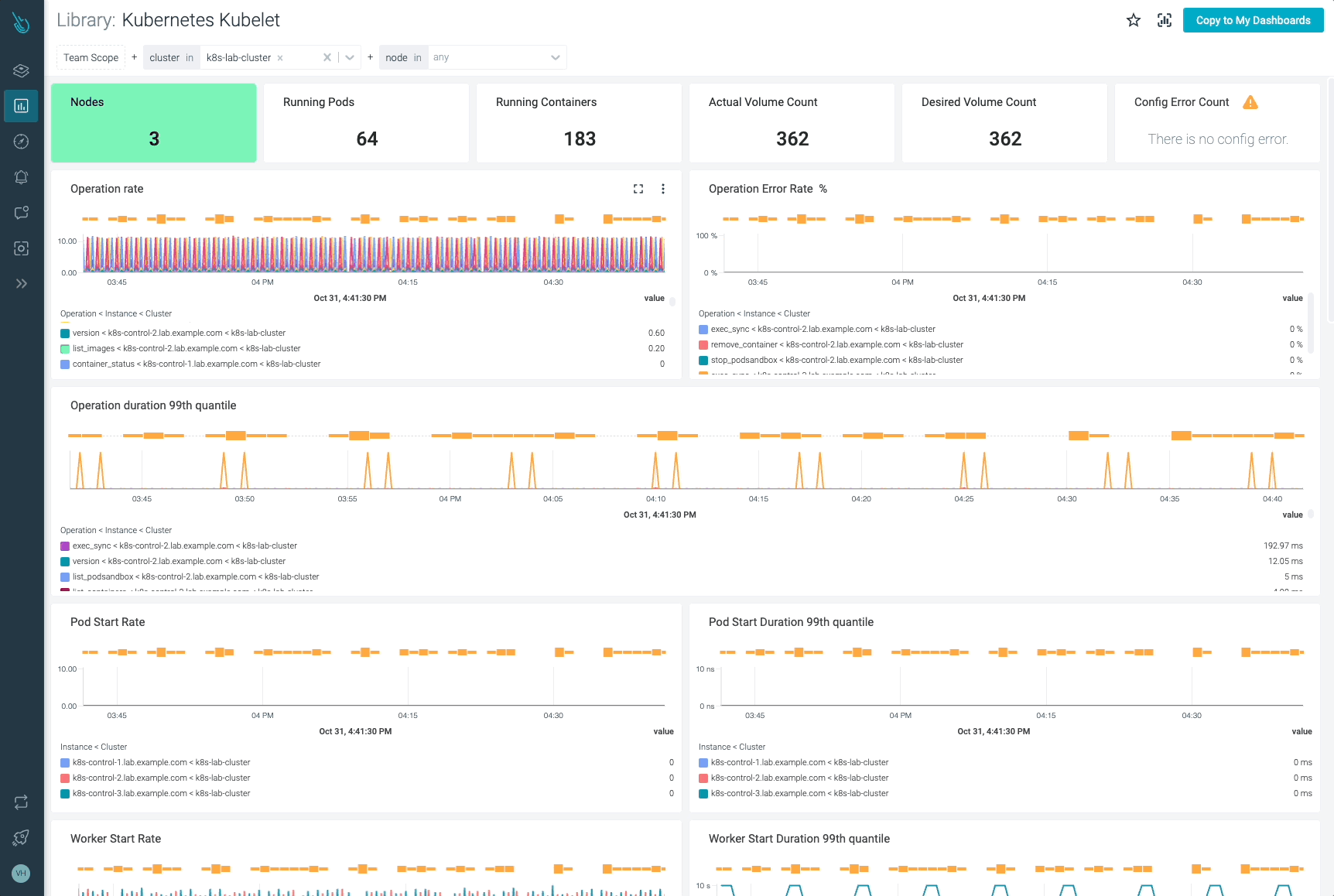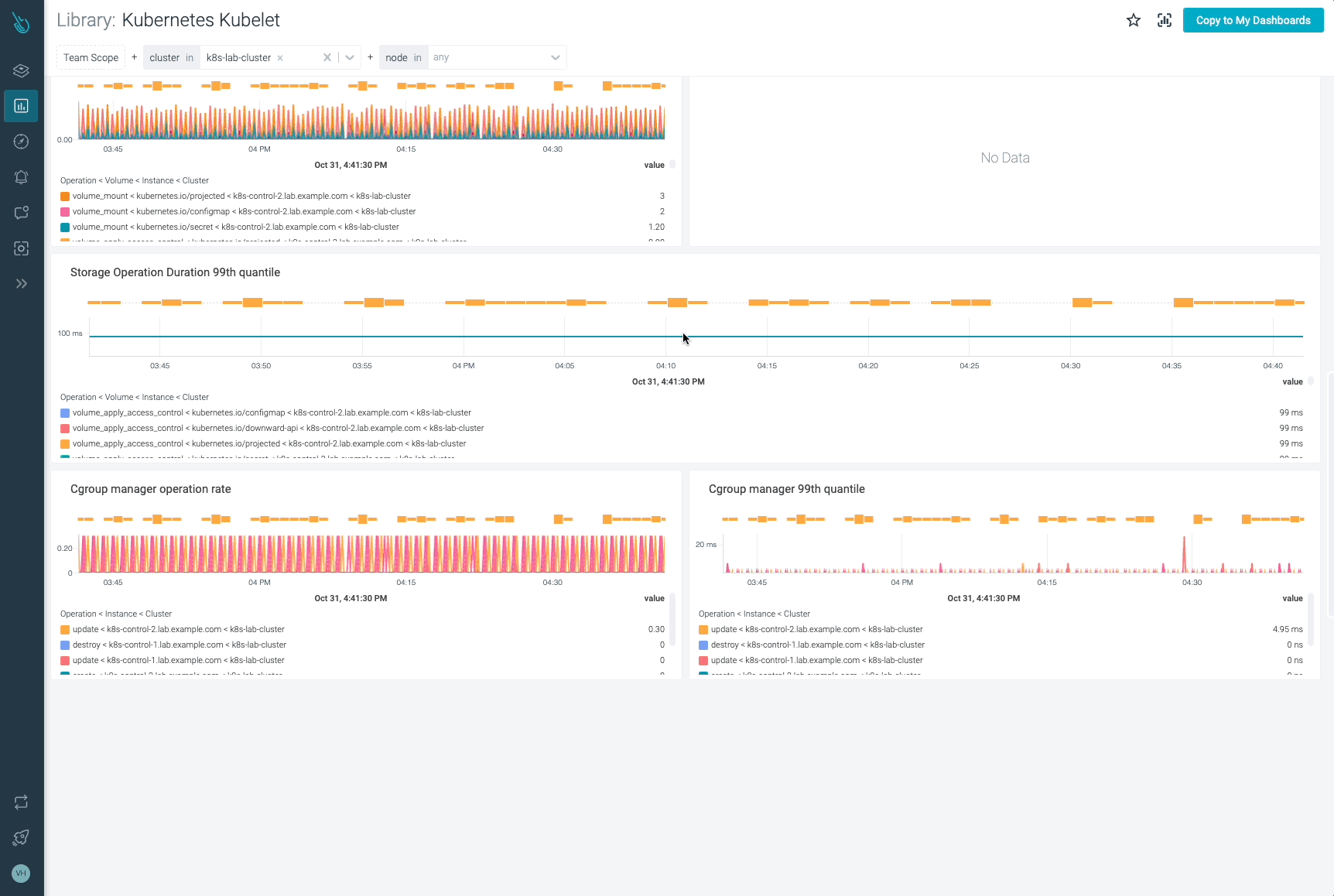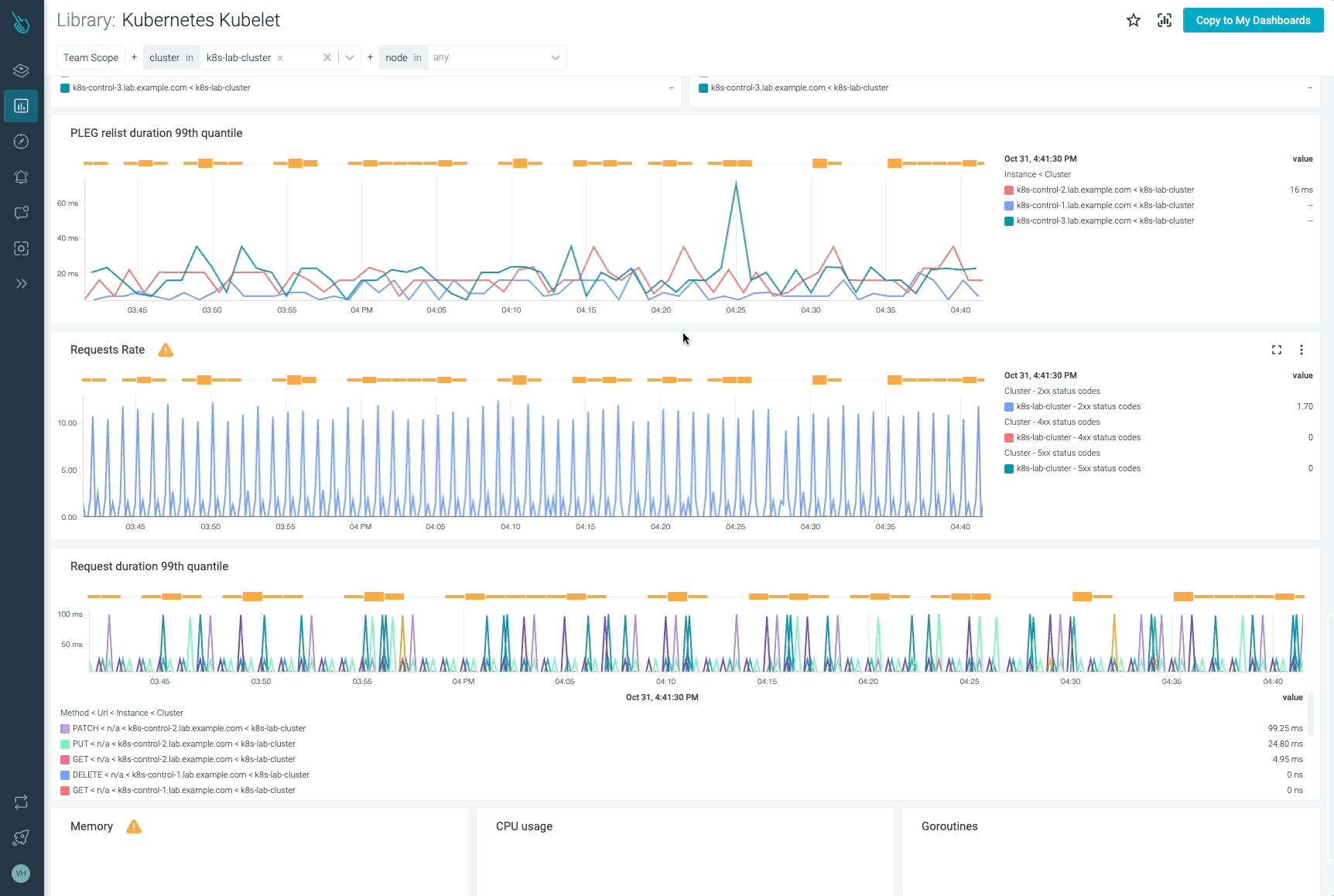
Storage Golden Signalsのメトリクスになります:
storage_operation_duration_seconds_count: volume_plugin 毎のストレージ操作の回数。
ストレージの操作率を取得するためには、以下のクエリーを使用します。実行されたさまざまな操作の概要、各操作のステータス、関連するボリュームプラグインを取得します。
sum(rate(storage_operation_duration_seconds_count{instance=~".*"}[5m])) by (instance, operation_name, volume_plugin, status)
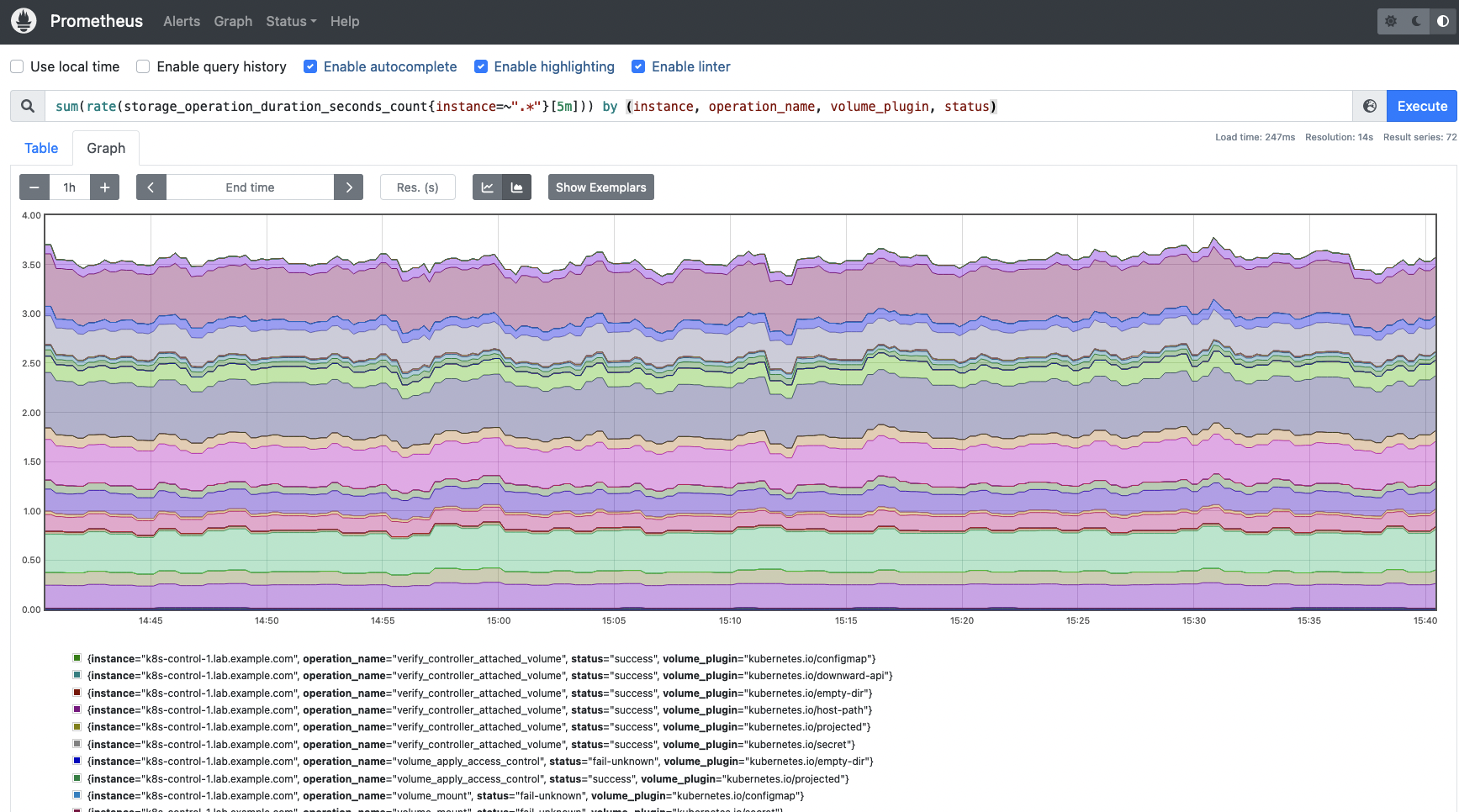
このクエリーを使用して、ストレージ操作のレートを取得します。ステータス、ボリュームプラグイン、実行された操作の情報を取得します。
storage_operation_duration_seconds_bucket: 各ストレージ操作の継続時間(秒)を測定します。この情報はヒストグラムで表現されます。
今度は、インスタンス、操作名、ボリュームプラグインでグループ化されたストレージ操作期間の99パーセンタイルを取得したい場合があります。
では、Kubelet cgroup managerのメトリクスについて説明していきましょう。
kubelet_cgroup_manager_duration_seconds_bucket: このメトリクスは、cgroupマネージャー操作の継続時間(秒)を提供します。このデータは、破壊と更新の 2 種類の方法に分かれています。
Kubelet cgroup manager の操作の 99 パーセンタイルを表すヒストグラムを取得する方法を見てみましょう。このクエリーは、Kubelet cgroup操作タイプごとの持続時間をよりよく理解するのに役立ちます。
histogram_quantile(0.99, sum(rate(kubelet_cgroup_manager_duration_seconds_bucket{instance=~".*"}[5m])) by (instance, operation_type, le))
kubelet_cgroup_manager_duration_seconds_count: 先ほどのメトリクスと同様、今回はdestroyとupdateの操作回数をカウントしています。
最後に、Kubeletが提供するPLEGメトリクスについて説明します。PLEG(Pod Lifecycle Event Generator)は、コンテナの実行時状態を調整する役割を担うKubeletのモジュールです。このタスクを達成するために、コンテナの変更を発見するための定期的なリスティングに依存しています。これらのメトリクスは、コンテナ実行時のレイテンシーでエラーが発生しているかどうかを判断するのに役立ちます。
kubelet_pleg_relist_interval_seconds_bucket: このメトリクスは、PLEGにおける再リスト化操作の間隔を秒単位でヒストグラムにしたものです。
Kubeletの再リスト化PLEG操作の間隔の99パーセンタイルを取得することができます。
histogram_quantile(0.99, sum(rate(kubelet_pleg_relist_interval_seconds_bucket{instance=~".*"}[5m])) by (instance, le))

このヒストグラムでは、PLEG操作の再リスト化の間隔を秒単位で概観することができます。
kubelet_pleg_relist_duration_seconds_bucket: PLEGでPodを再リスト化する際の秒数です。
今回は、Kubelet PLEGの再リスト化操作の99パーセンタイルを表すヒストグラムをビルドする方法を確認しましょう。
histogram_quantile(0.99, sum(rate(kubelet_pleg_relist_duration_seconds_bucket{instance=~".*"}[5m])) by (instance, le))

このクエリーを使用して、Kubelet PLEGの再リスト化操作の99パーセンタイルを表すヒストグラムを構築します。
kubelet_pleg_relist_duration_seconds_count: PLEGの再リスティング操作の回数。
まとめ
Kubeletは、Kubernetesの重要なコンポーネントです。この要素は、各ノードのコンテナランタイムと通信する役割を担っています。Kubeletが応答しない、クラッシュした、何らかの理由でダウンした場合、ノードは NotReady 状態になって新しいPodを起動できなくなり、コンテナレベルで何か問題が発生すると既存のPodの再作成に失敗してしまうでしょう。そのため、Kubeletとは何か、Kubernetesにおけるその役割だけでなく、Kubeletをどのように監視するか、確認すべき最も重要なメトリクスは何かを理解することが非常に重要です。今回は、その両側面について学んでいただきました。すべての仕組みを確認し、今すぐKubeletの問題を予防するために積極的に行動しましょう!
Kubeletの監視と問題のトラブルシューティングを最大10倍高速化
Sysdigは、Sysdig Monitorに含まれるアウトオブボックスのダッシュボードを使用して、KubeletやKubernetesコントロールプレーンの他の部分の問題の監視とトラブルシューティングを支援することができます。Sysdig Monitorに統合されたツールであるAdvisorは、Kubernetesクラスタとそのワークロードのトラブルシューティングを最大10倍まで加速させます。
30日間のトライアルアカウントにサインアップして、ご自身でお試しください!