



Falco Feeds extends the power of Falco by giving open source-focused companies access to expert-written rules that are continuously updated as new threats are discovered.

Kubernetes has broken down barriers as the cornerstone of cloud-native application infrastructure in recent years. In addition, cloud vendors offer flexibility, speedy operations, high availability, SLAs (service-level agreement) that guarantee your service availability, and a large catalog of embedded services. But as organizations mature in their Kubernetes journey, monitoring and optimizing costs is the next stage in their cloud-native transformation.
Estimating the costs of the workloads running on Kubernetes clusters across your cloud providers, and correlating these costs with your application performance metrics, is a need for every company running its applications in the cloud.
Cloud billing reports don't have Kubernetes context. That means users aren't able to group costs or disseminate it by workloads, and are unable to charge back costs to teams or identify areas of overspend.
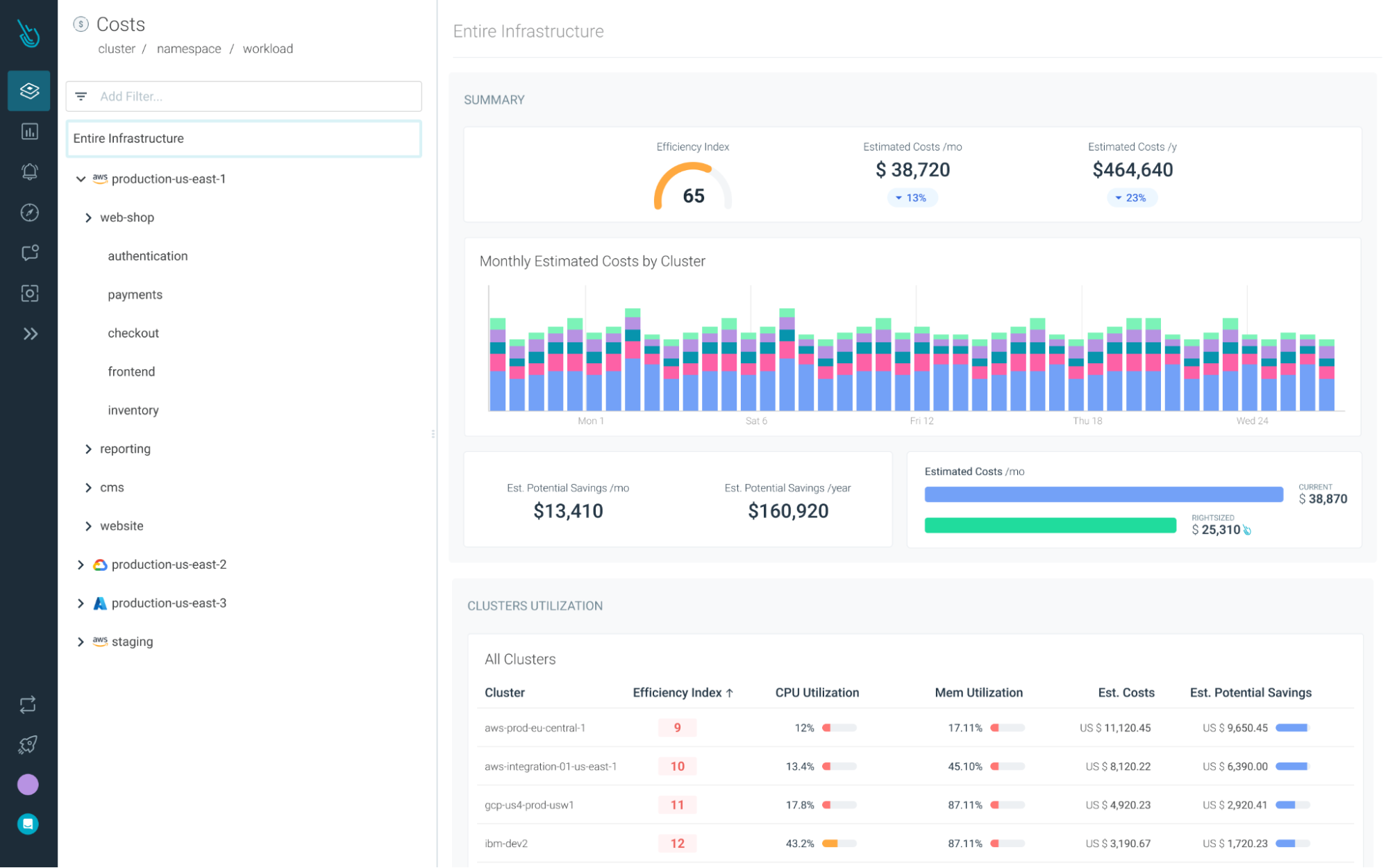
To address these gaps in Kubernetes cost monitoring, we are excited to announce Cost Advisor, a new product in Sysdig Monitor that will give you visibility into Kubernetes costs and automatically help you identify areas to reduce them. With Cost Advisor you can reduce wasted spending by 40% on average.
Kubernetes cost visibility
When it comes to control and associate costs with the resource consumption in Kubernetes, it's tough and complex for any organization. The lack of visibility on the costs of the Kubernetes resources per usage, plus some of the bad habits users have (like tending to oversize resource allocation), create challenging situations.
According to the CNCF FinOps for Kubernetes survey:
- 68% of people said their Kubernetes costs are rising.
- Around 69% of respondents said they have no Kubernetes cost monitoring or only have cost estimates.
- Only 13% utilized accurate showbacks.
- Just 14% of respondents have affirmed that they have a chargeback in place.
Cost Advisor automatically pulls cost data from cloud providers, and this is enriched with Kubernetes context to show a line-by-line item of costs by clusters and workloads. The unified view of utilization, performance, and costs insights gives essential data to associate costs with teams for performing chargebacks, and helps drive accountability.
Organizations can leverage Cost Advisor to establish FinOps best practices, including promoting a culture of cost discipline where all teams are reviewing and optimizing cost.
Cost Advisor helps you track costs over time, and correlate spend with new deployments and KPI metrics.
Alerts help you get ahead of unexpected increases in cost, and give you immediate understanding of which workloads need to be reviewed.
Kubernetes cost optimization
The visibility Cost Advisor gives into Kubernetes costs is an essential tool in optimizing Kubernetes resources, ultimately lowering the bill you get from your cloud provider.
Sysdig's analysis of customer environments indicates an average reduction in resource overspend by 40%, with many customers having the opportunity to reduce by up to 80%. A larger environment increases the potential saving by a huge margin.
Cost Advisor intelligently identifies workloads that can be optimized, and users can prioritize where to focus efforts with estimated savings. By looking at the historical utilization data Sysdig collects, a baseline is established and recommendations are made on how to size workloads. This allows teams to confidently rightsize workloads without sacrificing application performance or availability. That includes a one-liner to apply a change from the command line, as well as the corrections to make at source within Git using infrastructure as code.
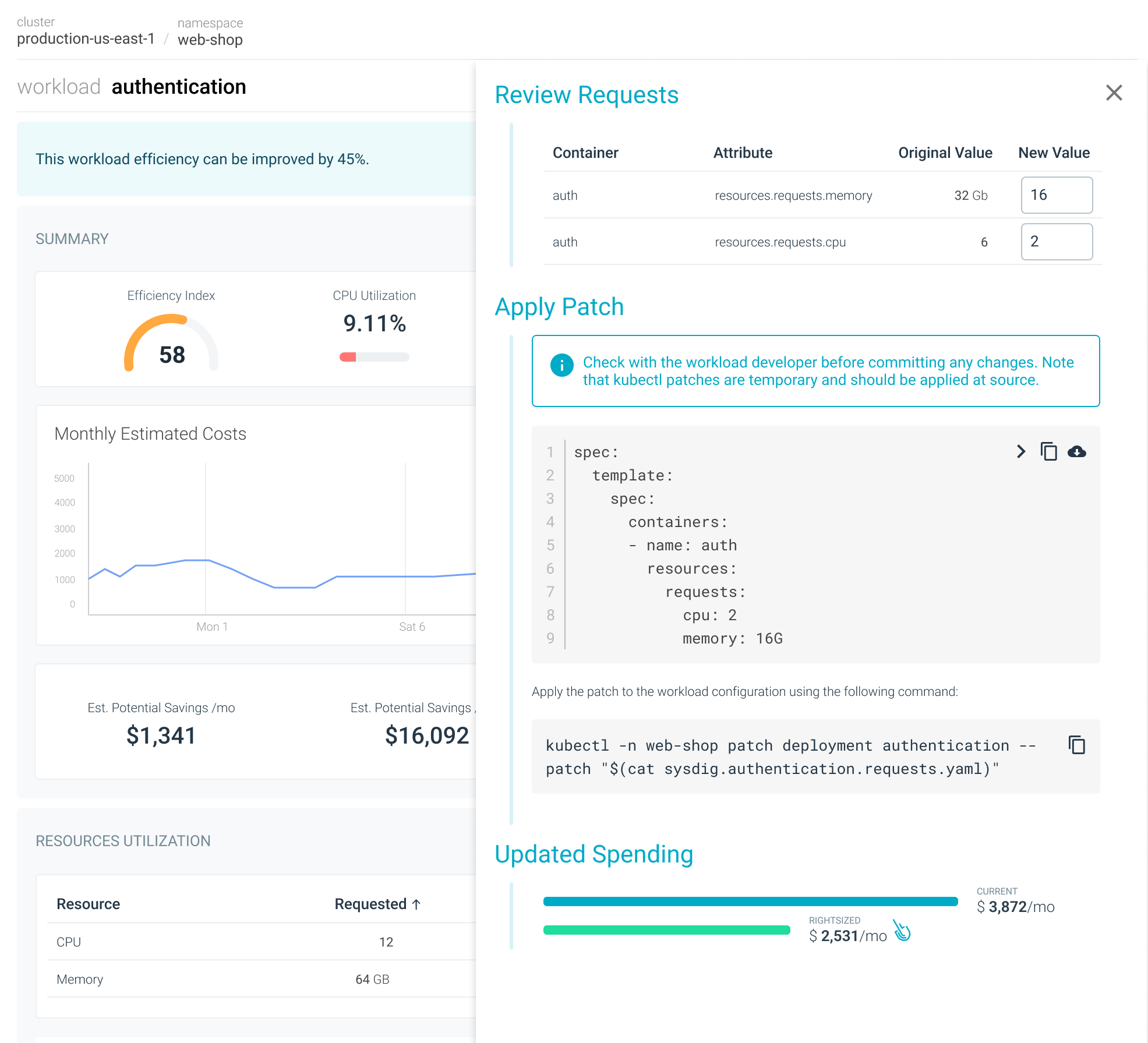
A key goal of Cost Advisor is to shift-left cost optimization. Making this process as effortless as possible is an important way we're enabling our customers to promote FinOps best practices, including creating a culture of cost discipline.
Cost excellence without sacrificing pace of development
With more and more organizations moving to cloud-native, Cost Advisor ensures you can get ahead of Kubernetes cost monitoring and cost optimization. Reducing Kubernetes costs increases margins, and on average, Cost Advisor can help customers reduce Kubernetes resource waste by 40%.
You can try Cost Advisor by signing up for a free 30-day trial of Sysdig Monitor. No credit card is required!