


Falco Feeds extends the power of Falco by giving open source-focused companies access to expert-written rules that are continuously updated as new threats are discovered.

The StatsD stack is one of the most popular monitoring solutions to instrument your code using custom metrics. In this post we will describe the StatsD metrics architecture, metrics types and formats, proving code examples for the Golang, NodeJS/Javascript and Python programming languages. StatsD is a front-end proxy originally written by Etsy’s Erik Kastnen in Node.js, to collect metrics from instrumented code.
"Learn how to use #StatsD to instrument your #Golang #NodeJS or #Python code with custom metrics."
Although the server was originally written using Node.js, there are multiple server implementations written in other languages:
And multiple client implementations that will allow us to instrument our applications as well.
You can find a full list of all the clients in: https://github.com/etsy/statsd/wiki#client-implementations
In this blog post we will implement StatsD metrics using Golang, Node.js and Python.But first, we need to understand the types of StatsD metrics at our disposal and how they work.
How StatsD protocol works
Your application code needs to be instrumented with any of the client implementations we mentioned above, we will show a full code example later on, but this basically boils down to:
- Importing the StatsD client library: import statsd
- Declaring the StatsD variables that we want to report, specifying their metric type: counter = client.get_counter(“counter”)
- Periodically emitting a metric value update: average.send(‘avg’, 5)
The client library will format and encapsulate the metrics in a UDP network package and send them to a StatsD server.The server will collect and aggregate all the metrics and periodically submit them to a monitoring backend (or multiple backends). There are several backends able to handle this metric format at your disposal, like Graphite or InfluxDB.
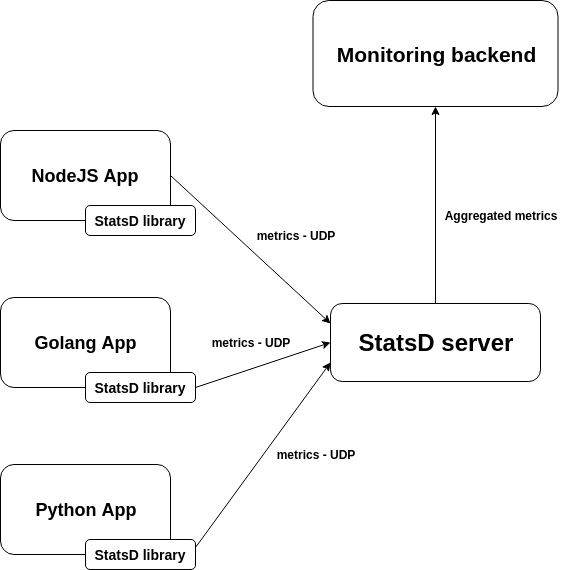
This architecture allows the StasD server to be written in any language. It also allows decoupling the behaviour of your application from the monitoring server, making any of these parts easily replaceable or updatable without interfering with the application code that your developers need to maintain.But it has some drawbacks:
- You need to inject the minimum network configuration required to find the StatsD server. This means dealing with volatile IPs, network segmentation and routing, firewalls, etc.The information about which entity (host, pod, container, process) originally sent the metric is lost unless you format the metrics to explicitly store this data.
This is especially problematic if you want to deploy containers and microservices, where the software entities are volatile by nature and you need to group them by functionality (for example Kubernetes deployments and services) to make sense of the data.
- The StatsD server becomes a single point of failure. If it crashes, all the monitoring process is temporarily down and the UDP packages for that period are lost.
Types of StatsD metrics
All the metrics are sent to a server and need to be sent in a specific format. Similar to competing metrics stacks, this means declaring the variables as one of the supported StatsD metric types.Each metric follows a simple terminology.
Gauge
Gauges are instantaneous measurements of a value, like the speedometer in a car. They can increase, decrease or be set to a certain value. They are a good option of you need to instrument, for example, the current load of the system.
<metric name>:<value>|g
We can also add a sign to the gauge, so instead of explicitly setting the value, it will be increased or decreased.
<metric name>:+<value>|g<metric name>:-<value>|g
If the gauge is not updated at the next flush, it will send the previous value.
Counters
Counters are like gauges aggregated at the server rather than the client. They will accumulate over a period of time, and then flushed, resetting their value to 0. They can be used, for example, to count how many calls is an endpoint receiving over time:
<metric name>:<value>|c[|@<rate>]
The rate is optional and represents how many times the metric has been sent. For instance, if the rate is 0.1, this means that the metric has only been sent 1/10 of the times. Which means that the value must be first multiplied by 10 at the server. If someone sends myMetric:2|c|@0.1, the server will understand that the current value of myMetric is 20.
Timers
Timers are a measure of milliseconds between the start and end of a given event. This can be used, for example, when you need to measure the request time for a service or how long a user has been waiting for the web page to display.
<metric name>:<value>|ms[|@<rate]
The rate is also optional here and it has the same meaning as in the Counter rate
Histograms
The histograms are also a measure of time, but they are calculated at the server side. As the data exported by the client is the same, this is just an alias for the Timer type.
<metric name>:<value>|h
Meters
Meters are special case of a Counter calculated at the server. They measure the rate of events, for example, the number of requests per second. In addition to the mean rate, meters also track 1-, 5-, and 15-minute moving averages. Meters can be sent in full format:
<metric name>:<value>|m
But also in a short format:
<metric name>
Which means that the counter will be increased by 1.
Sets
Sets can be used to count the number of unique occurrences between flushes. When a metric is sent with a specific value, this is counted as an occurrence.
<metric name>:<value>|s
Let’s throw some light to this behaviour with a small example. Imagine the client sends:
unique_users:203|s
unique_users:340|s
unique_users:203|s
The metric unique_users will only have a value of 2, and will ignore the repeated one.
StatsD code examples
Golang code instrumentation with StatsD
First of all we need to create a client using:
client := statsd.NewStatsdClient(url, prefix)
And then create the UDP connection:
client.CreateSocket()
And that's basically it, we are ready to send metrics. Here you can see the complete working example:
Note that the UDP packages will be sent to 127.0.0.1:8125:
If you don't have a real StastD server in place, you can always debug the application output with a network tool like netcat:
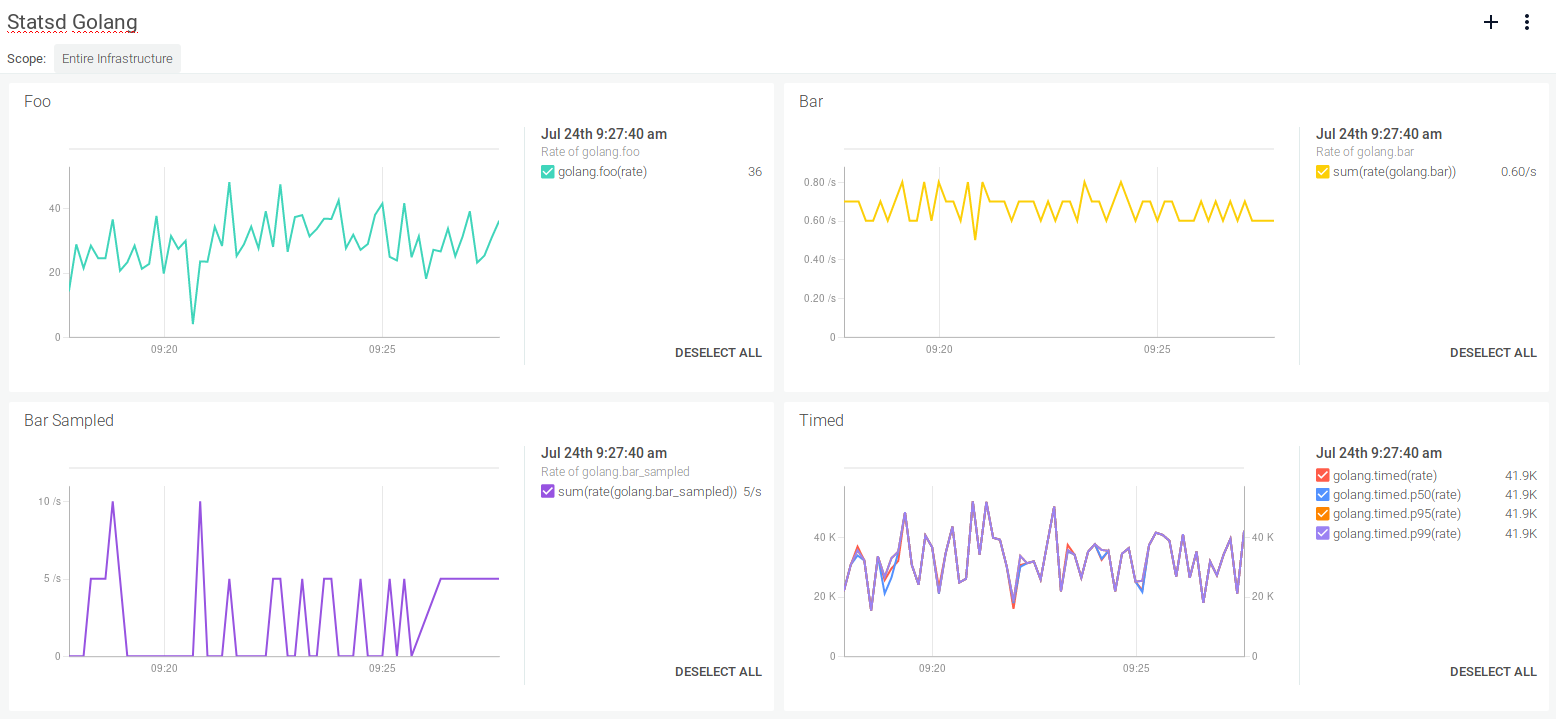
This is how these metrics will look using Sysdig Monitor as the monitoring backend and Sysdig dashboards for dynamic visualization:
Node.js / Javascript code instrumentation with StatsD
We are going to use the statsd-client from npm, so first we need to install it with:
$ npm install --save statsd-client
Now, let's look at a brief example of how the metrics are instrumented with Javascript.
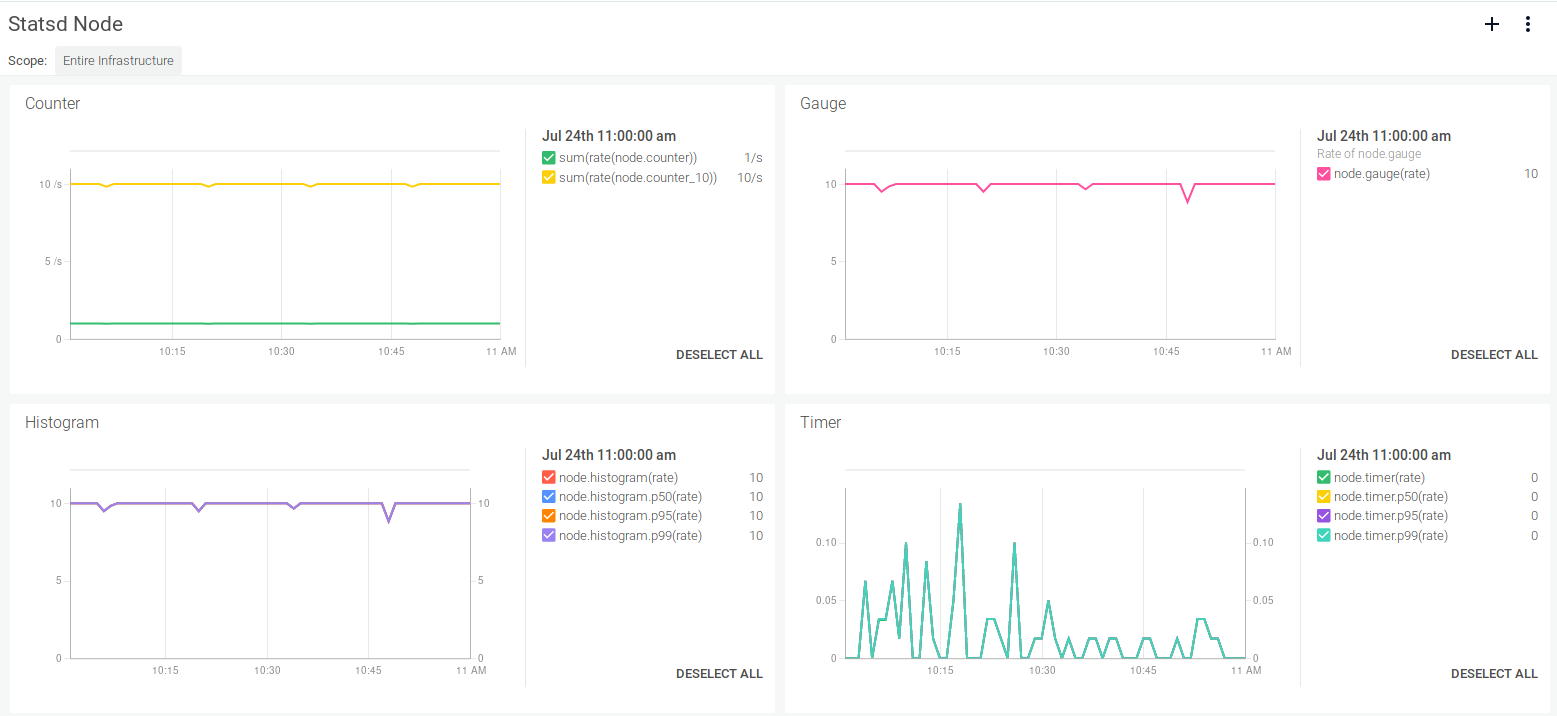
Node.js / Javascript dashboard using Sysdig Monitor:
Python code instrumentation with StatsD
In this example we will use the python-statsd library. To install it we just execute:
$ pip install python-statsd
And we are ready to execute the following Python code:
And, again, this is the netcat debugging output:
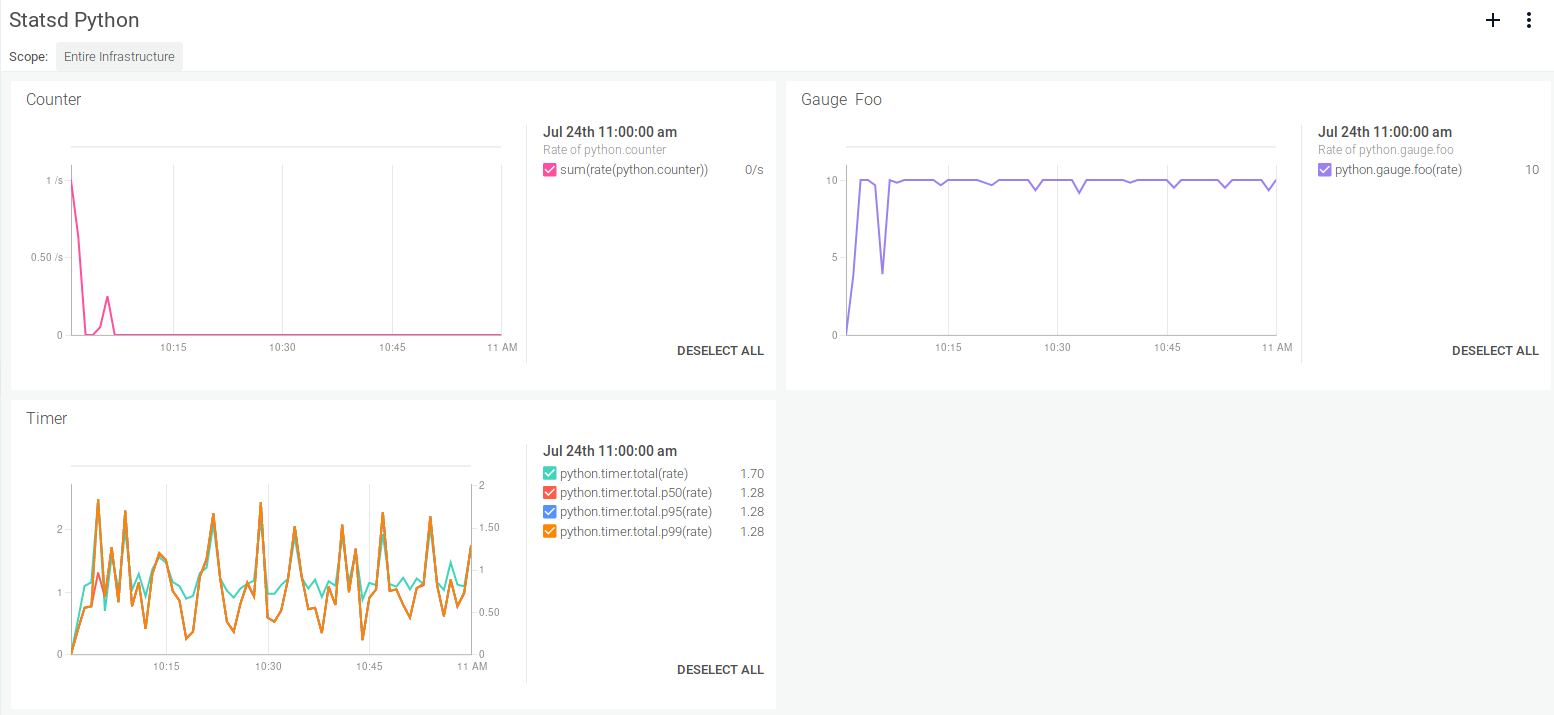
And a custom monitoring dashboards using Sysdig Monitor:
StatsD code in Java – Deprecated client
Since the java-statsd-client project seems stalled (last commit was more than 4 years ago), it is discouraged to instrument a Java application with StatsD. But don't worry, you can always instrument your code using Java's official JMX or implement the Prometheus stack, a project incubated under the Cloud Native Computing Foundation umbrella.
StatsD instrumentation and Docker containers with Sysdig Monitor
Sysdig Monitor allows you to automatically collect and aggregate custom metrics, including StatsD, but also Prometheus, JMX and expvars.As we mentioned before, the "classical" StatsD architecture presents some limitations, especially when deployed over containerized (Docker, Kubernetes, OpenShift, etc) workflows:
- Origin of the metrics (container, pod, deployment, service) is lost if you don't explicitly append it to the metric
- Entities are ephemeral appearing, disappearing being scaled up and down, manual tagging and labelling is just not feasible anymore
- Network configuration and visibility requires injecting extra parameters in your containers at boot time
- Adding a separate process, inside the same container or as a sidecar container, to aggregate and push the StatsD metrics is doable but goes against the inherent simplicity of containers
Sysdig Monitor uses a radically different approach to gather StatsD metrics, automatically discovering and collecting them without any explicit network forwarding.Let's illustrate this approach in the context of containerized applications with the following diagram:
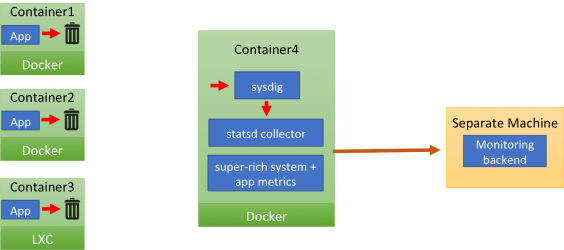
The careful reader has surely noticed that there are no arrows connecting the app containers and the monitor container. That's because the applications inside the containers send their StatsD messages to localhost.This means: no need to hardcode a collector IP address. However there's no StatsD collector on localhost, so the UDP payload just gets dropped (the image depicts it as the message going to a trash can).The same message "magically" appears in the monitoring container (container4). Once there, it's is received by the Sysdig agent, which feeds it to the local StatsD collector, after enriching it with a set of tags (container name, image name, etc) that will enable segmentation later on.The StatsD messages are merged with Sysdig Monitor's system, network and application metrics and then they are compressed and shipped to the Sysdig Monitor backend.You're probably wondering: "How do StatsD messages go from the application container to the Sysdig Monitor one"? Let's add some detail to the previous image:
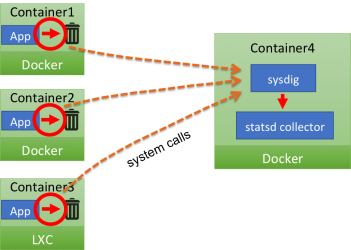
What is actually happening here is that all network transmission made from inside the application containers, including StatsD messages, including the ones sent to a non existent destination, generate a system call. The Sysdig agent can capture these system calls from a separate container, where the StatsD collector is listening. In practice, the agent acts as a transparent proxy between the application and the StatsD collector, even if they are in different containers. Sysdig also knows which container the system call is coming from, and uses that information to transparently tag the StatsD message.We believe this approach has multiple noticeable advantages, more so if you are using containers:
- Getting rid of all the network configuration, routing and maintenance
- Super simple "push to localhost" approach
- Out of the box host / container / orchestrator (Docker, Kubernetes, OpenShift) tagging
- Provides a monitoring backend including long term storage, dynamic aggregation based on labels and flexible dashboarding and visualization
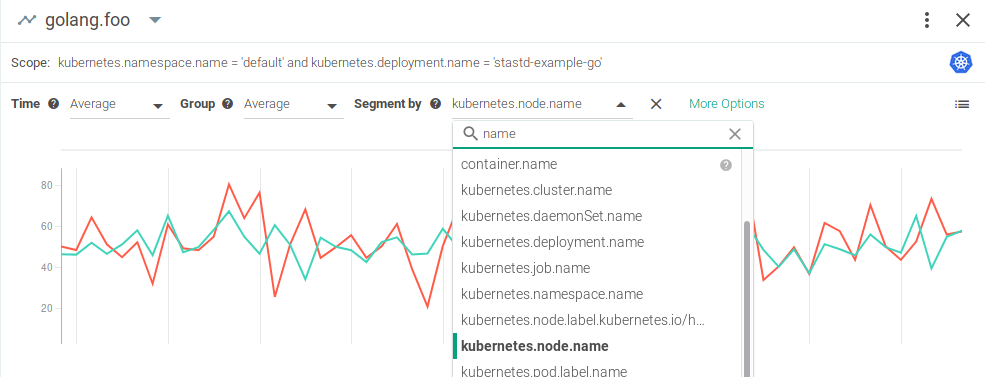
We call this alternative StatsD architecture passive StatsD collection (also known as StatsD teleport 😉).In a Kubernetes cluster, all the metrics are aggregated, so you can segment this information by pod, container, node, and any other label you might want:
Conclusions
StatsD presents a simple and effective metrics architecture that can be easily implemented to instrument the most popular programming languages. The entry barrier to start using StatsD is not too high and we hope the code examples above will help getting you started. Prometheus metrics is another popular open source code instrumentation stack that you may also consider, if you are considering both solutions, we recommend you to start by understanding which metrics paradigm fits your requisites better: dot-metrics vs tagged metrics.