


Falco Feeds extends the power of Falco by giving open source-focused companies access to expert-written rules that are continuously updated as new threats are discovered.

As it is already a tradition, here we are with What's new for Kubernetes 1.14. Here at Sysdig we follow the Kubernetes development cycle closely in order to bring you a sneak peak of the enhancements and new features that Kubernetes 1.14 will contain when released on March 25, 2019.
So, this is what's new: This is what's new in #Kubernetes 1.14 Click to tweet
Kubernetes 1.14 – Editor's pick:
These are the features that look more exciting to us for this release (ymmv):
#116 Support Windows Server containers for K8s
#357 Ability to create dynamic HA clusters with kubeadm
#633 Integrate Kustomize into kubectl
#579 Updated plugin mechanism for kubectl
Core components and nodes
#116 Support Windows Server containers for K8s
Stage: Graduating to stable
Feature group: Windows
A colossal effort spanning almost 3 years, SIG-Windows is promoting the support of Windows Containers to stable. With the introduction of Windows nodes, developers will be able to schedule Windows Server containers and run Windows-based applications on Kubernetes.
There is a complete document detailing the features that are "working today", "going to get included in the roadmap after GA", or "never going to work on a Windows node", going over all this will be far too extensive for this post, but you can keep reading here!
#751 HugePages support
Stage: Graduating to stable
Feature group: Node
A huge page is a memory page that is larger than 4Ki. On x86_64 architectures, there are two common huge page sizes: 2Mi and 1Gi. Some applications can benefit from the use of HugePages, for example database management systems like MySQL or MongoDB.
In order to use HugePages in Kubernetes 1.14, a node can pre-allocate a certain number of HugePages:
apiVersion: v1
kind: Node
metadata:
name: node1
...
status:
capacity:
memory: 10Gi
hugepages-2Mi: 1Gi
allocatable:
memory: 9Gi
hugepages-2Mi: 1Gi
In the example above, 1Gi of memory has been reserved as 512 pre-allocated huge pages sized 2Mi.
A pod can then make a request to consume pre-allocated huge pages:
...
resources:
requests:
hugepages-2Mi: 1Gi
...
You can read more about HugePage memory allocation and consumption here.
#585 RuntimeClass
Stage: Graduating to beta
Feature group: Node
RuntimeClass is a new cluster-scoped resource that surfaces container runtime (Docker, rkt, gVisor, etc) properties to the control plane.
For example:
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
runtimeClassName: myclass
# ...
Will instruct the Kubelet to use the named RuntimeClass to run this pod. This selector is required to dynamically adapt to multiple container runtime engines beyond Docker, like rkt or gVisor.
#793 Promote node OS/Arch labels to GA
Stage: Graduating to stable
Feature group: Node
Since Kubernetes 1.3, which was released two years ago, the kubelet has been labeling the Node object with the host operating system and architecture:
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
Kubernetes 1.14 graduates the OS and arch labels to stable ensuring backwards compatibility for future versions.
#589 Move frequent Kubelet heartbeats to lease API
Stage: Graduating to beta
Feature group: Node
We already covered this feature in the last edition of What's new in Kubernetes 1.13.
node-leases complements the existing NodeStatusintroducing, a lighter, more scalable heartbeat indicator. This feature graduates from alpha to beta state in Kubernetes 1.14.
#689 Support GMSA for Windows workloads
Stage: Alpha
Feature group: Windows
Active Directory is a service that is built-in and commonly used on Windows Server deployments for user and computer identity. This proposal aims to support a specific type of identity profiles provided by the Active Directory server, Group Managed Service Accounts (GMSA) for Windows Server containers.
This will allow an operator to choose a GMSA at deployment time, and run containers using it to connect to existing applications such as a database or API server without changing how the authentication and authorization are managed inside the organization.
An example credential spec YAML for a GMSA-enabled application may look like this:
apiVersion: windows.k8s.io/v1alpha1
kind: GMSACredentialSpec
metadata:
name: "webapp1-credspec"
credspec:
ActiveDirectoryConfig:
GroupManagedServiceAccounts:
- Name: WebApplication1
Scope: CONTOSO
- Name: WebApplication1
Scope: contoso.com
CmsPlugins:
- ActiveDirectory
DomainJoinConfig:
DnsName: contoso.com
DnsTreeName: contoso.com
Guid: 244818ae-87ca-4fcd-92ec-e79e5252348a
MachineAccountName: WebApplication1
NetBiosName: CONTOSO
Sid: S-1-5-21-2126729477-2524075714-3094792973
#727 Kubelet resource metrics endpoint
Stage: Alpha
Feature group: Node
The Kubelet resource metrics endpoint is a new kubelet metrics endpoint which serves metrics required by the cluster-level Resource Metrics API. The proposed design uses the prometheus text format, and provides the minimum required metrics for serving the Resource Metrics API.
The kubelet will expose an endpoint at/metrics/resource/v1alpha1 in prometheus text exposition format using the prometheus client library.
This feature is still in alpha state, its design may be modified or adapted to different metrics formats, like OpenMetrics, in future revisions.
Cluster operations
#213 Provide RunAsGroup feature for containers in a pod
Stage: Graduating to beta
Feature group: Authorization
Using the runAsGroupfield inside the securityContext section in a Pod definition, you can now specify the primary groups that will be assigned to the processes inside the pod containers. Note that you can also configure the fsGroupfield inside securityContextto specify supplementary group IDs.
This feature has to be enabled using the Feature Gate RunAsGroup. For Kubernetes 1.14 this feature is not only graduated to beta, but also enabled by default.
#357 Ability to create dynamic HA clusters with kubeadm
Stage: Alpha
Feature group: Cluster lifecycle
You can set up a Kubernetes HA cluster:
- With stacked control plane nodes, where etcd nodes are colocated with control plane nodes
- With external etcd nodes, where etcd runs on separate nodes from the control plane
This kubeadmversion introduces automatic certificates copy, eliminating the need for manually copying between the nodes and completing the kubeadm solution for creating HA clusters. The current solution also secures the certificate transmission between nodes using an ephemeral encryption key.
Read more about this new feature here.
#564 Add pod priority and preemption
Stage: Graduating to stable
Feature group: Scheduling
The Pod priority is a fundamental piece of information for the Kubernetes scheduler. It allows to:
- Schedule more important Pods fist
- Evict the less important Pods when a cluster or node is getting out of resources
You can define a PriorityClass like this (the higher the value, the higher priority):
apiVersion: scheduling.k8s.io/v1beta1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "This priority class should be used for XYZ service pods only."
And then assign this PriorityClassin the spec of a pod: priorityClassName: high-priority
This feature has been present in different stages since Kubernetes 1.8, but in Kubernetes 1.14 is finally graduating to stable.
#789 Harden the default RBAC discovery clusterrolebindings
Stage: New feature (stable)
Feature group: Authorization
Up until now, the system:discoveryand system:basic-user ClusterRoleBindings contain the system:unauthenticated subject group:
kubectl describe clusterrolebinding system:discovery
Name: system:discovery
Labels: kubernetes.io/bootstrapping=rbac-defaults
Annotations: rbac.authorization.kubernetes.io/autoupdate: true
Role:
Kind: ClusterRole
Name: system:discovery
Subjects:
Kind Name Namespace
---- ---- ---------
Group system:authenticated
Group system:unauthenticated
This is a potential security risk. Starting from Kubernetes 1.14, discovery will be removed from the set of APIs which allow for unauthenticated access by default, improving privacy for CRDs and the default security posture of default clusters in general.
#580 Pod ready ++
Stage: Graduating to stable
Feature group: Network
This feature introduces an extension point for external feedback on pod readiness defined by the user. Using these new readiness conditions, you can configure different endpoints to check if the pod is ready to start accepting requests.
The pod readiness definition will change to:
Pod is ready == containers are ready AND conditions in ReadinessGates are True
The kubelet will evaluate conditions specified in ReadinessGates and update the pod "Ready" status. For example, in the following pod spec:
kind: Pod
spec:
readinessGates:
- conditionType: www.example.com/feature-1
- conditionType: www.example.com/feature-2
status:
conditions:
- lastProbeTime: null
lastTransitionTime: 2018-01-01T00:00:00Z
status: "False"
type: Ready
- lastProbeTime: null
lastTransitionTime: 2018-01-01T00:00:00Z
status: "False"
type: www.example.com/feature-1
- lastProbeTime: null
lastTransitionTime: 2018-01-01T00:00:00Z
status: "True"
type: www.example.com/feature-2
containerStatuses:
- containerID: docker://xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
ready : true
The status of www.example.com/feature-1 is false, hence the pod is not ready.
#757 Pid limiting
Stage: Graduating to beta
Feature group: node
Pids are a fundamental resource on Linux hosts. It is trivial to hit the task limit without hitting any other resource limits and cause instability to a host machine.
Administrators require mechanisms to ensure that user pods cannot induce pid exhaustion that may prevent host daemons (runtime, kubelet, etc) from running.
To enable pid isolation from node to pods, the SupportNodePidsLimit feature gate is proposed. If enabled, pid reservations may be supported at the node allocatable and eviction manager subsystem configurations.
Configuration Management
#555 Server-side apply
Stage: Alpha
Feature group: API machinery
kubectl apply is a core part of the Kubernetes declarative config workflow. So far, the logic for these operations has been handled by the client side tools, which has lead to several corner cases where this operation behaves in unexpected ways. You can read more about the current implementation problems here
This features aim to move the logic for the applyoperation and declarative object management to the apiserver, fixing most of these workflow pitfalls and also making the operation accessible directly from the API (for example using curl), without strictly requiring kubectlor a Golang implementation.
#633 Integrate Kustomize into Kubectl
Stage: Stable
Feature group: Client
Declarative specification of Kubernetes objects is the recommended way to manage Kubernetes production workloads, however gaps in the kubectl tooling force users to write their own scripting and tooling to augment the declarative tools with preprocessing transformations.
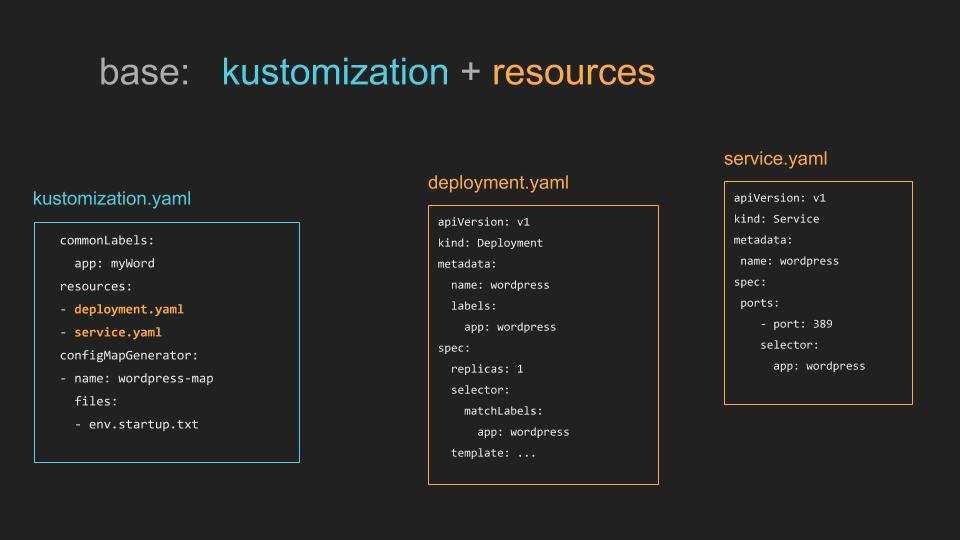
A typical example of the workflow problems that kustomizeis trying to solve is how to automate the creation of ConfigMaps or Secrets from the files that contain the actual authoritative information.
With the new kustomize subcommand you can use akustomization.yaml file to reference config files, generate config from those files, and allow the user to apply transformations to configs. You can learn more about kustomizehere.
#504 Support configurable pod resolv.conf
Stage: Graduating to stable
Feature group: Network
By default, the resolv.confin a pod is generated by the kubelet copying the search and nameserver fields present on the node where the pod is running. This features gives the users the option to create a per-pod cluster-wide DNS configuration. Depending on the DnsPolicy that you set, you can inherit some parameters from the base DNS config or just create your own resolv.conf from scratch.
For example, this configuration:
# Pod spec
apiVersion: v1
kind: Pod
metadata: {"namespace": "ns1", "name": "example"}
spec:
...
dnsPolicy: Custom
dnsConfig:
nameservers: ["1.2.3.4"]
searches:
- ns1.svc.cluster.local
- my.dns.search.suffix
options:
- name: ndots
value: 2
- name: edns0
Will result in the following resolv.conf inside the pod, regardless of the hosting node.
nameserver 1.2.3.4
search ns1.svc.cluster.local my.dns.search.suffix
options ndots:2 edns0
You can read more about this feature here.
#579 Updated plugin mechanism for kubectl
Stage: Graduating to stable
Feature group: Client
The alpha plugin system in kubectl presents a few limitations:
- Plugin scripts and executables must exist in a predetermined location
- Requires a per-plugin metadata file for interpretation
- It does not provide a clear way to override existing command paths or provide additional subcommands without overriding the top-level command.
The redesigned plugin mechanism gets rid of all these limitations, users just need drop an executable in their PATH, and they are then able to use that plugin with kubectl
A plugin's filename determines the plugin's intention, for example the kubectl-sysdig_capture plugin will be invoked as:
kubectl sysdig-capture
#692 Publish CRD OpenAPI schema
Stage: Alpha
Feature group: API machinery
In CustomResourceDefinition (CRD) we allow CRD author to define OpenAPI v3 schema, to enable server-side validation for CustomResources (CR). The validation schema format is compatible for creating OpenAPI documentation for CRs, which can be used by clients like kubectl to perform client-side validation (e.g. kubectl create andkubectl apply), schema explanation (kubectl explain), and client generation. This enhancement proposes using the OpenAPI v3 schema to create and publish OpenAPI documentation for CRs.
Storage
#121 Durable (non-shared) local storage management
Stage: Graduating to stable
Feature group: Storage
Node-local storage has been used for ephemeral volumes so far, where the data only persists during the lifetime of the pod.
There is, however, an increasing demand for using local storage as persistent volumes, especially for distributed file systems and databases such as GlusterFS and Cassandra.
The main motivations for using persistent local storage include:
- Performance: Local SSDs achieve higher IOPS and throughput than many remote storage solutions.
- Cost: Operational costs may be reduced by leveraging existing local storage, especially in bare metal environments. Network storage can be expensive to setup and maintain, and it may not be necessary for certain applications.
You have the full specification details and example configuration snippets in the feature page.
#556 Add resizing support to CSI volumes
Stage: Alpha
Feature group: Storage
In the last "_What's new" _article we already discussed CSI volume plugins and their ability to expose arbitrary (out-of-tree) storage systems to Kubernetes. This alpha storage enhancement seeks to achieve feature parity with in-tree volumes implementing support for resizing of CSI volumes.
To support resizing of CSI volumes an external resize controller will monitor all PVCs. If a PVC meets following criteria for resizing, it will be added to controller's workqueue. You can read the specification details for this feature here.
#557 Kubernetes CSI topology support
Stage: Graduating to beta
Feature group: Storage
Topology allows Kubernetes to make intelligent decisions when dynamically provisioning volumes by getting scheduler input on the best place to provision a volume for a pod. In multi-zone clusters, this means that volumes will get provisioned in an appropriate zone that can run your pod, allowing you to easily deploy and scale your stateful workloads across failure domains to provide high availability and fault tolerance.
As we have mentioned in the previous enhancement, to achieve feature parity with in-tree storage plugins, the topology capabilities will be implemented for CSI out-of-tree storage plugins.
#559 Provide environment variables expansion in sub path mount
Stage: Alpha
Feature group: Storage
There is a limitation with the current implementation of the node-local volume mounts:
- If 2 or more pods run on the same host writing the same log file names to the same volume, they will clash.
- Using the
subPathis a neat option but because thesubPathis "hardcoded" ie.subPath: mySubPathit does not enforce uniqueness.
This features aims to alleviate this limitations allowing environment variable expansions: subPath: $(MY_VARIABLE)
For example:
volumeMounts:
- name: workdir1
mountPath: /logs
subPathExpr: $(POD_NAME)
You can learn more about this feature proposal here.
#565 CSI Block storage support
Stage: Graduating to beta
Feature group: Storage
We already covered this feature in the last release of What's new in Kubernetes 1.13.
The ability to use a raw block device without a filesystem abstraction allows Kubernetes to provide better support for high performance applications that need high I/O performance and low latency, like databases.
This feature is also part of the push to achieve feature parity for CSI out-of-branch storage plugins for Kubernetes.
#596 CSI inline volume support
Stage: Alpha
Feature group: Storage
CSI volumes can only be referenced via PV/PVC today. This works well for remote persistent volumes. This feature introduces the possibility to use CSI volumes as local ephemeral volumes as well.
A pod spec with an ephemeral inline CSI volume can be defined like this:
apiVersion: v1
kind: Pod
metadata:
name: some-pod
spec:
containers:
...
volumes:
- name: vol
csi:
driver: inline.storage.kubernetes.io
volumeAttributes:
foo: bar
This feature is also part of the push to make CSI volumes first-class storage providers for Kubernetes. You can learn more here.
#603 Pass pod information in CSI calls
Stage: Graduating to beta
Feature group: Storage
The CSI out-of-tree storage driver may opt-in to receive information about Pod that requested a volume in NodePublish request, such as Pod name and namespace.
The CSI driver can use this information to authorize or audit usage of a volume or generate content of the volume tailored to the pod.
#625 In-tree storage plugin to CSI driver migration
Stage: Alpha
Feature group: Storage
As the CSI Spec moves towards GA and more storage plugins are being created and becoming production ready, the Kubernetes team wants to migrate in-tree plugin logic to use CSI plugins instead.
This is motivated by the fact that Kubernetes is currently supporting two versions of each plugin (one in-tree and one CSI). The plan is to eventually transition all storage users to CSI.
In order to smooth this change there has to be a clear migration path, providing seamless upgrade, before the internal in-tree APIs are finally deprecated.
This feature is still in alpha state, but you can read more about the migration process here.
Cloud Providers
#670 Support out-of-tree vSphere cloud provider
Stage: Beta
Feature group: Cloud Provider
Build support for the out-of-tree vSphere cloud provider. This involves a well-tested version of the cloud-controller-manager that has feature parity to the kube-controller-manager.
This feature captures mostly implemented work already completed in the Cloud Provider vSphere repository.
That's all folks! Exciting as always, get ready to upgrade your clusters if you are intending to use any of these features.
If you liked this, you might want to check out our previous What's new in Kubernetes editions:
And, if you enjoy keeping up to date with the Kubernetes ecosystem, subscribe to our container newsletter, a monthly email with the coolest stuff happening in the cloud-native ecosystem.