



Falco Feeds extends the power of Falco by giving open source-focused companies access to expert-written rules that are continuously updated as new threats are discovered.

In the following tutorial I will show how to monitor Docker Swarm using Sysdig Monitor. Docker Swarm is the Docker Engine feature for container orchestration and cluster management. It's a fundamental component of Docker's platform – their Enterprise Edition also relies on Swarm as the orchestration scheduler.
\r\r
We have previously discussed the importance of leveraging container orchestration platform metadata to effectively monitor services running on top of moving containers. In an orchestrated environment, we want to understand how services operate globally by aggregating data effectively, but at the same time when troubleshooting an issue we must be able to drill down to specific container or process metrics. This complex process breaks many legacy monitoring tools due to the large number of discrete containers and the multiplicative effect of having of dozens of pieces of metadata for every single metric you collect.
\r\r
Sysdig Monitor now can automatically import and understand Docker Swarm metadata providing best in class Docker Swarm infrastructure and service monitoring capabilities for production users. We can leverage this metadata across host, container, network, and application data, including custom metrics. Before we dive into the details of monitoring Docker Swarm, let's talk about Docker Swarm metadata. How to monitor #Docker #Swarm: metrics and alerts for nodes, tasks and services Click to tweet
\r\r
Monitor Docker Swarm resources and metadata
\r\r
How can a monitoring tool understand the different pieces that comprise your infrastructure, and how your services are architected? Let's go through Docker Swarm's main concepts and resources and see how we can use them as metadata from a monitoring perspective:
\r\r
Monitor Docker Services, stacks, tasks
\r\r
Applications are deployed in Swarm using services. Creating services can be done directly invoking the docker service command, for example:
\r\r$ docker service create --name wordpress \r\r\r
--replicas 2 \r
-p 80:80 \r
--network wpnet \r
--env WORDPRESS_DB_HOST=mariadb \r
wordpress:php7.1-apache\r
But we can use also docker stack that deploys the services defined in a docker-compose like file:
\r\rversion: "3"\r\r\r
services:\r
wordpress:\r
image: wordpress:php7.1-apache\r
ports:\r
- 80:80\r
networks:\r
- wpnet\r
depends_on:\r
- mariadb\r
deploy:\r
replicas: 2\r
update_config:\r
parallelism: 2\r
delay: 10s\r
restart_policy:\r
condition: on-failure\r
environment:\r
WORDPRESS_DB_HOST: "mariadb"\r
WORDPRESS_DB_NAME: "wordpress"\r
WORDPRESS_DB_USER: "wordpress"\r
WORDPRESS_DB_PASSWORD: "changeme"\r
networks:\r
wpnet:\r
external: true\r
# attachable: true # not implemented\r
# run instead: docker network create --driver overlay --attachable wpnet\r
And then deploy it:
\r\r$ docker stack deploy --compose-file wp-stack.yml wordpress\r\r\r
Stacks group a number of services that compose an entire application. For example the WordPress stack above, it would also include the MariaDB database definition.
\r\r
Docker Swarm schedules tasks as the unit of work across the different computing nodes. These tasks finally run the Docker containers. We can find some similarities between Docker Swarm tasks and Kubernetes pods.
\r\r
Sysdig Monitor makes the following new labels available through the Explore tab, graphs and dashboards, alerts and also teams. As I'll show you in the examples below, this allows you to dynamically group your infrastructure and drill down in any pattern that makes sense for your issue at hand.
\r\r
All this metadata is automatically collected from Sysdig agent using Docker API, and requires no additional instrumentation from the user. This is especially powerful since Docker Swarm may be moving or scaling tasks at any time. If you must manually collect metadata, you'll never be in sync with your infrastructure.
\r\r
- \r
swarm.service.name: the service name. You can see your defined services withdocker service ls. \rswarm.service.id: unique service identifier. You can find it doingdocker service inspect your_service. \rswarm.task.id: unique task identifier. \rswarm.task.state: the state of the task, that can be running running, shutdown, and accepted. \rswarm.service.label: contains the labels for the service, including custom ones you might create like thisdocker service update --label-add environment=production wordpress_wordpress. \rswarm.service.label.stack.namespace: this label is particularly interesting because contains the stack name if the service was deployed via stacks. \rswarm.service.task.running: the number of tasks (and therefor containers) running for that service. \rswarm.service.task.desired: the number of replicas we want to have running for that service. \r
\r\r
Monitor Docker Nodes (managers and workers)
\r\r
There are also a number of properties available for nodes. Most of these attributes are also present in the output of docker node ls and docker node inspect the_node.
\r\r
- \r
swarm.node.name: the name of the node, typically matches the hostname. \rswarm.node.id: unique node identifier. \rswarm.node.role: role of the node, either manager or worker. \rswarm.node.state: if the node is ready or down. \rswarm.node.availability: if the node is ready to accept new tasks, or is being drained or paused. \rswarm.node.version: the Docker Engine version. \rswarm.node.label: contains the labels for the node, including custom ones you might create like thisdocker node update --label-add provider=aws your_node. \rswarm.manager.reachability: if the manager Raft status is reachable. \r
\r\r
Exploring and Monitor Docker Swarm cluster infrastructure
\r\r
Using the Sysdig Monitor Explore tab we can browse across your entire infrastructure. A new pre-built grouping is available for Docker Swarm that shows your hosts and containers grouped using swarm.service.name > swarm.task.id > container.id.
\r\r

\rYou can fully customize the grouping, for example by adding a top level with the label swarm.service.label.stack.namespace.
\r\r
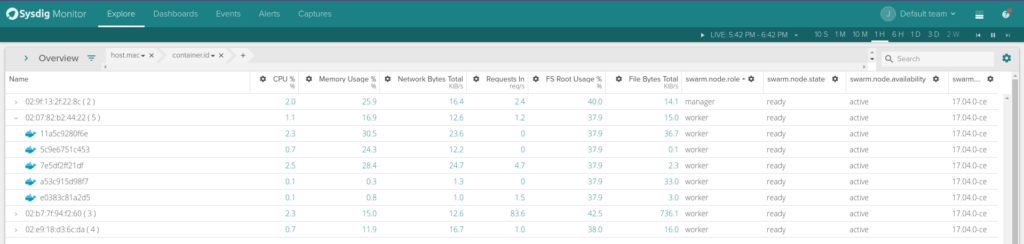
\rYou can also customize the columns shown in the explore table, adding some useful information like swarm.node.role, swarm.node.state or swarm.node.availability.
\r\r
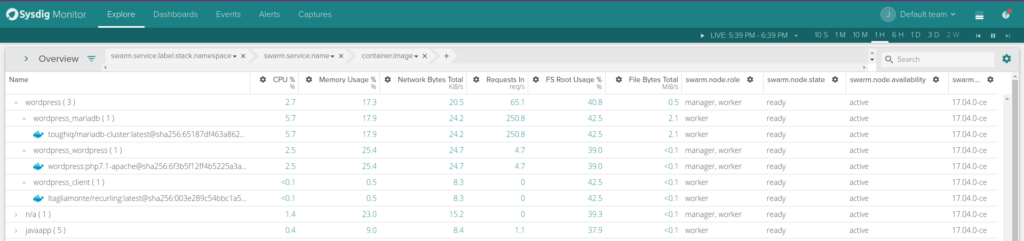
\rWhile the top view gives us a look at our physical infrastructure in terms of nodes, the lower view give us a logical understanding of our applications as deployed by Docker Swarm. We're now in a place where we can monitor Docker swarm from a physical and application perspective.
\r\r
Docker Swarm monitoring views and pre-built templates
\r\r
In addition of Docker Swarm metadata, we wanted to provide some pre-built views of your Docker Swarm cluster: Swarm Overview, Swarm Services and Swarm Tasks.
\r\r

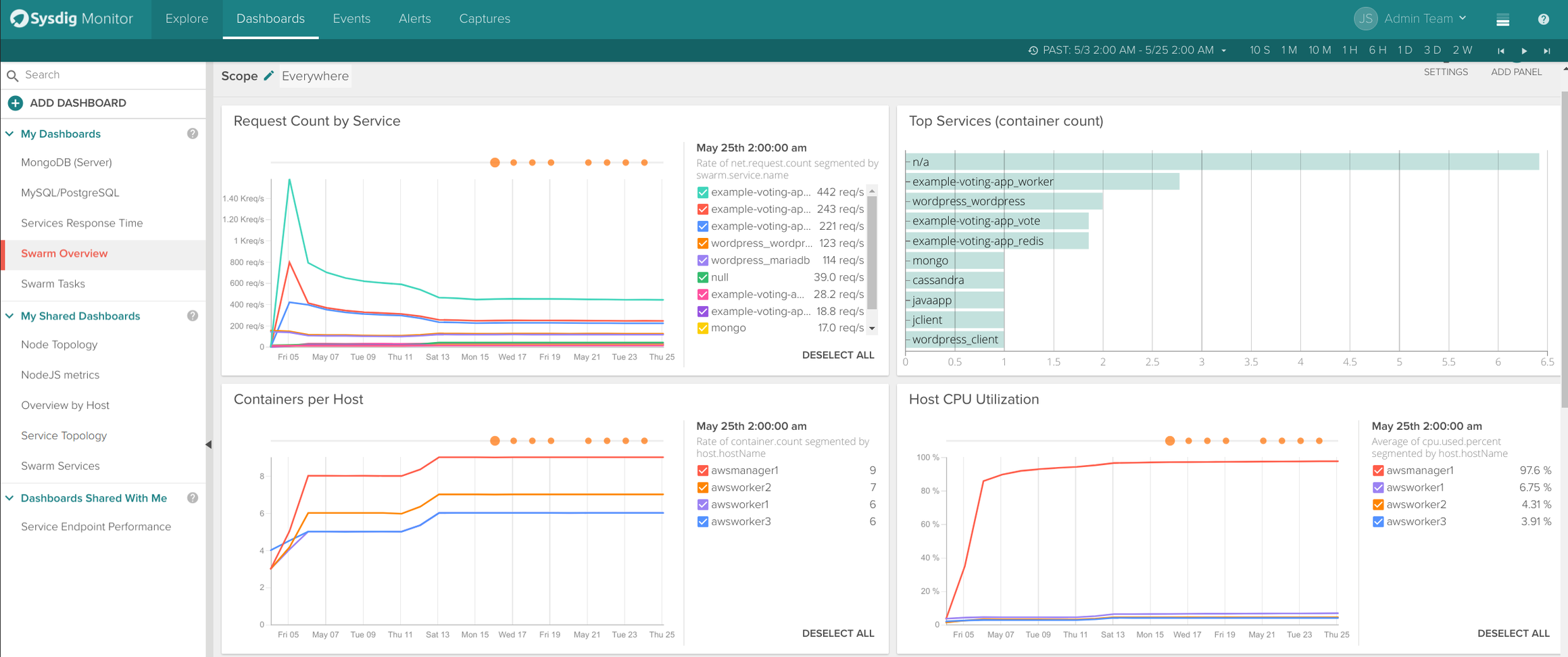
\rThe Swarm Overview dashboard includes relevant metrics like request count by service, top services, containers per host, CPU usage, etc.
\r\r
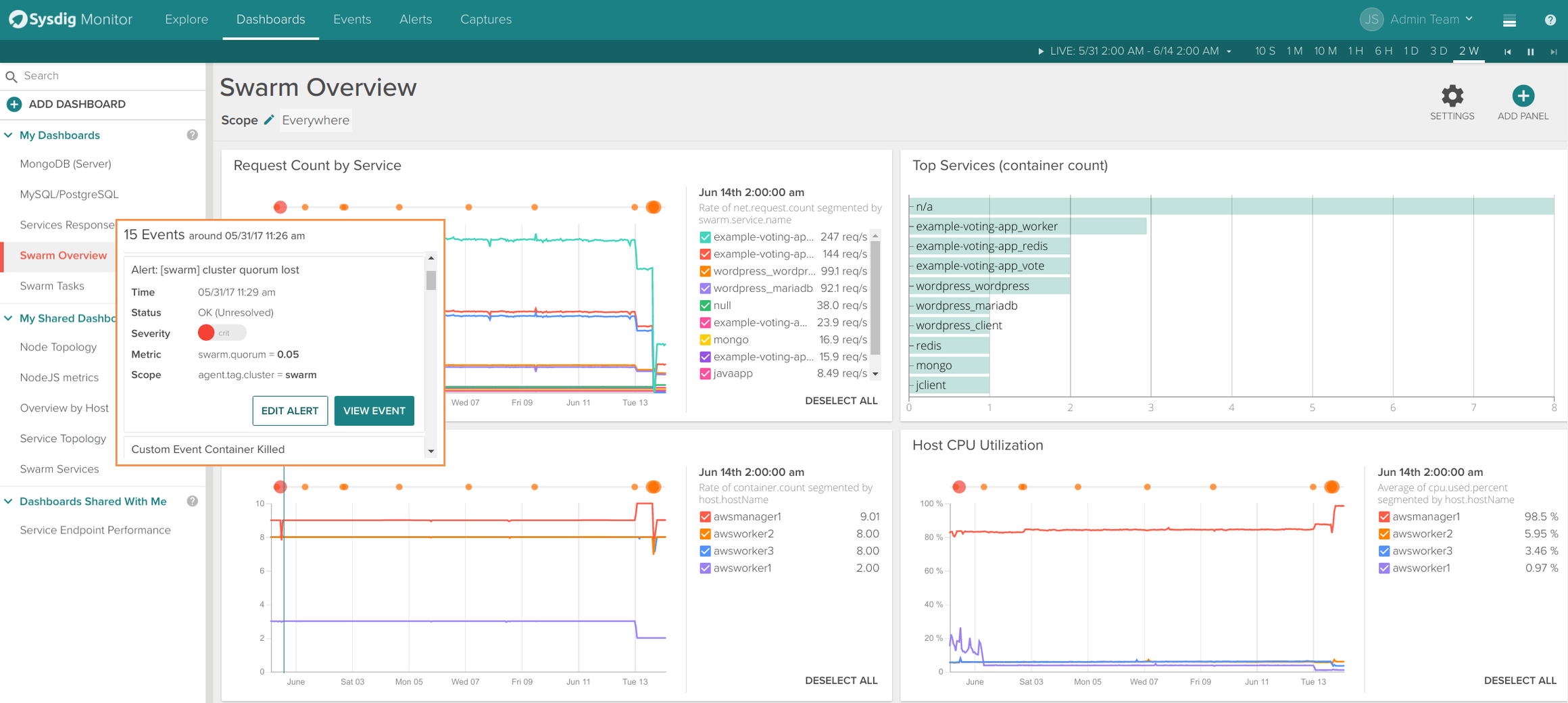
\rThe Swarm Services dashboard includes more service specific metrics like container count, request time or request count. Events from Docker Engine (like a container being killed) and alerts appear overlayed in the time series graphs.
\r\r
\rObviously we couldn't miss one of our most visually appealing features: the topology maps now support Docker Swarm metadata. The following example shows 2 applications: a wordpress service talking to a mariadb service and a java app with 3 databases backends.
\r\r
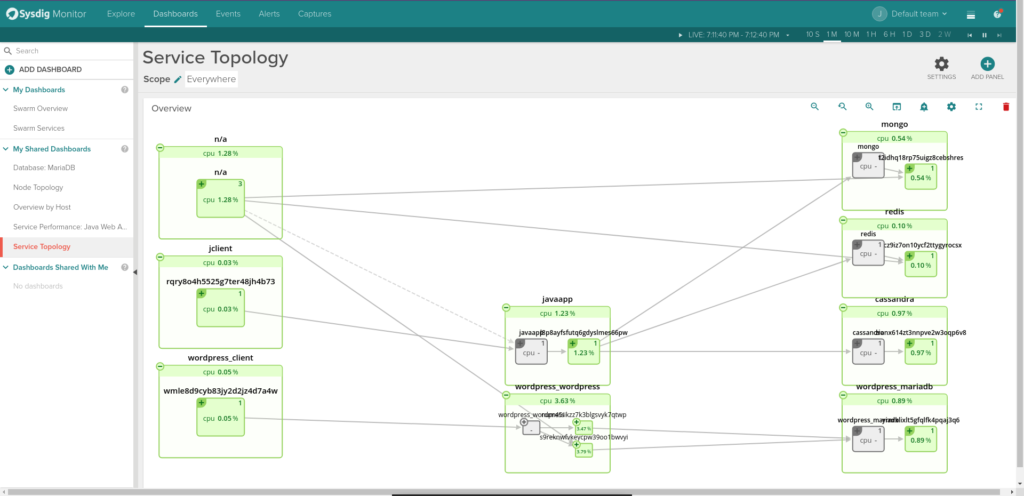
\rFinally, the beauty of the Sysdig approach is that we don't just see containers and tasks, but we also see your application components running inside your containers, without requiring application code changes. For example here are the slowest queries from our MariaDB service:
\r\r

\r\r
Monitor Docker Swarm alerts
\r\r
All this metadata information is available to define alerts and notify us through email, Slack or any other of Sysdig supported channels. Let me show you my 4 favourite alerts for Docker Swarm:
\r\r
Slow service response time
\r\r
Trigger an alert when the any given Swarm Service has an average response time that exceeds a threshold. This is applied automatically to any service defined in Swarm:
\r\r

\r\r
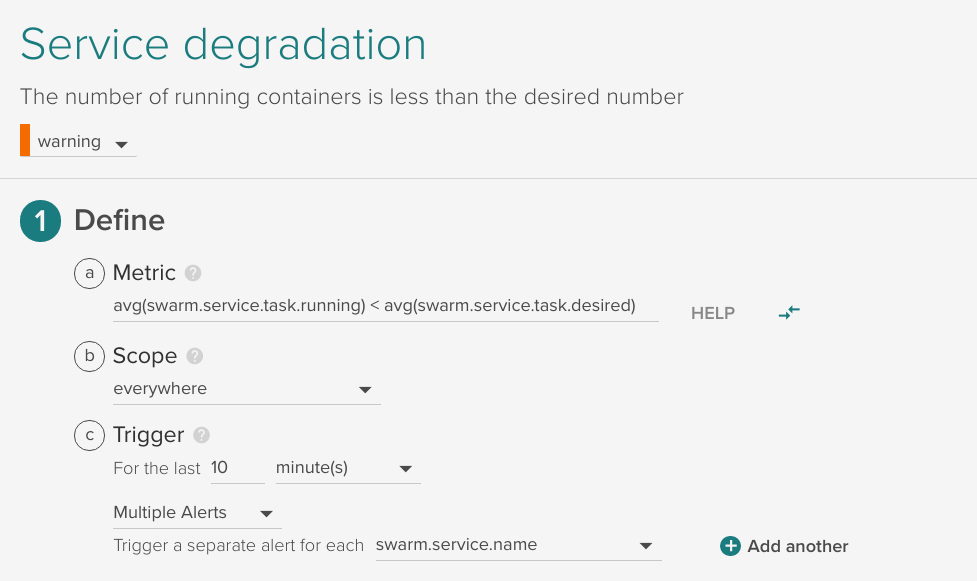
Service degradation
\r\r
Trigger an alert when the number of running tasks is less than the desired for 10 minutes, applied automatically to any service defined in Swarm:
\r\r
\r\r
Service with no running containers
\r\r
Trigger an alert when a defined service has no running containers, applied automatically to any service defined in Swarm:
\r\r

\r\r
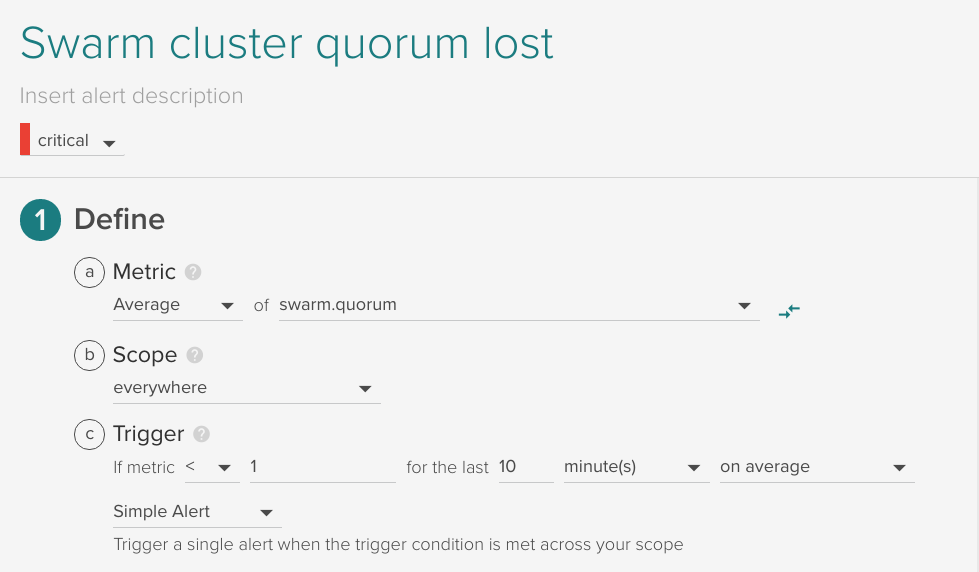
Swarm cluster quorum lost
\r\r
If the Docker Swarm Raft quorum is lost, trigger an alert. This is calculated already as a metric swarm.quorum.
\r\r
\r\r
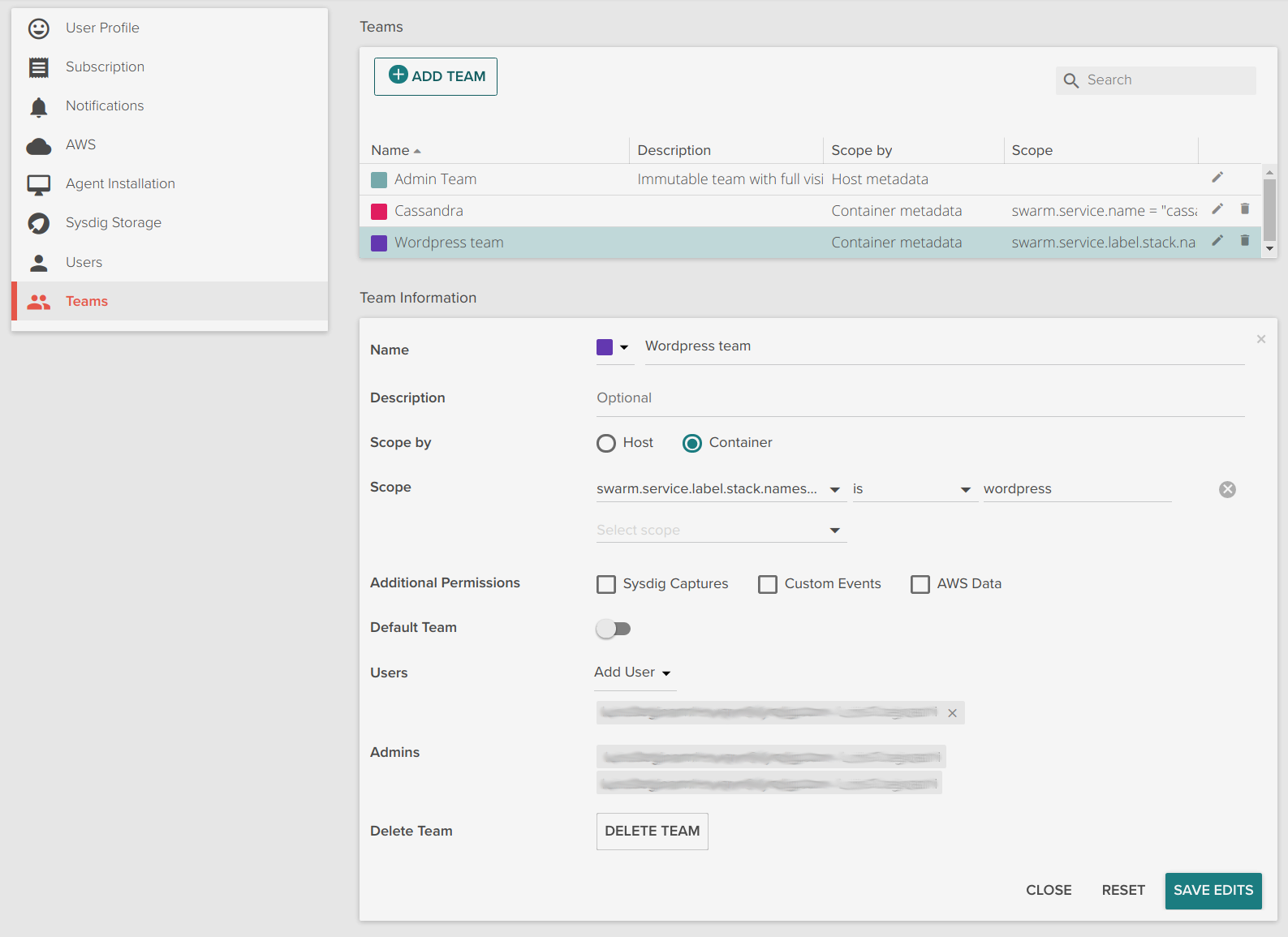
Docker Swarm multi-tenant teams
\r\r
Sysdig Monitor's multi-tenant feature known as teams can also use Docker Swarm metadata to limit the visibility of users. The following is an example of a WordPress team that has access only to the wordpress application defined via a stack.
\r\r
\r\r
Get started!
\r\r
Monitoring Docker Swarm with Sysdig is extremely easy, and provides deep visibility inside containers. Because Sysdig understands Swarm metadata, it can immediately provide the right metrics in the appropriate context and grouping. You are just 2 steps away from monitoring your Docker Swarm cluster:
\r\r
- \r
- Sign up for a 15 day Sysdig Monitor free trial \r
- Deploy Sysdig agents across your Swarm cluster running:
- \r\r
docker run -d --name sysdig-agent --privileged --net host --pid host- \r\r
- -e ACCESS_KEY=YOUR-ACCESS-KEY -e TAGS=example_tag:example_value \r-v /var/run/docker.sock:/host/var/run/docker.sock \r-v /dev:/host/dev -v /proc:/host/proc:ro -v /boot:/host/boot:ro \r-v /lib/modules:/host/lib/modules:ro -v /usr:/host/usr:ro \rsysdig/agent \r
\r\r
From there you'll see your host, container, application, and network metrics all in one place. You'll also be able to correlate Docker events with your metrics so you can get the full picture.