


Falco Feeds extends the power of Falco by giving open source-focused companies access to expert-written rules that are continuously updated as new threats are discovered.

Today we're very excited to announce a partnership with Amazon to support Fargate in Sysdig's product line. We are also announcing that Falco, the world's most popular runtime security tool for containers, will soon be able to work on Fargate. This is an important milestone. For the first time, Fargate users will enjoy the benefit of deep instrumentation. This will make their workloads more secure, reliable, and efficient.
This blog post will explain why this problem is important and how Amazon and Sysdig solved it. It will also give you an initial glimpse of Falco running on Fargate.
But let's start from the beginning.
What is deep instrumentation? Why do we need it?
Deep instrumentation is the ability to observe running processes at a level of granularity that makes it possible to see individual actions, for example, opening a file, reading or writing data to disk, establishing a network connection, sending or receiving network data.
Deep instrumentation is required by many important classes of tools that are critical to keeping your applications safe and stable. Runtime workload protection, troubleshooting, EDR, root cause investigation, dependency mapping, file integrity monitoring all depend on deep instrumentation.
Falco – Cloud Native Runtime Security
Falco is a very good example of a tool that needs deep instrumentation. Falco is a behavioral activity monitor designed to detect anomalous activity in your applications. Falco lets you continuously monitor and detect container, application, host, and network activity, all in one place, with one set of rules. Falco is a CNCF project and the de facto runtime security tool for Kubernetes. Falco is also at the core of Sysdig Secure.
Currently, Fargate users cannot run Falco to protect their workloads. This is a gap the AWS team noted in their container security survey and worked closely with us to discuss different options for Falco support on AWS Fargate.
Current deep instrumentation approaches
When talking about deep instrumentation, there are two important factors to consider: accuracy and overhead.
There are several approaches to the problem. In this blog post, I will discuss three of them that are by far the most popular on Linux and containers.
1. LD_PRELOAD
This technique consists of using an environment variable, LD_PRELOAD, to direct the operating system to load a different version of the libc dynamic library. Libc is used by the majority of the programs to invoke kernel functions like open() or connect(). The version loaded with LD_PRELOAD may contain additional instrumentation to record every call to these functions and their parameters.
LD_PRELOAD is very efficient, but it's not accurate. The reason is that many programs, for example statically linked C programs or anything written in go, don't use the libc dynamic library and call the kernel directly. LD_PRELOAD will be completely blind to these types of programs. Additionally, since LD_PRELOAD is a user-level technique, it can be easily fooled by a motivated attacker, for example calling system calls directly in assembly code.
2. ptrace
ptrace is one of the most advanced (and complicated!) system calls exported by the Linux kernel. It makes it possible for a process with the right privileges to pause, introspect, modify and control another process. Many tools you use on a regular basis are based on ptrace. One of them, for example, is gdb, the GNU debugger.
One of the cool features of ptrace is PTRACE_SYSCALL, which allows a process to stop another one upon the execution of a system call and capture the system call arguments. Since services exposed by the OS, like File I/O and networking, are accessed through system calls, this is a deep instrumentation nirvana and is used to implement tools like strace.
ptrace is very accurate, but it's not efficient. It's accurate because it's language and stack independent (system calls are the same in any language). Also, because the information is produced by the operating system kernel, and the kernel cannot be fooled (at least not easily). However, using PTRACE_SYSCALL is somewhat equivalent to setting a debugger breakpoint for every system call. So accurate, but not fast.
3. Kernel instrumentation
This technique consists in going down to the kernel, with traditional (and more invasive) methods based on kernel modules, or with more modern, less invasive methods like eBPF, which is based on a virtual machine that can run code safely inside the kernel.
Kernel instrumentation is efficient and accurate. It's efficient because collecting the actions in the kernel guarantees the lowest overhead. It's accurate because, as we know, "the kernel never lies".
For this reason, Falco has been based on this technique. And Sysdig's commercial products, Sysdig Secure and Sysdig Monitor are based on this technique as well.
What's the problem with Fargate?
Fargate offers a great value proposition to the AWS users: forget about virtual machines and just provision containers. Amazon will take care of the underlying hosts, so you will be able to focus on writing software instead of maintaining and upgrading a fleet of Linux instances.
However, deep instrumentation on Fargate has been challenging:
- Kernel instrumentation is not possible on Fargate, because Fargate, by design, doesn't expose access to the host
- ptrace is not available on Fargate
- Because of these limitations, LD_PRELOAD is the only possible approach, which is less than ideal based on the invasiveness and lack of accuracy we discussed before
However, things are going to change!
Big News! Fargate now supports ptrace
Yes, you are reading it right. Amazon today is announcing the release of a new version of the Fargate platform (1.4) that includes support for ptrace.
This is a game changer. Not only you will now be able to use debuggers like gdb (finally!) and troubleshooting tools like strace, but at last, there's going to be a solid framework for deep instrumentation, so expect more and more tools to become available on Fargate.
Thanks to the close relationship between Amazon and Sysdig, we had the opportunity to work with the AWS team on the specification of this feature, and we could test it before its release. This gave us a chance to extend Falco to fully support Fargate using ptrace.
Showcasing Falco support for Fargate
Here's a preview of Falco working on serverless.
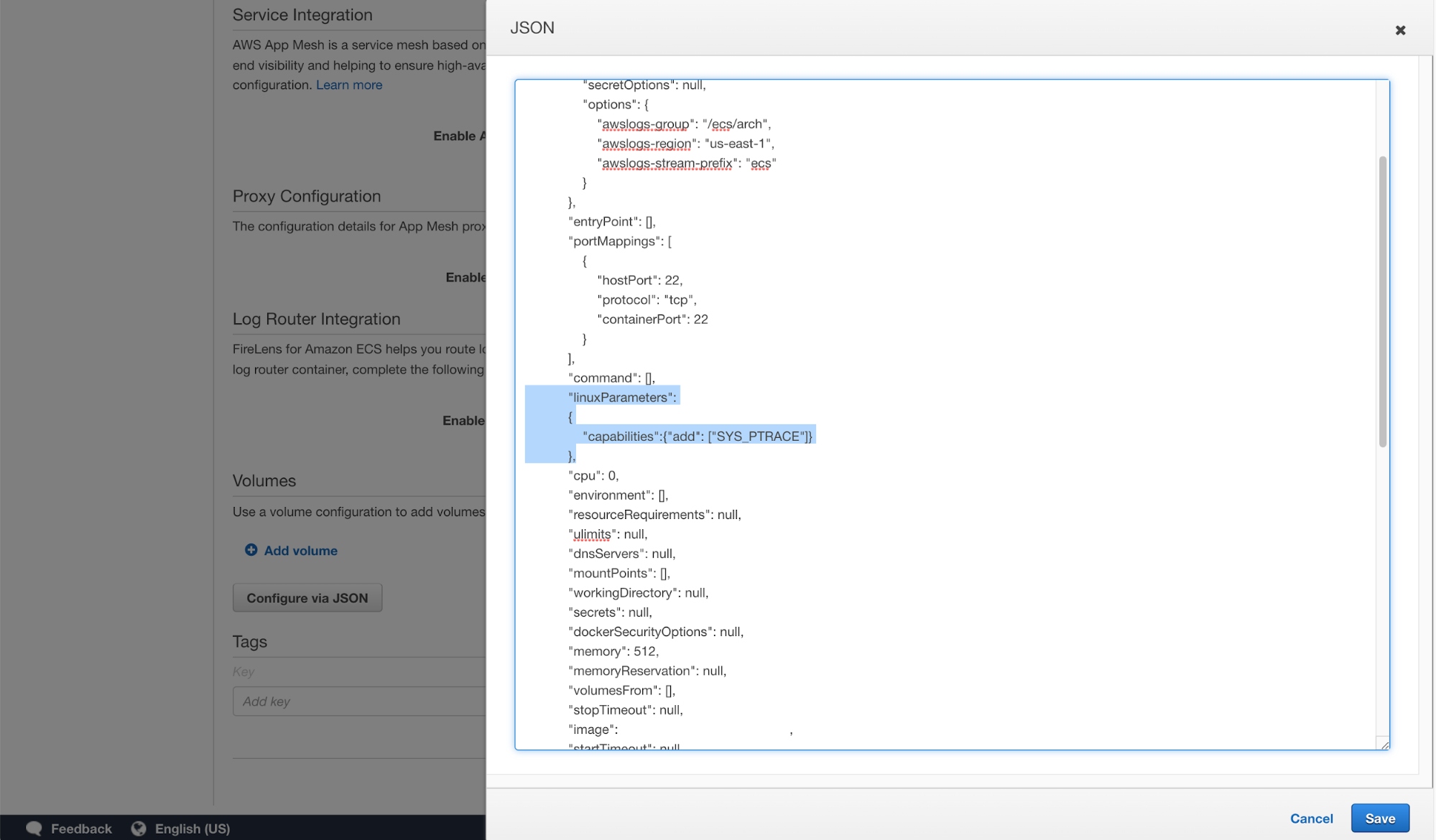
In the JSON configuration of my task, I'm adding SYS_PTRACE capability. This is one of the standard Linux capabilities that we can traditionally enable for docker containers.
Now I'm going to run an ubuntu container inside my task and, for the sake of this demo, I'm going to run a manually compiled version of Falco. I'm going to run Falco with the -u command line flag, which instructs it to collect events using ptrace instead of using a kernel module:
./falco -u -r ../../../rules/falco_rules.yaml
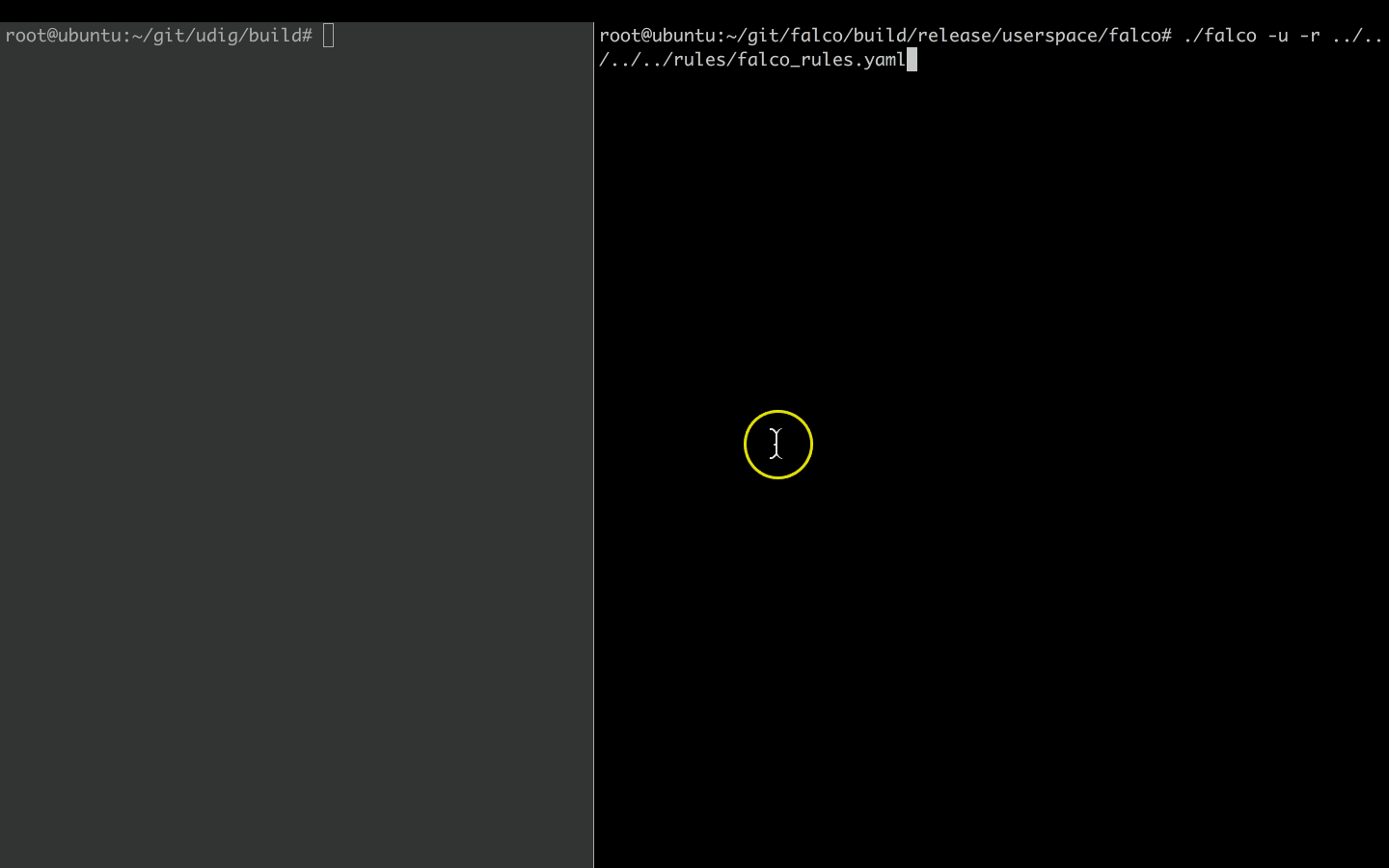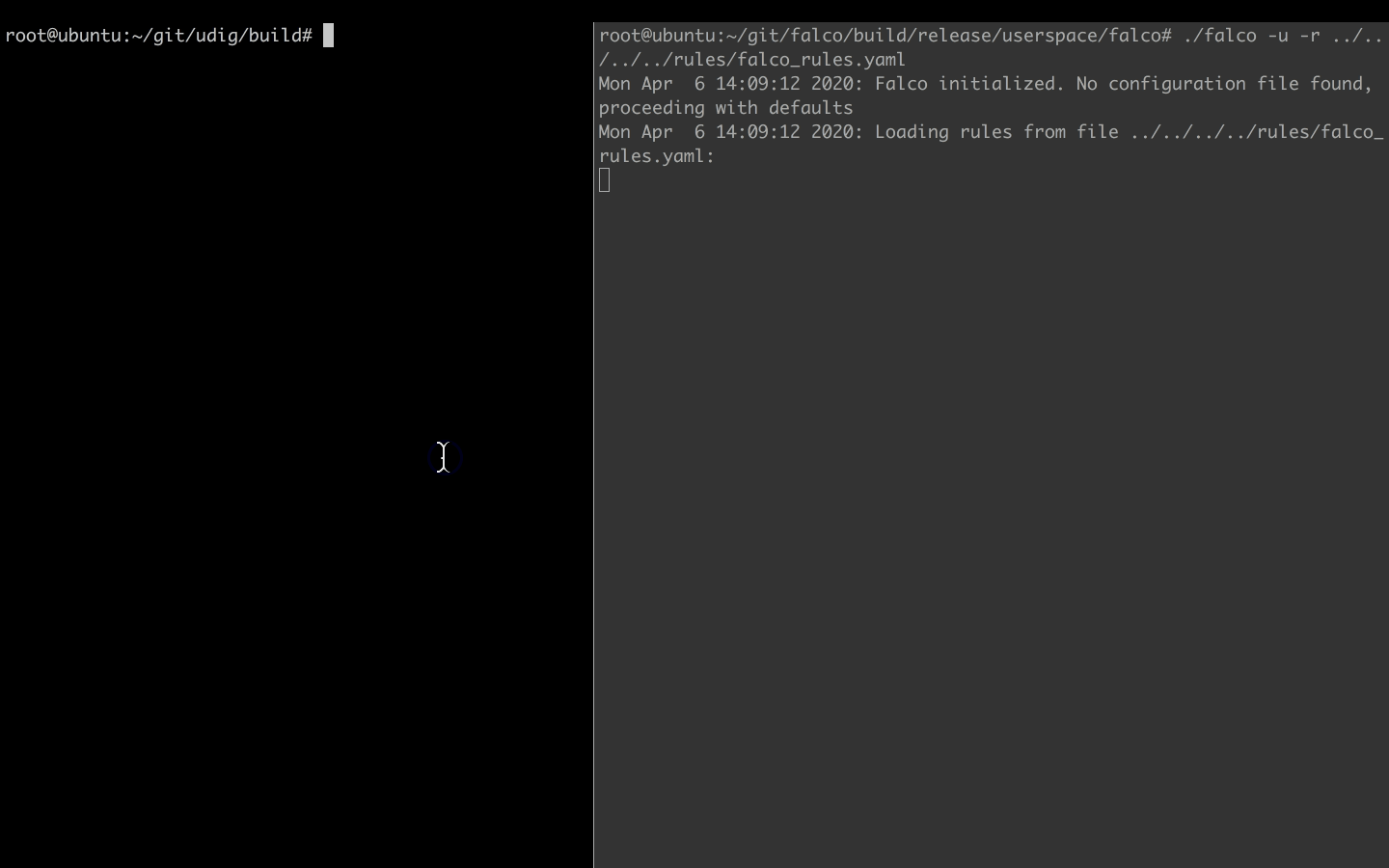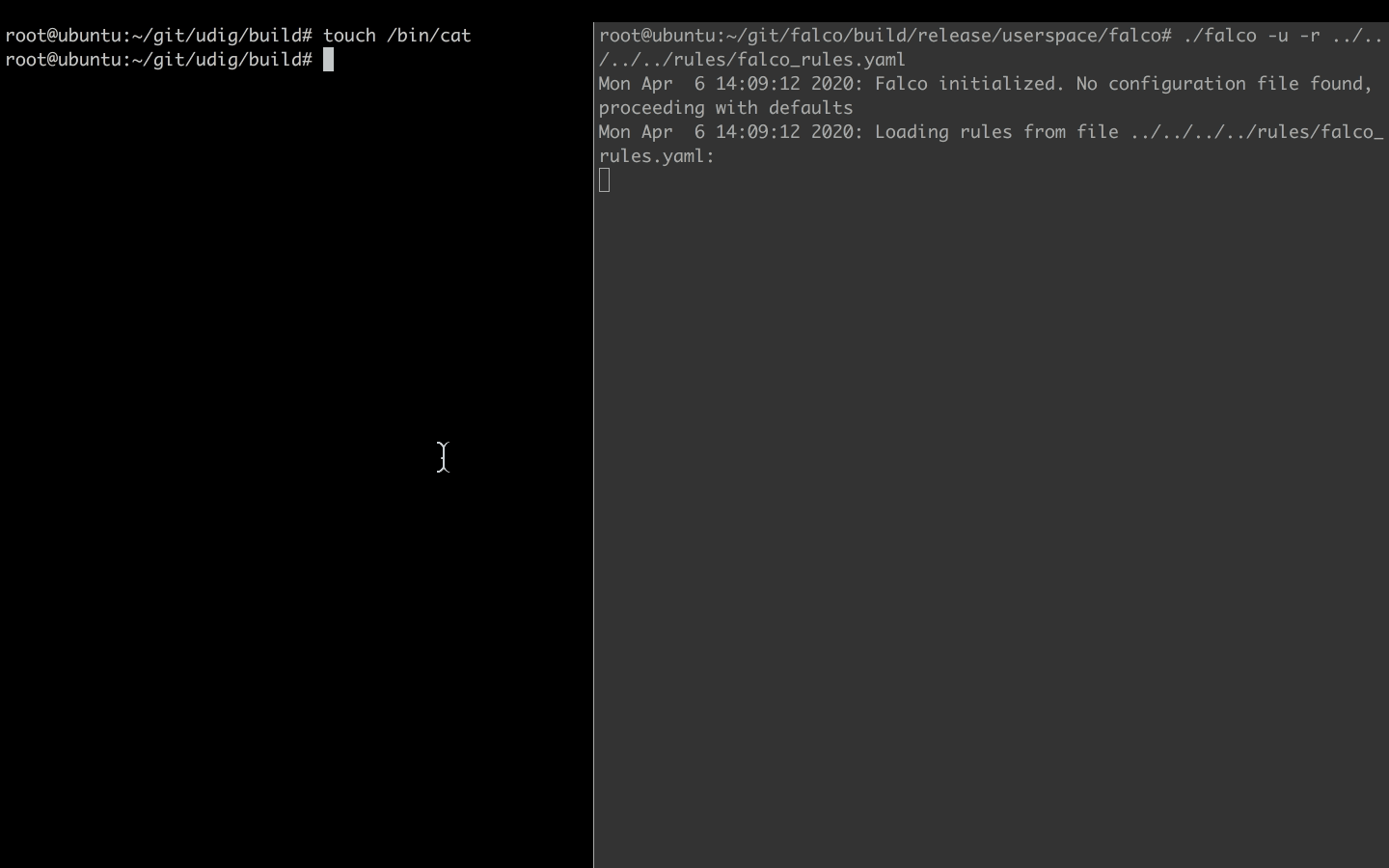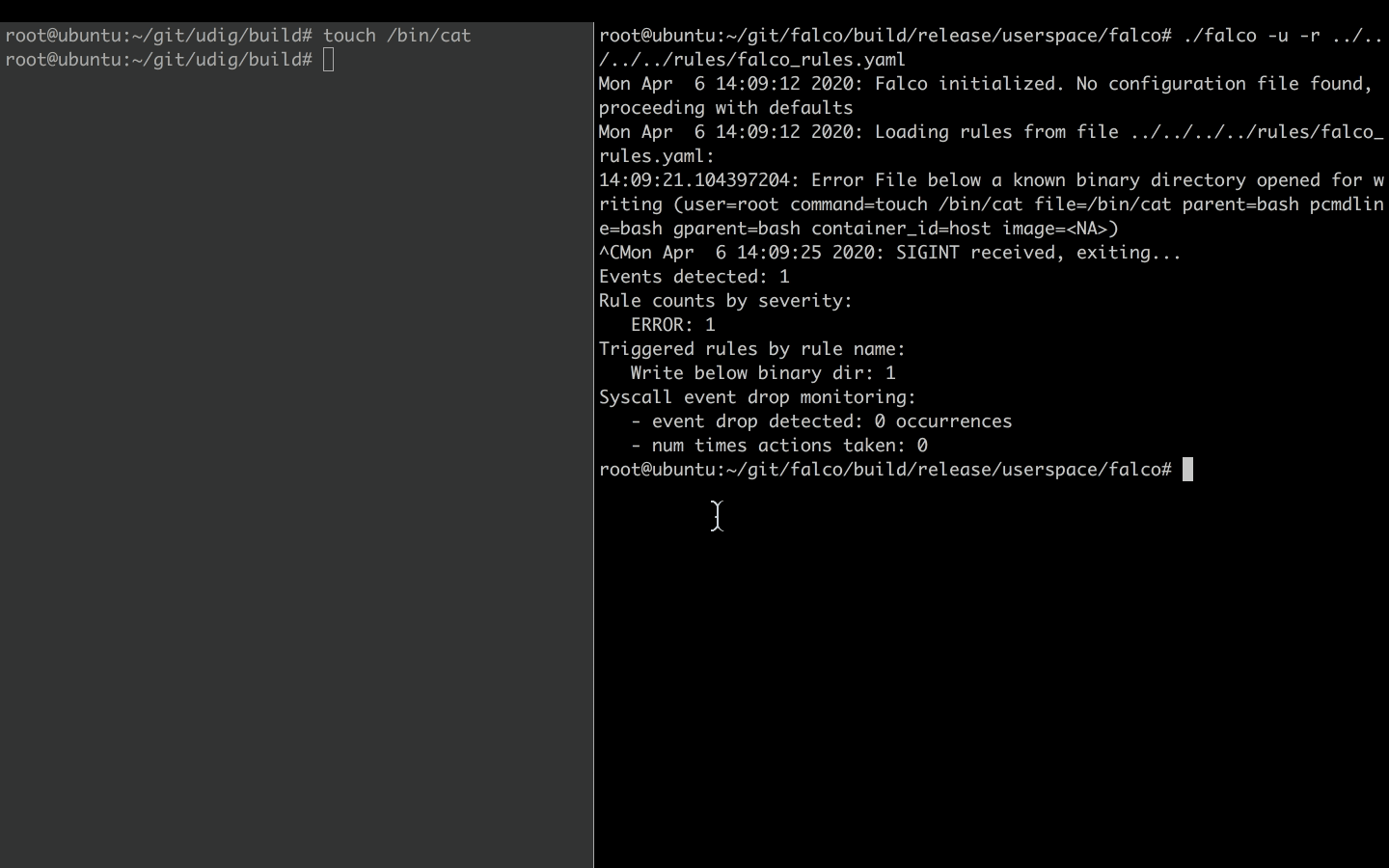
In the other shell, we try to modify a binary file.
touch /bin/cat
And voila, without hesitation, Falco lets us know about the suspicious activity.
Wait. You just said ptrace is slow!
Yes, ptrace is slow. So slow that using tools like strace in production is challenging because they introduce substantial overhead on the monitored application. But at Sysdig we take performance very seriously (we know how important it is for our users when they run workloads in production!), so you don't really expect us to settle on meh performance, right? :-)
Thanks to early access from Amazon, we had a chance to work on a series of optimizations. The result is a technology that uses ptrace, but achieves the full functionality of our kernel instrumentation without substantial additional overhead. This is something that we plan to release in the near future for our users, so stay tuned!
UPDATE: See more on Falco, ptrace, and AWS Fargate on GitHub.