



Falco Feeds extends the power of Falco by giving open source-focused companies access to expert-written rules that are continuously updated as new threats are discovered.

The default Kubernetes Horizontal Pod Scaler (HPA) uses CPU load, in this article we will show how to configure it to pivot over any other monitoring metric implementing and extending the Kubernetes custom metrics API. We will use the number of HTTP requests as target metric to scale pod deployment.
Do not confuse a Kubernetes scaler (this article) with a Kubernetes scheduler:
- Kubernetes Horizontal Pod Autoscaler or HPA: Updates the number of pods (scale up / scale down) in response to a metric & threshold value.
- Kubernetes Scheduler: Assigns newly created pods to Kubernetes nodes. You can also use custom metrics to configure your Kubernetes scheduler.
Kubernetes pod scaling
Kubernetes has several mechanisms to control a group of identical pod instances (ReplicationControllers, ReplicaSets, Deployments). You can manually resize these groups at will, and of course, you can also configure a control entity that automatically increases or decreases pod count based on current demand.
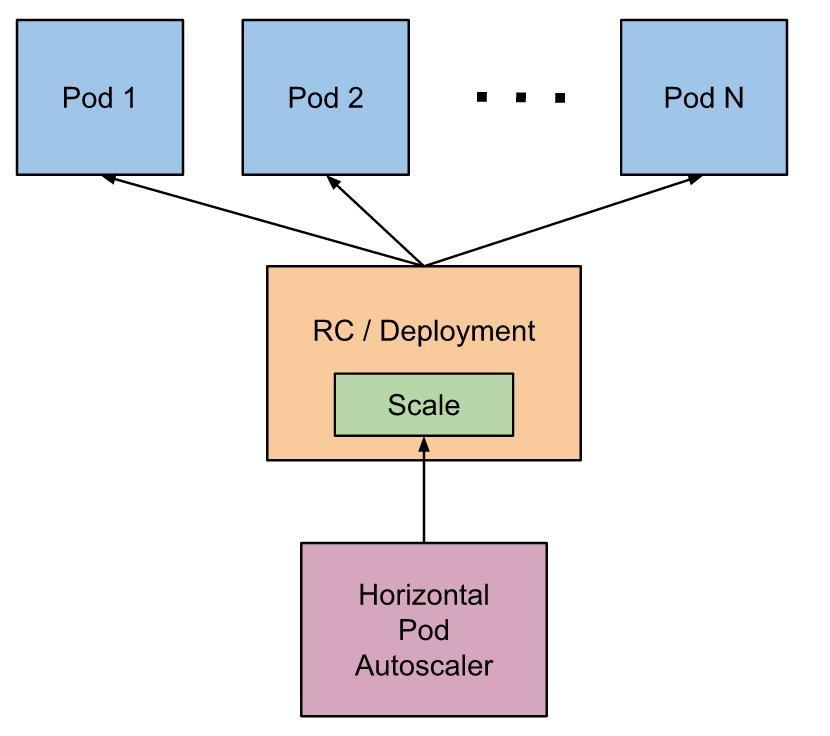
The Horizontal Pod Autoscaler periodically queries the configured metric(s) and compares against the desired target value. You can also configure minimum and maximum number of pods, scaling cooldown/delay periods (to avoid sudden bursts of containers rapidly spawning and terminating, also known as thrashing), sync period, etc.
You can implicitly create an HPA just using a kubectl one-liner, like this one:
kubectl autoscale rc foo --min=2 --max=5 --cpu-percent=80 How to build a #Kubernetes Horizontal Pod Autoscaler (HPA) using custom metrics, #golang API server Click to tweet
Kubernetes autoscaling using custom metrics
Kubernetes HPA is an extremely useful mechanism, but pivoting just over CPU metrics may not be that interesting for your specific use case.
As you might expect, these Kubernetes entities can be extended to support any metric or group of metrics you desire. For this tutorial we have decided to optimize over the number of HTTP requests per second. This way, if my web service experiences a sudden traffic burst, Kubernetes will automatically increase the number of servicing pods, improving my service quality, when the rush is over it will downsize again, reducing the operative costs on my side.
Former custom metrics method vs Kubernetes 1.6+
Please note that in Kubernetes versions previous to 1.6 custom metrics were implemented using Heapster Model API, this method is now deprecated.
Here we will use a newer method that requires deploying an extended API server implementing the Kubernetes custom metric apiserver spec.
Kubernetes cluster requirements & testbed node
To implement custom metrics using this method your Kubernetes cluster needs to meet these requirements:
- Kubernetes version 1.6 or higher
- API aggregation layer enabled
- The kube-controller-manager needs the following flags:
- –horizontal-pod-autoscaler-use-rest-clients should be true
- –kubeconfig "path-to-kubeconfig" OR –master "ip-address-of-apiserver"
Do you have a compatible cluster? excellent! continue reading.
What if you don't have a compatible cluster yet? No problem, go to the appendix and configure a single-node compatible Kubernetes cluster using a virtual machine.
Deploying a custom Kubernetes autoscaler
Kubernetes scaler target deployment
First you need a service / deployment that will be controlled by the HPA. In case you are using an empty testbed node, you can use the simple Kubernetes Up And Running deployment included in the repository:
git clone https://github.com/draios/kubernetes-sysdig-metrics-apiserver.git
$ kubectl apply -f kubernetes-sysdig-metrics-apiserver/deploy/00-kuard.yml
deployment.extensions/kuard created
service/kuard created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
kuard-b64d9cc8d-rch24 1/1 Running 0 50s
kuard-b64d9cc8d-rksdl 1/1 Running 0 50s
kuard-b64d9cc8d-wt5sr 1/1 Running 0 50s
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kuard ClusterIP 10.23.249.25 80/TCP 1m
kubernetes ClusterIP 10.23.240.1 443/TCP 1h
Custom metrics API server
Next step is to create an entity that extends the API implementing the custom-metrics-apiserver Golang interface.
There is a Prometheus adapter implementation that will query local Prometheus servers. For this article we want to demonstrate a different implementation of the API server that directly retrieves metrics from Sysdig Monitor if you are using our Kubernetes monitoring product. This way you don't need to instrument the target pods in any way, as Sysdig provides HTTP request count and many other metrics automatically.
Naturally, you first need to install the Sysdig agent in your Kubernetes cluster to start collecting metrics. Make sure the pods and metrics you want to target show up in your Sysdig Monitor web panel before proceeding.
If you don't have the Sysdig Agent deployed in your Kubernetes cluster, edit the file kubernetes-sysdig-metrics-apiserver/deploy/01-sysdig-daemon-set.yml, you will find a Kubernetes secret that will contain your Sysdig Agent access token, please note that you need the base64 representation of this token:
$ echo -n ffffffff-ffff-ffff-ffff-ffffffffffff | base64
ZmZmZmZmZmYtZmZmZi1mZmZmLWZmZmYtZmZmZmZmZmZmZmZmCg==
Once you have added your Sysdig Agent token, execute:
$ kubectl apply -f kubernetes-sysdig-metrics-apiserver/deploy/01-sysdig-daemon-set.yml
namespace/sysdig-agent created
secret/sysdig-agent created
serviceaccount/sysdig-account created
clusterrole.rbac.authorization.k8s.io/sysdig-cluster-role created
clusterrolebinding.rbac.authorization.k8s.io/sysdig-cluster-role-binding created
daemonset.extensions/sysdig-agent created
This will create a separate namespace for the pod implementing the API, and the required RBAC roles, permissions, bindings, etc:
$ kubectl apply -f kubernetes-sysdig-metrics-apiserver/deploy/02-sysdig-metrics-rbac.yml
namespace/custom-metrics created
serviceaccount/custom-metrics-apiserver created
clusterrolebinding.rbac.authorization.k8s.io/custom-metrics:system:auth-delegator created
rolebinding.rbac.authorization.k8s.io/custom-metrics-auth-reader created
clusterrole.rbac.authorization.k8s.io/custom-metrics-resource-reader created
clusterrolebinding.rbac.authorization.k8s.io/custom-metrics-apiserver-resource-reader created
clusterrole.rbac.authorization.k8s.io/custom-metrics-getter created
clusterrolebinding.rbac.authorization.k8s.io/hpa-custom-metrics-getter created
service/api created
apiservice.apiregistration.k8s.io/v1beta1.custom.metrics.k8s.io created
clusterrole.rbac.authorization.k8s.io/custom-metrics-server-resources created
clusterrolebinding.rbac.authorization.k8s.io/hpa-controller-custom-metrics created
And now, the key component, a pod extending and implementing the Kubernetes custom metrics API.
You need to modify the file kubernetes-sysdig-metrics-apiserver/deploy/03-sysdig-metrics-server.yml and add your Sysdig API token to the Kubernetes secret that you will find there. This token is different from the previous one, which was the Agent token:
$ echo -n ffffffff-ffff-ffff-ffff-ffffffffffff | base64
ZmZmZmZmZmYtZmZmZi1mZmZmLWZmZmYtZmZmZmZmZmZmZmZmCg==
And then, execute:
$ kubectl apply -f kubernetes-sysdig-metrics-apiserver/deploy/03-sysdig-metrics-server.yml
secret/sysdig-api created
deployment.apps/custom-metrics-apiserver created
Once the pod is Running, you should be able to inspect all the metrics present in the custom.metrics.k8s.io extension:
$ kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq -r ".resources[].name"
services/mongodb.globallock.currentqueue.writers
services/jvm.gc.ConcurrentMarkSweep.count
services/redis.perf.latest_fork_usec
services/file.time.in
services/redis.slowlog.micros.99percentile
services/net.bytes.in
services/memory.pageFault.major
...
You can even increase the privileges of the default system user (don't do this in production) and fetch the specific metric value:
$ kubectl create clusterrolebinding cli-api-read-access --clusterrole custom-metrics-getter --user system:anonymous
$ kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/services/kuard/net.http.request.count" | jq .
{
"kind": "MetricValueList",
"apiVersion": "custom.metrics.k8s.io/v1beta1",
"metadata": {
"selfLink": "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/services/kuard/net.http.request.count"
},
"items": [
{
"describedObject": {
"kind": "Service",
"namespace": "default",
"name": "kuard",
"apiVersion": "/__internal"
},
"metricName": "net.http.request.count",
"timestamp": "2019-02-14T11:28:04Z",
"value": "55"
}
]
}
Each pod is receiving an average of 55 HTTP requests for the interval we configured. Don't worry if your value is 0. You can request any metric from the list you've seen before.
Kubernetes Horizontal Pod Autoscaler: the scaler
We are only missing the last piece, the Horizontal Pod Autoscaler itself.
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: kuard-autoscaler
namespace: default
spec:
scaleTargetRef:
apiVersion: extensions/v1beta1
kind: Deployment
name: kuard
minReplicas: 3
maxReplicas: 10
metrics:
- type: Object
object:
target:
kind: Service
name: kuard
metricName: net.http.request.count
targetValue: 100
It targets the net.http.request.count metric with a target value of 100 requests per minute, if the averaged value of the service gets higher, it will automatically spawn more pods, if enough pods are idle, it will kill some replicas.
$ kubectl apply -f kubernetes-sysdig-metrics-apiserver/deploy/04-kuard-hpa.yml
horizontalpodautoscaler.autoscaling/kuard-autoscaler created
Wait a couple of minutes and can execute kubectl describe hpa to get current status.
$ kubectl describe hpa
Name: kuard-autoscaler
Namespace: default
Labels:
Annotations: kubectl.kubernetes.io/last-applied-configuration={"apiVersion":"autoscaling/v2beta1","kind":"HorizontalPodAutoscaler","metadata":{"annotations":{},"name":"kuard-autoscaler","namespace":"default"},"spe...
CreationTimestamp: Thu, 14 Feb 2019 12:39:16 +0100
Reference: Deployment/kuard
Metrics: ( current / target )
"net.http.request.count" on Service/kuard: 0 / 100
Min replicas: 3
Max replicas: 10
Deployment pods: 3 current / 3 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ReadyForNewScale the last scale time was sufficiently old as to warrant a new scale
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from Service metric net.http.request.count
ScalingLimited True TooFewReplicas the desired replica count is increasing faster than the maximum scale rate
Events:
So, it seems that the HPA found the custom metric and is able to pivot over it, hurrah! You can create some network stress using, for example, Apache Benchmark (your specific service IP will vary):
apt-get install apache2-utils
ab -c 10 -t 300 -n 10000000 http://10.23.249.25/
Leave the script running and open a new terminal. The number of requests will skyrocket, after a while you can query the scaler again and you will read:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 4m horizontal-pod-autoscaler New size: 3; reason: Service metric net.http.request.count above target
Normal SuccessfulRescale 27s horizontal-pod-autoscaler New size: 7; reason: Service metric net.http.request.count above target
It's scaling up the number of replicas, note that there is a cooldown period before the scaler takes a new decision, regardless of metrics. Eventually, if you wait 10-15 minutes after the stress script has finished, the scaler will realize it doesn't need the extra pods anymore:
Normal SuccessfulRescale 6m horizontal-pod-autoscaler New size: 5; reason: All metrics below target
Normal SuccessfulRescale 1m horizontal-pod-autoscaler New size: 2; reason: All metrics below target
Sysdig Monitor dashboards & alerts
From the Sysdig Monitor side you can easily retrieve detailed information for this scaling group and related events.
For example, this would be an example dashboard that you can compile in a few minutes using native Kubernetes context for the filters and segments:
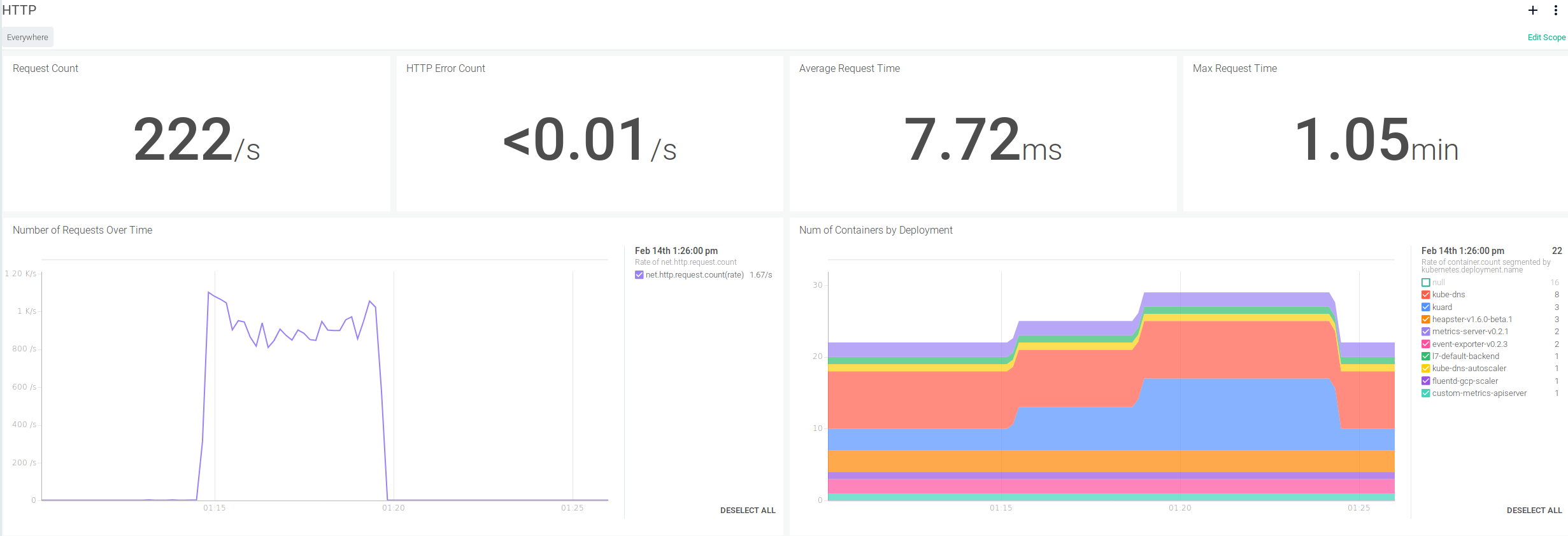
And it's not just informative panels and diagrams, Sysdig Monitor understands Kubernetes events out of the box, like a CrashloopBackoff or the scaling events we are causing. For example, you can easily set an alert when the Kubernetes HPA gets busier than usual:
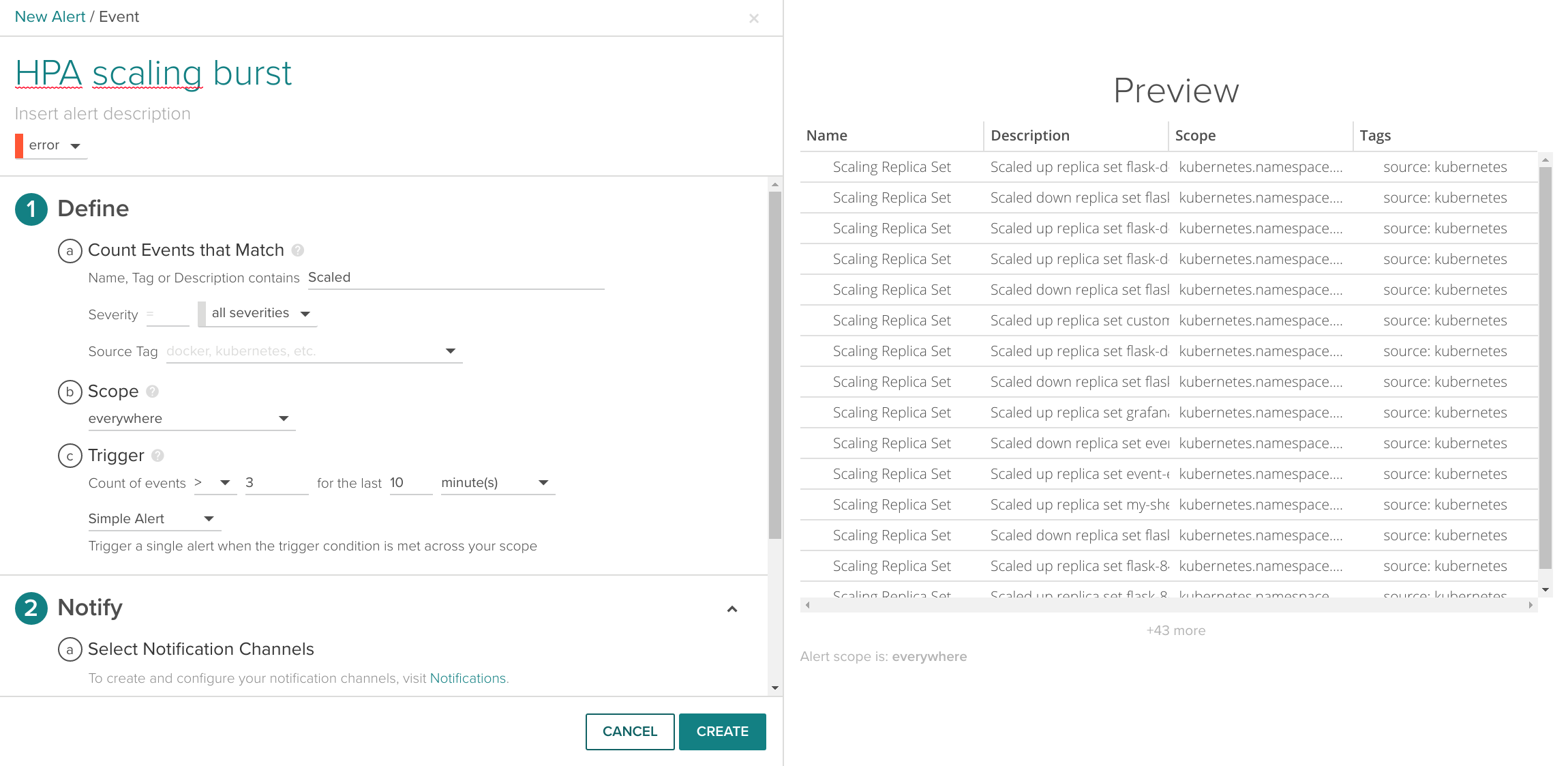
Now you can configure a Kubernetes scaler to optimize over any of your application specific metrics!
Kubernetes custom metrics API implementation
Without going into full detail, the basic concept is that you need to implement this metric provider interface
<pre><code><br>File: CustomMetricsProvider.go<br>------------------------------<br><br>type CustomMetricsProvider interface {<br> // GetRootScopedMetricByName fetches a particular metric for a particular root-scoped object.<br> GetRootScopedMetricByName(groupResource schema.GroupResource, name string, metricName string) (*custom_metrics.MetricValue, error)<br><br> // GetRootScopedMetricByName fetches a particular metric for a set of root-scoped objects<br> // matching the given label selector.<br> GetRootScopedMetricBySelector(groupResource schema.GroupResource, selector labels.Selector, metricName string) (*custom_metrics.MetricValueList, error)<br><br> // GetNamespacedMetricByName fetches a particular metric for a particular namespaced object.<br> GetNamespacedMetricByName(groupResource schema.GroupResource, namespace string, name string, metricName string) (*custom_metrics.MetricValue, error)<br><br> // GetNamespacedMetricByName fetches a particular metric for a set of namespaced objects<br> // matching the given label selector.<br> GetNamespacedMetricBySelector(groupResource schema.GroupResource, namespace string, selector labels.Selector, metricName string) (*custom_metrics.MetricValueList, error)<br><br> // ListAllMetrics provides a list of all available metrics at<br> // the current time. Note that this is not allowed to return<br> // an error, so it is reccomended that implementors cache and<br> // periodically update this list, instead of querying every time.<br> ListAllMetrics() []MetricInfo<br>}<br></code></pre>
… to complete the boilerplate API server code provided by the Kubernetes project.
For this example, we call the Sysdig REST API with the user-defined parameters configured in the YAML file (see above) and use this values to fill the MetricValue data structure expected by the code:
<pre><code><br>File: MetricValue.go<br>--------------------<br><br>&custom_metrics.MetricValue{<br> DescribedObject: custom_metrics.ObjectReference{<br> APIVersion: info.GroupResource.Group + "/" + runtime.APIVersionInternal,<br> Kind: kind.Kind,<br> Name: name,<br> Namespace: namespace,<br> },<br> MetricName: info.Metric,<br> Timestamp: metav1.Time{time.Now()},<br> Value: *resource.NewMilliQuantity(int64(metricdatapoint*1000.0), resource.DecimalSI),<br> }<br></code></pre>
The complete component diagram looks like this:
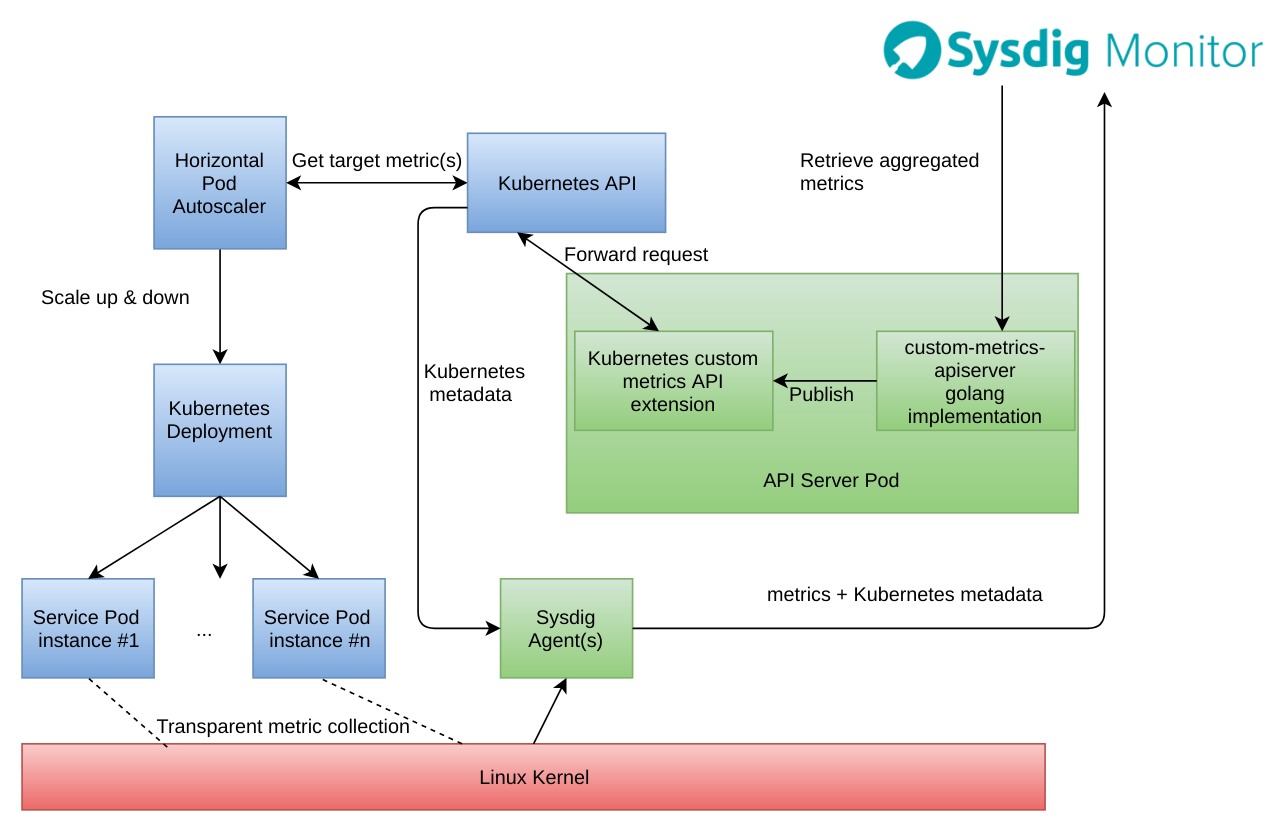
Further thoughts
- The new "custom metrics API" method is more complex to deploy (at least the first), but provides a higher level of abstraction and flexibility.
- The server code is a PoC, if you want to try this in a real environment you can use it as a starting point, but it doesn't have any error management or fallback code. We plan to keep improving this code as gets broader adoption but please, don't hesitate to send over your pull requests or comments to us! Either via Slack or Twitter on @sysdig.
- Being able to optimize over ANY custom metric(s) feels so effective, you are probably thinking about your particular use cases now.
Appendix: Kubernetes scaler testbed node
Ok, so you don't have a compatible cluster just yet. Let's create one.
First thing you need is a virtual machine, we are going to use Ubuntu server LTS 64 bits. If possible, allocate 2 virtual CPUs and ~3GB of RAM, your cluster may have pod allocation problems with less than that.
Do not configure any swap memory, Kubernetes doesn't like swap. If the host you want yo use already has swap space, you can always:
swapoff -a
If you want to use kubectl outside the virtual machine, make sure that hostname -i resolves to the IP you want to target.
Once the VM is installed, download git and get the tutorial repository:
sudo apt-get update
sudo apt-get install git
git clone https://github.com/mateobur/kubernetes-scaler-metrics-api.git
Next, you install Docker and kubeadm (as root), the custom-metrics specification is still in beta so we pin specific Kubernetes package versions to avoid inconsistencies.
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add -
cat < /etc/apt/sources.list.d/kubernetes.list
deb http://apt.kubernetes.io/ kubernetes-xenial main
EOF
apt-get update
apt-get install -y docker.io
apt-get install kubeadm=1.8.7-00 kubernetes-cni=0.5.1-00 kubelet=1.8.7-00 kubectl=1.8.7-00
and init your Kubernetes cluster!
# kubeadm init --config kubernetes-scaler-metrics-api/testbednode/kubeadm.yml
This will take a while.
Look for the sentence:
Your Kubernetes master has initialized successfully!
And pay attention to the text below it, it has instructions to configure kubectl, join nodes to the cluster, etc.
Acknowledgments: Some of the YAML files used in this article (Node configuration, RBAC roles) are based on the ones provided by Lucas on this tutorial. Thanks Lucas!
change to the regular user and type:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
then try to inspect the kube-system pods, you should get something similar to this:
$ kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system etcd-kubenode 1/1 Running 0 3m
kube-system kube-apiserver-kubenode 1/1 Running 0 3m
kube-system kube-controller-manager-kubenode 1/1 Running 0 4m
kube-system kube-dns-86cc76f8d-hmr2r 0/3 Pending 0 4m
kube-system kube-proxy-zctpb 1/1 Running 0 4m
kube-system kube-scheduler-kubenode 1/1 Running 0 3m
Next, you need to deploy a pod network layer
$ kubectl apply -f https://git.io/weave-kube-1.6
If you want to just use this single node, you need to remove the taint so regular pods can be scheduled in it:
$ kubectl taint nodes --all node-role.kubernetes.io/master-
wait until all the pods are in READY status (the kube-dns ones usually take a little longer).
Your cluster is ready to go! make a snapshot just in case and go back to configuring your custom metrics.