


Falco Feeds extends the power of Falco by giving open source-focused companies access to expert-written rules that are continuously updated as new threats are discovered.

With an ever-growing number of vulnerabilities being discovered annually, vulnerability management tools are rapidly evolving to handle and prioritize these risks. However, it remains one of the most overwhelming and time-consuming areas in cybersecurity. There's still significant room for enhancement, especially in reducing false alerts and prioritizing genuine threats.
The vulnerability scanning process can be divided into four stages:
- Asset Retrieval: Accessing and scanning the content of an asset
- Analysis: Extracting the SBOM (Software Bill Of Materials)
- Vulnerability Matching: Aligning vulnerabilities with the SBOM
- Policy Evaluation & Risk Acceptance: Deciding on the risk levels of the identified vulnerabilities
While each phase has room for improvement, this blog focuses on the third stage—Vulnerability Matching—and the innovations recently introduced by Sysdig.
Challenges in Vulnerability Detection
- Software vs. Affected-Library Detection: A significant challenge in vulnerability detection arises from the inaccuracy in identifying affected packages, especially for Non-OS packages. For instance, many CVE data sources, including the NVD (National Vulnerability Database), sometimes provide detection information at the software level (e.g., Log4j) rather than the package level (e.g., org.apache.logging.log4j.LogManager). This discrepancy can lead to false positives, as not all packages within an application might be vulnerable.
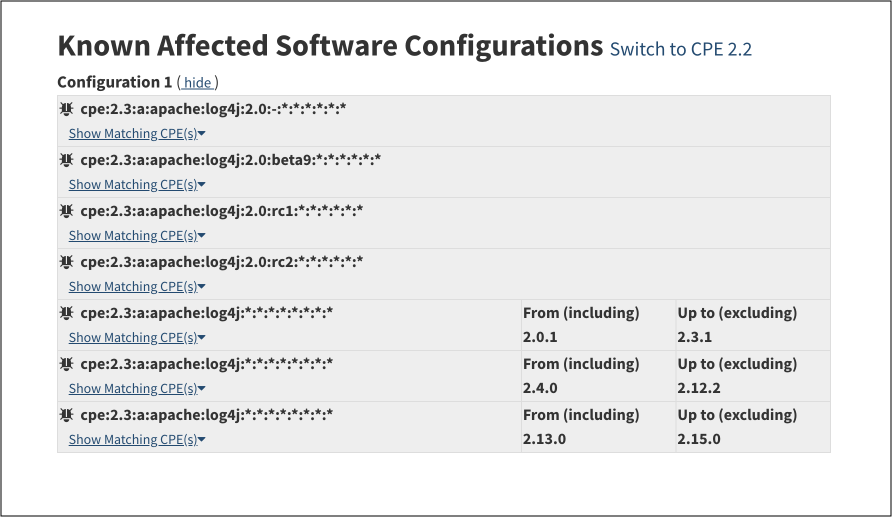
Here is an example: the NVD page for the log4j vulnerability (CVE-2021-44228) only lists affected software without specifying the vulnerable libraries.
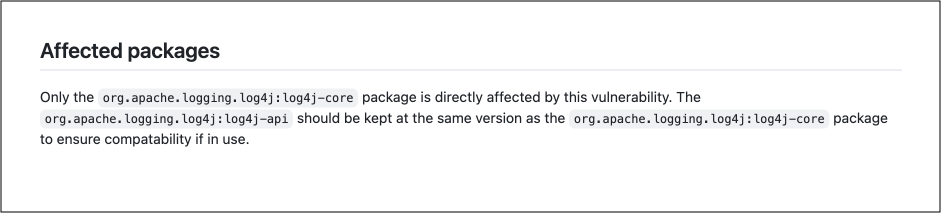
In contrast, other data sources, like the GitHub advisory database, precisely pinpoint that the only affected package is "org.apache.logging.log4j:log4j-core."
- Versioning and naming discrepancy: Many data sources provide a range of vulnerable applications or packages by saying, for example, anything below v2.4.1 is vulnerable. However, this becomes complicated as each manufacturer follows a different naming and versioning schema. For instance, one manufacturer might use a four-digit (or quad-level) version number, while another adopts a three-period separator known as "Semantic Versioning" or "SemVer." This discrepancy in versioning and naming requires a lot of curation and sometimes leads to false matching scenarios.
Enhancing Non-OS Vulnerability Detection
Sysdig has taken several steps to improve the fidelity of package matching:
Incorporating GitHub + GitLab
Sysdig unified detection based in affected-library for Non-OS packages by incorporating security feeds from GitLab Open Source and GitHub Security Advisory Databases. The two advisory databases typically include detailed information about each vulnerable library and it's regularly updated. The information is curated, often with input from the broader security community, ensuring a level of trustworthiness and transparency.
That being said, we will keep using VulnDB dataset to complement vulnerability metadata, for example, by getting the dates when a certain vulnerability is being discovered and disclosed, exploiting data, scores, and summary/description.
Curating results from multiple sources
Sysdig integrates results from over a dozen detection sources. Beyond GitHub and GitLab advisory databases, Sysdig recently started incorporating security feeds from Ruby, Python, and PHP.
Cross-referencing vulnerabilities reported from multiple data sources helps verify their authenticity and severity. In addition, some feeds may provide richer contextual information about vulnerabilities, including potential mitigations, exploitability, or real-world impact. Having multiple feeds can ensure you obtain this detailed context where available.
Proactive vulnerability detection & identification
Sysdig has implemented an automated testing harness for its detections to monitor Recall, Precision, and F1 scores against previous datasets and industry open source benchmarks. This ensures proactive identification of detection variances.
The Outcome
Sysdig's approach of focusing on impacted libraries, instead of the broader software category, has shown tangible results. By prioritizing data from trusted sources like GitHub and GitLab, and integrating other diverse data sources, there has been a notable improvement in detection accuracy and a significant reduction in false positives. For instance:
- Log4shell: Now has three affected libraries, down from 101 previously
- SpringShell: Now has seven affected libraries, down from 21 previously
- CVE-2017-16026: Now has one affected library, down from 13 previously
- CVE-2015-9251: Now has two affected libraries, down from 11 previously
Conclusion
The realm of vulnerability management is complex and ever-evolving. As cyber threats become more sophisticated, it's imperative for vulnerability detection tools to stay a step ahead. Sysdig's recent advancements in refining vulnerability matching emphasize the importance of precision and comprehensive data sourcing. By centering their approach on affected libraries and diversifying their data sources, Sysdig not only improves the detection accuracy, but also instills greater confidence in the vulnerability management process. As the cybersecurity landscape continues to evolve, such innovations underline the importance of continuous adaptation and the relentless pursuit of perfection.