



Falco Feeds extends the power of Falco by giving open source-focused companies access to expert-written rules that are continuously updated as new threats are discovered.

The AWS RDS service itself falls on the AWS side of the Shared Responsibility model, but the day-to-day management of the RDS security instances falls on your side. When it comes to shared responsibility, your obligation depends on the AWS services that you deploy, and also other factors including (but not limited to) the sensitivity of your data, your company's requirements, and applicable laws and regulations.
Deployment mistakes or other changes made to an RDS configuration can result in major security risks, including data exfiltration and other critical consequences. But finding the high-risk events can be a bit like finding a needle in a haystack without the right tools.
In this blog, we dig deep into:
- A sample high-risk RDS event, and see how post-deployment drift can occur even if initial configurations follow best practices.
- How attackers can use any number of scanning services and tools to exploit publicly accessible RDS instances.
- Why it is critical to be alerted as soon as an RDS instance is made public, and we will focus on the actionable data needed to address the security gap.
- Hunting for these alerts using native tools, and comparing this to how Sysdig Secure tracks down and reports on these high-risk security events.
What are RDS and Cloudtrail all about?
AWS Relational Database Service (RDS) is a highly successful AWS service, first rolled out back in 2009. RDS simplifies the creation, scaling, management, and operation of relational databases. Today, RDS supports many relational database engines, including PostgreSQL, MariaDB, SQL Server, and Oracle Database.
AWS RDS security features include (but are not limited to) encryption, network isolation, and role-based access control using AWS Identity and Access Management (IAM).
The recommended deployment architecture is to locate each RDS instance in a Private Subnet, with neither an Internet Gateway nor a public Domain Name. This ensures it cannot be found by scanning the AWS subnet space for common database ports, and it cannot be accessed directly from the Internet.
Like most services in AWS, the actual public/private deployment decision falls on your side of the Shared Responsibility model.
Making an RDS instance public can certainly be a high-risk event, but it is not the only event to worry about.
CloudTrail is the great audit log in the sky. Any and all actions taken by a user, role, or an AWS service are recorded as events and the service is enabled by default. Making sure CloudTrail is configured correctly is indeed a best practice.
The best practices for CloudTrail include (but are not limited to):
- Configuring CloudTrail in all AWS accounts and Regions
- Specifying separate trails for different use cases
- Enabling CloudTrail log file integrity validation
- Monitoring anomalous API activity with CloudTrail insights
One major consideration with CloudTrail is as your AWS footprint grows, the sheer numbers of logs and events can become impossible to manage. As shown in this Reddit post, one DevOps practitioner is seeing around 10 million log events every day. If you can't find dangerous events you can't react to them, leaving you with a major security problem on your hands.
Which RDS configuration events constitute a Threat?
A significant number of events can be classified as high risk. At the time of writing this Blog, Sysdig researchers have identified at least 12 risky events, with matching rules in Sysdig Secure. This number will likely grow over time. These rules provide comprehensive coverage but can be easily extended if needed.
Several of these events may map to one or more well-known MITRE ATT&CK techniques, including:
- T1190 – Exploit Public-Facing Application
- T1596.005 – Search Open Technical Databases: Scan Databases
- T1210 – Exploitation of Remote Services
These techniques focus in one way or another on remote exploitation of public facing applications or databases.
More information about these MITRE ATT&CK techniques can be found at https://attack.mitre.org/techniques/
| Security Event | Impact | Description |
| Make RDS Instance Public | High | RDS Instance can be found via port, ip, and domain name scanning. |
| Make RDS Snapshot Public | High | RDS Snapshots are listed publicly. |
| Modify RDS Snapshot Attribute | Medium | Could result in making a Snapshot public. |
| Revoke DB Security Group Ingress | High | The Security Group should not change post-deployment. |
| Authorize DB Security Group Ingress | High | This is needed to allow Internet access. |
| Create DB Security Group | High | Any security group changes are important. |
| Delete DB Security Group | High | Security Group should not normally be deleted. |
| Create DB Cluster | Medium | DB Clusters are normally long-lived. |
| Delete DB Cluster | High | DB Cluster deletion is a major event in production that has to be tracked closely. This could result in total data loss. |
| Stop DB Instance | Medium | Stopped DB instances in production are a major event. |
| Delete DB Snapshot | Medium | Any events resulting in deletion of DB data need to be tracked. |
| Stop DB Cluster | Medium | Stopped DB clusters in production are a major event. |
Post-Deployment Drift
Even when the initial deployment follows best practices, the configuration may change post-deployment. This is known as post-deployment drift, and may occur for any number of reasons. Let's look at one possible scenario.
RDS is initially deployed following best practices, in a private subnet with no Internet access.
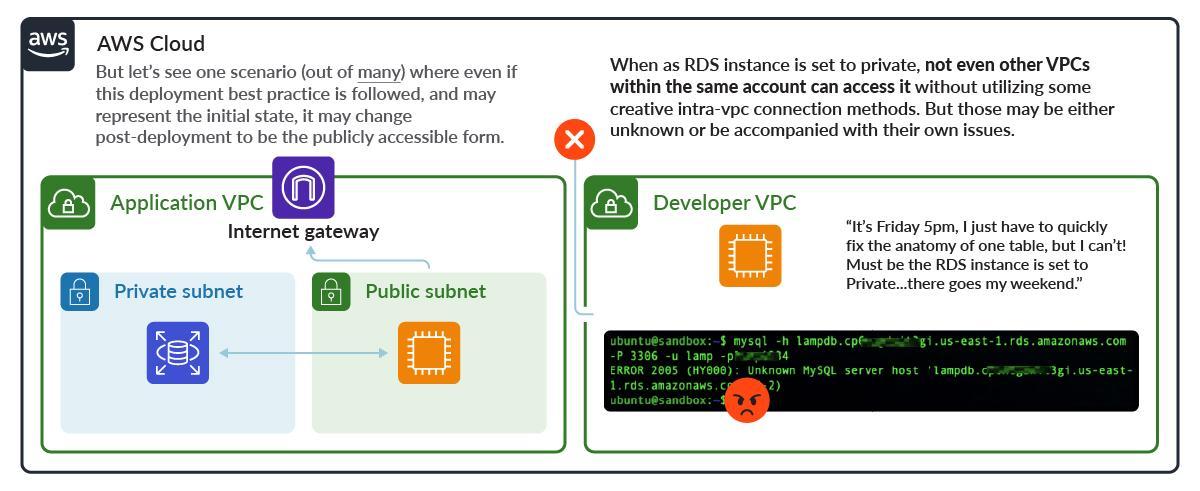
But drift happens, in this case human factors lead to some worst practices. This leaves the RDS instance publicly exposed.
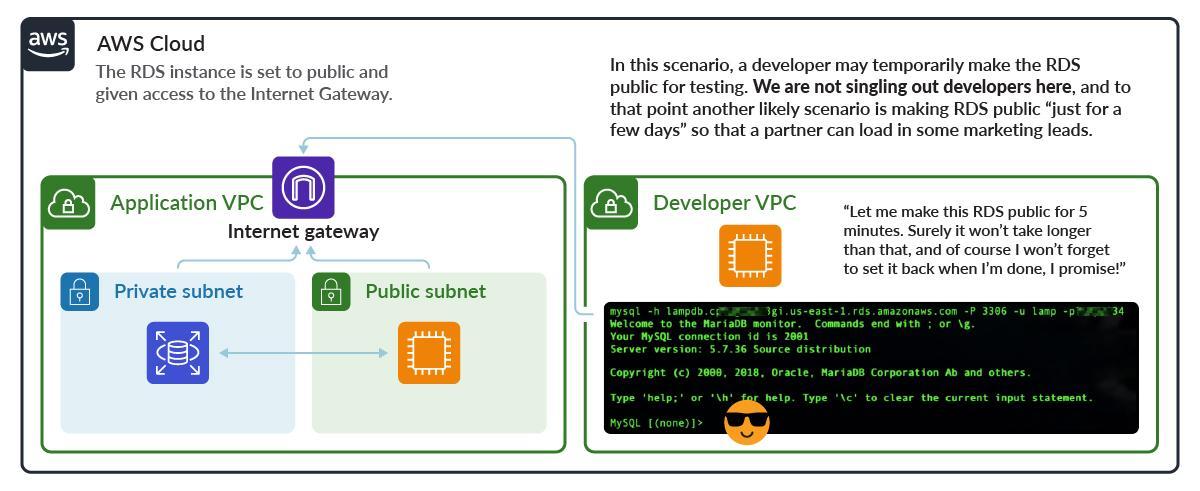
Configuring Public Access
Making an instance public is a very high risk AWS RDS security event because it can easily be found by scanning for common database ports.
Here, the RDS instance listens on port 3306, is set to be public, and has the Internet Gateway added to the RDS Subnet with a route of 0.0.0.0. A wide-open security group completes the picture.
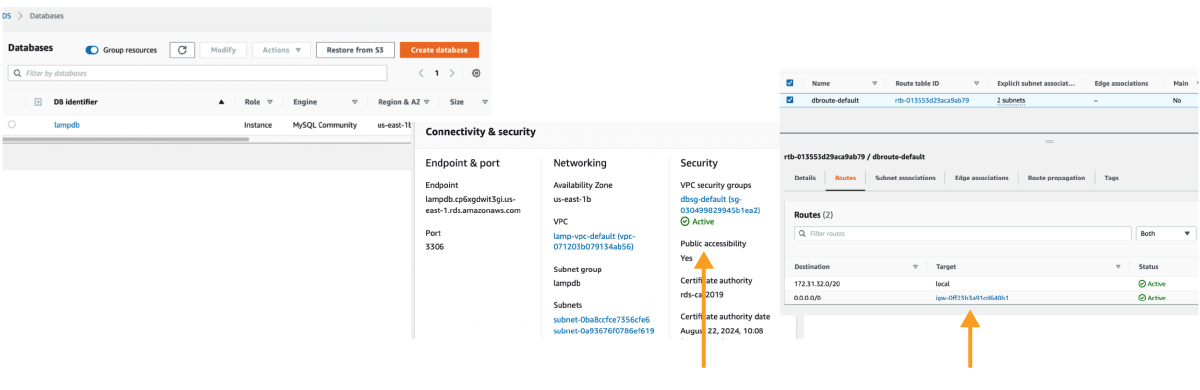
Note: Public snapshots are even easier to find as they are listed in the public snapshots tab.
Consequences of a Public RDS Instance
A public instance can be located by DNS name (if known) or by scanning the AWS subnet space for default database ports and other signatures. After a connection is made, login credentials are required, ideally credentials for a privileged account for maximum damage.
Unfortunately, due to many headline-breaking breaches, attackers have the raw materials to craft credential lists. In this case, the target is MySql, so the credential list would be tailored accordingly using credential patterns that apply to MySQL administrators.
Plenty of tools exist to brute-force iterate through these lists in a relatively small amount of time and (disk) space if the list crafting is done well.
Note: Re-use of privileged login credentials is unfortunately a reality. So credentials found for this RDS instance may be also used in other places in the cloud, such as for non-database entities like servers, opening the door to all sorts of lateral movement worst-case scenarios. Attackers of course know this very well.
Here is an example of a brute force attack* using a learning tool originally from 2001 that professional attackers would probably not use in real life, because it is too slow. Even though this achieved 36 tries/second, much faster tools are available. Attackers may even launch parallel attacks from farms of containers or serverless functions to achieve a high aggregate login rate with a wide distribution of ip addresses. So, brute force is a real probability.
Note: Under no circumstances should these any of the techniques shown in this blog be used outside of a testing environment

Note: An unintended consequence of the power of the AWS cloud is it facilitates a high rate of brute force attempts.
Once an attacker has logged in using one account, they can find the hashed passwords for all the database users and might be able to easily crack them. This would be useful if a different set of credentials is needed to complete the mission. Hash salting will help mitigate this, but by no means should we rely on that alone.
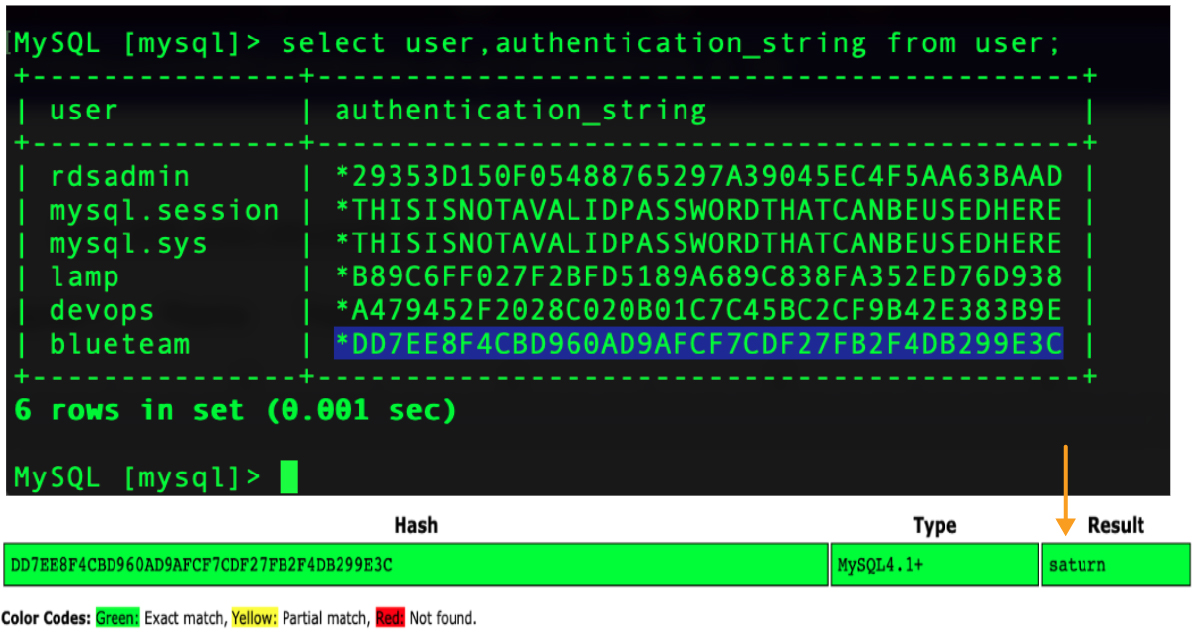
So while this serves as a reminder that easily guessed and recycled passwords are a terrible practice, that is entirely besides the point. The point of this blog is that public database instances are a very serious security concern.
Exposed public RDS instances have to be hunted down and secured as fast as they appear. The clock is ticking because, like everything else in threat mitigation, time is of the essence.
The longer an exposure remains unresolved, the faster the threat surface expands as more attackers discover the front door. And as the clock ticks, each attacker has more and more time to succeed!
How real is any of this?
Unfortunately, this occurs all the time in real life.
In this example, a Reddit member posts about an RDS being hacked – on which side of the Shared Responsibility model is the fault?
Note: Reddit is by nature in the public domain, with usernames and organizations typically anonymous. However, usernames have been obscured in this blog post.
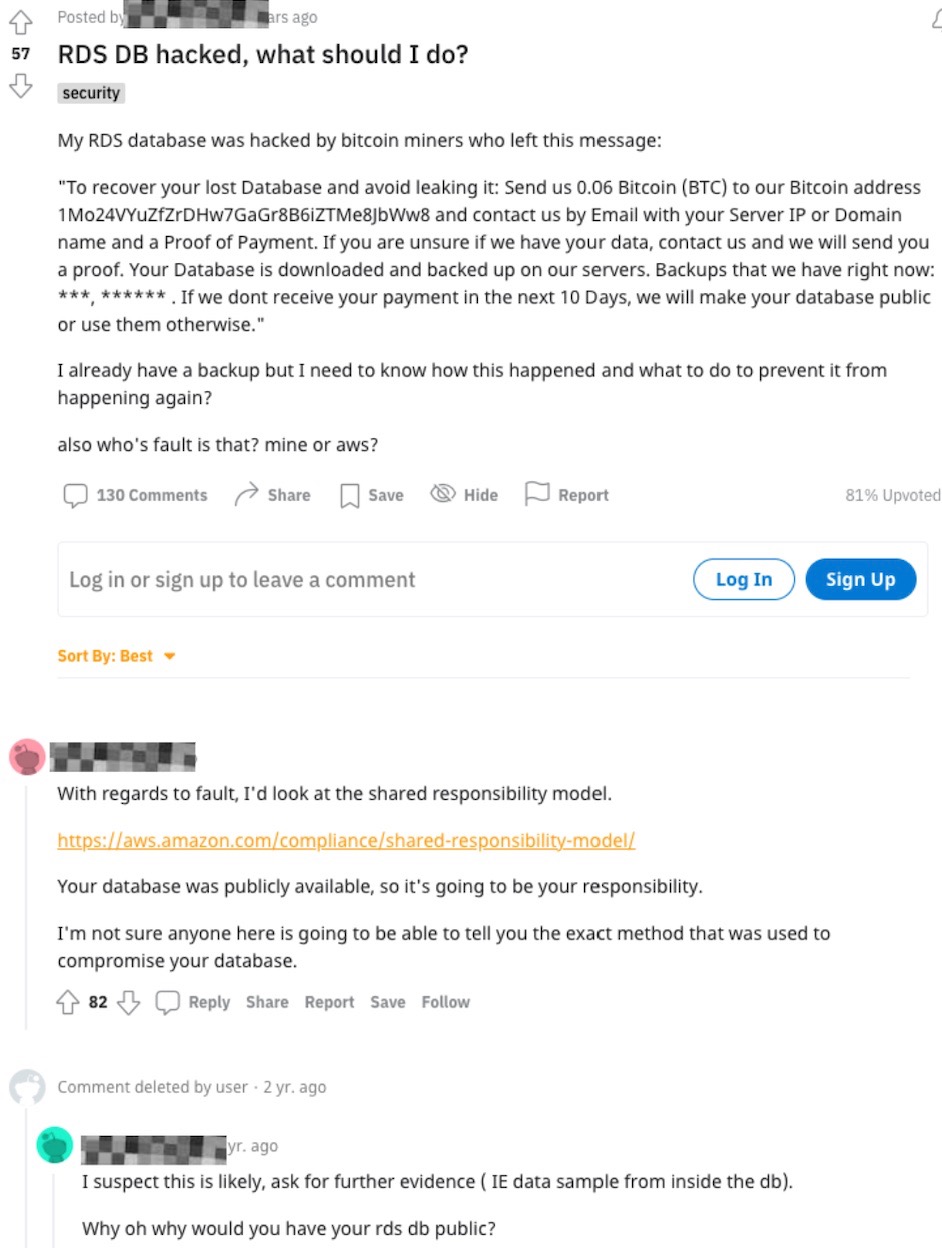
That's just one example. How many exposed RDS instances are out there? What is your prediction?
Probing the Internet
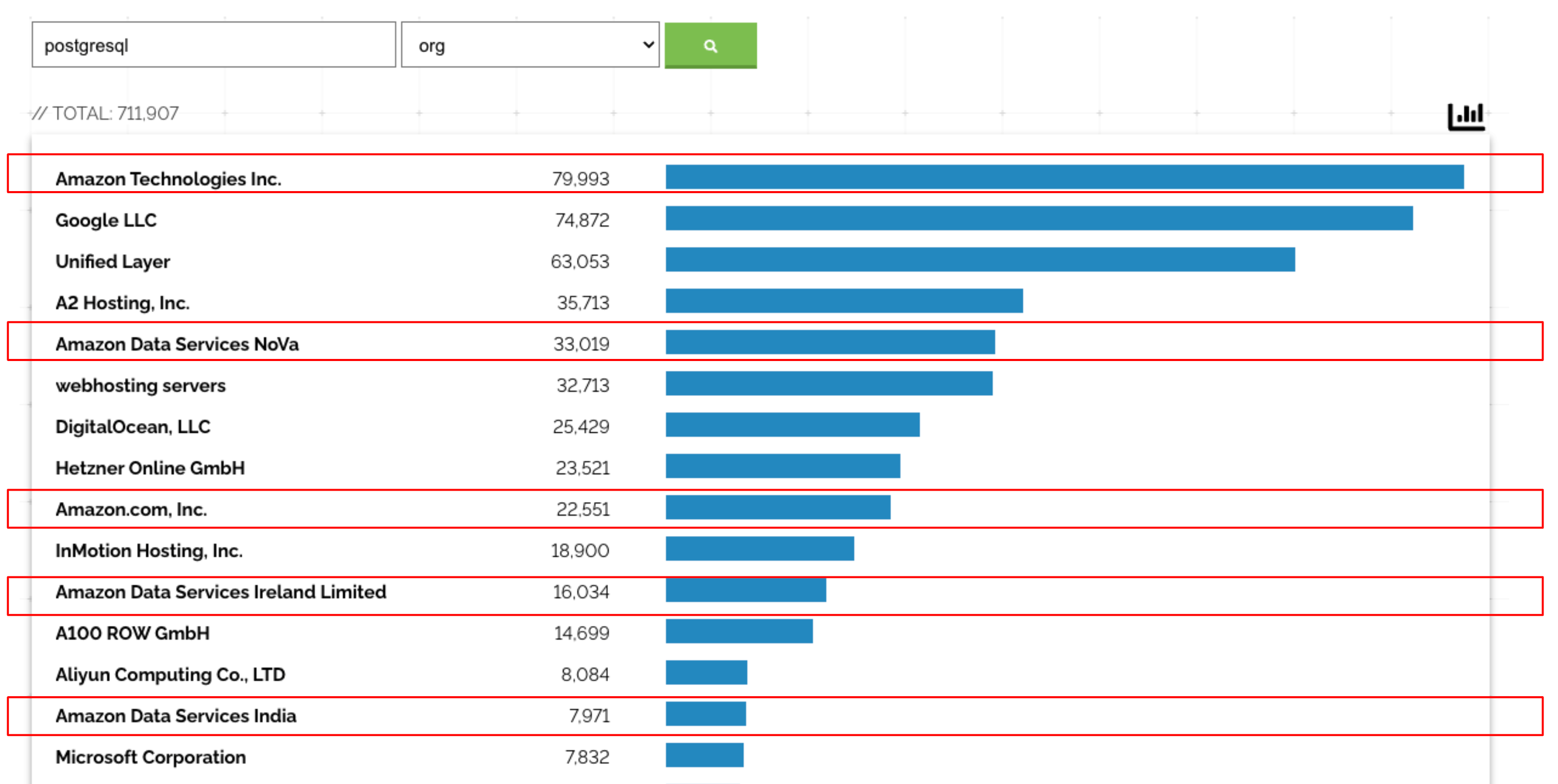
Tools for scanning network space have been around for a long time. One modern example is Shodan. The Shodan tool scans for signatures of services, and goes a bit further than simple port scanning. As research for this blog, we did some scanning for MySQL and PostgreSQL. The results are worse than we might have predicted:
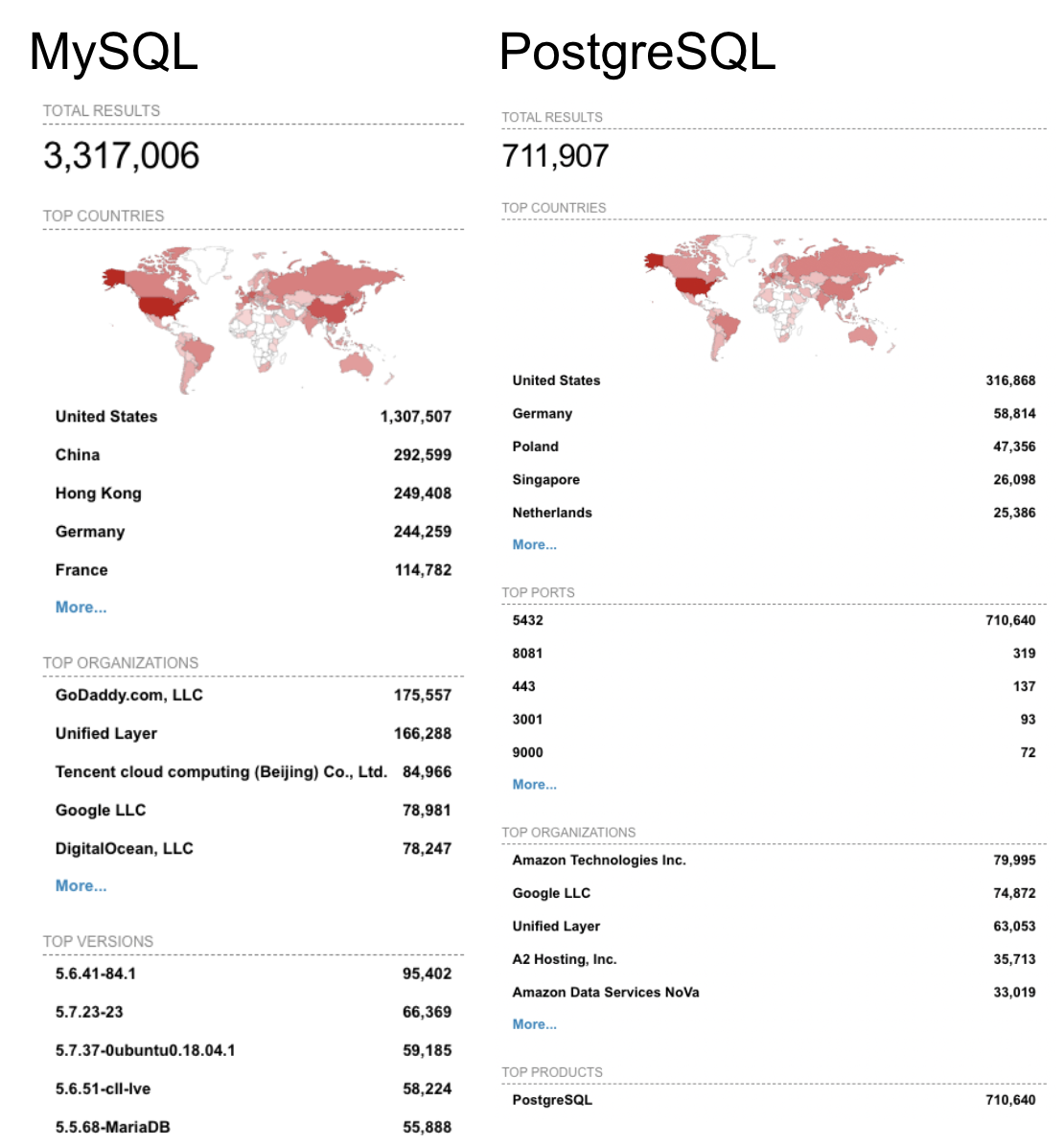
And that's just the count of instances using default ports!
| DB Engine | MySQL | PostgreSQL |
| Instances Exposed Publicly | 3,317,006 | 711,907 |
Public exposure on AWS
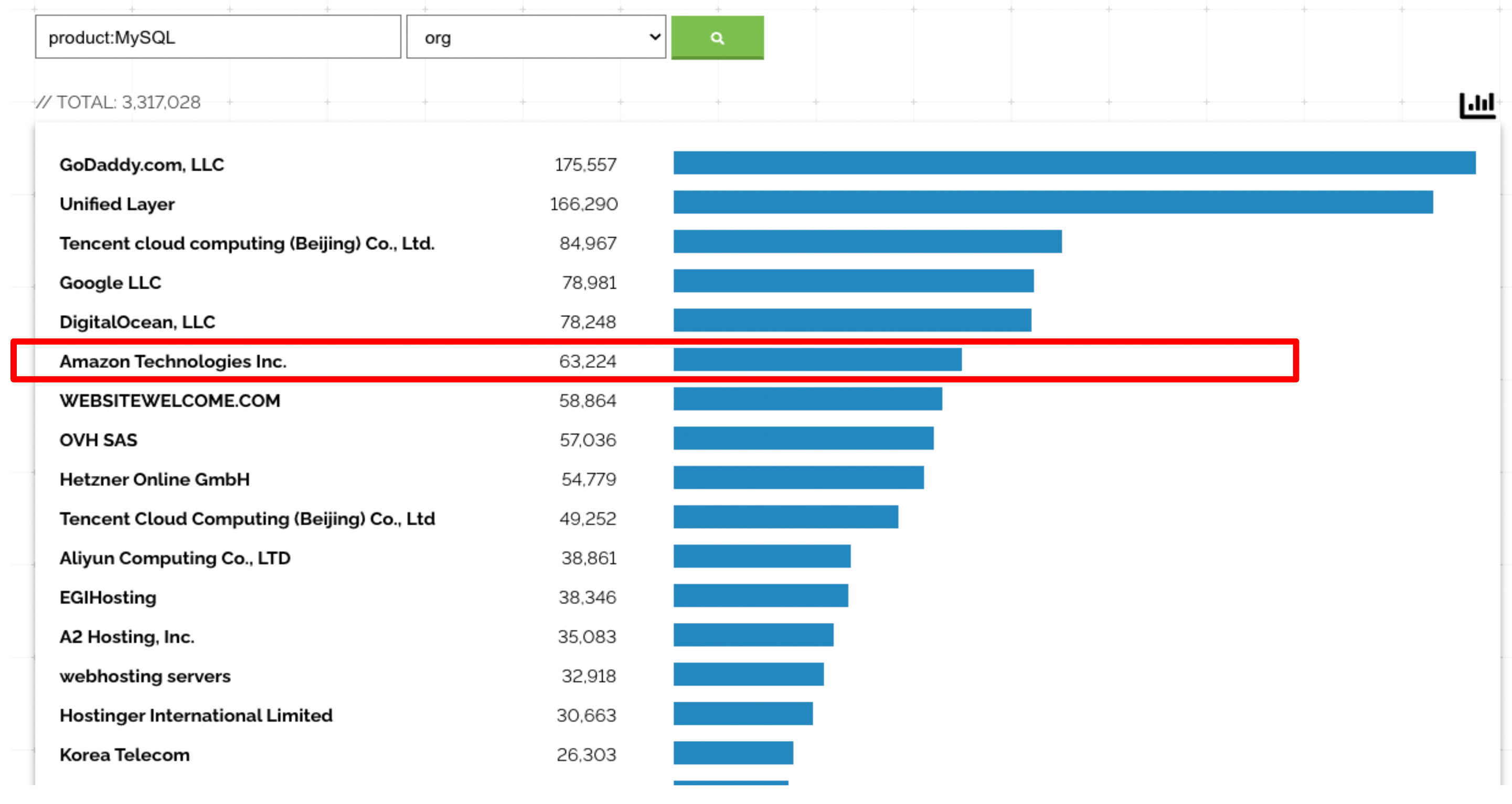
Shodan reveals that more than 63K publicly exposed instances of MySQL are hosted in AWS. PostgreSQL is even worse, with more than 150K exposed instances in AWS. Based on the popularity of RDS, it follows that probably a significant proportion are using RDS. The data proves that RDS exposure is an unfortunate reality.
Hunting for the Needle in the Haystack
CloudTrail is the haystack, and configuration events that have high threat potential are the needles.
CloudTrail contains all the events, but CloudTrail has no concept of good events vs bad events. And CloudTrail itself has no alerting capability. This is a problem when we need to be alerted immediately on any changes to the public / private status of an AWS RDS instance.
What about CSPM? Traditional CSPM is a scanning process that iterates through all the services in an AWS account, but this process takes a long time to complete. Two leading CSPM vendors we studied have default scan intervals of 24hrs and 36hrs respectively. Lengthy scan intervals are not going to work in this case, because if the database was flipped from private to public and back again in between scans, the CSPM tool will never know.
Instead, we need a tool that continuously scans CloudTrail like an all-seeing security camera, because this will catch all those dangerous events as soon as they happen.
But beware of solutions that copy CloudTrail logs either elsewhere within AWS or out of AWS entirely, because all that exporting and ingesting adds delay and costs. Costs can be high because millions of log entries might be exported every day, regardless of if those events are security concerns or not.
Effective cloud detection and response must throw actionable alerts the moment a threatening event appears in CloudTrail, without any added costs or delays.
DIY with Native Tools
Let's try a DIY approach using native tools. Assuming we can succeed in meeting the requirements, we should measure the effort and complexity to get this done.
We will focus on Making an RDS DB Instance Public as that is a very high priority event by any measure.
REQUIREMENTS:
As real-time as possible, for any RDS instance made public, generate an Alert including at a minimum:
- Username
- DB Instance name
We will try the following native tools:
- CloudTrail
- Athena
- CloudWatch
- GuardDuty
- EventBridge
- Security Hub
CloudTrail
Logging to CloudTrail is undoubtedly a best practice. We know CloudTrail contains what we need, the information is not locked away, but it is somewhat buried. So we must figure out how to mine, alert, and take action on this data.
Start by using the CloudTrail console itself to define the needle in this haystack:
(Step 0 is actually learning CloudTrail and the JSON log formats, which is not accounted for here, but takes a non-trivial amount of time)
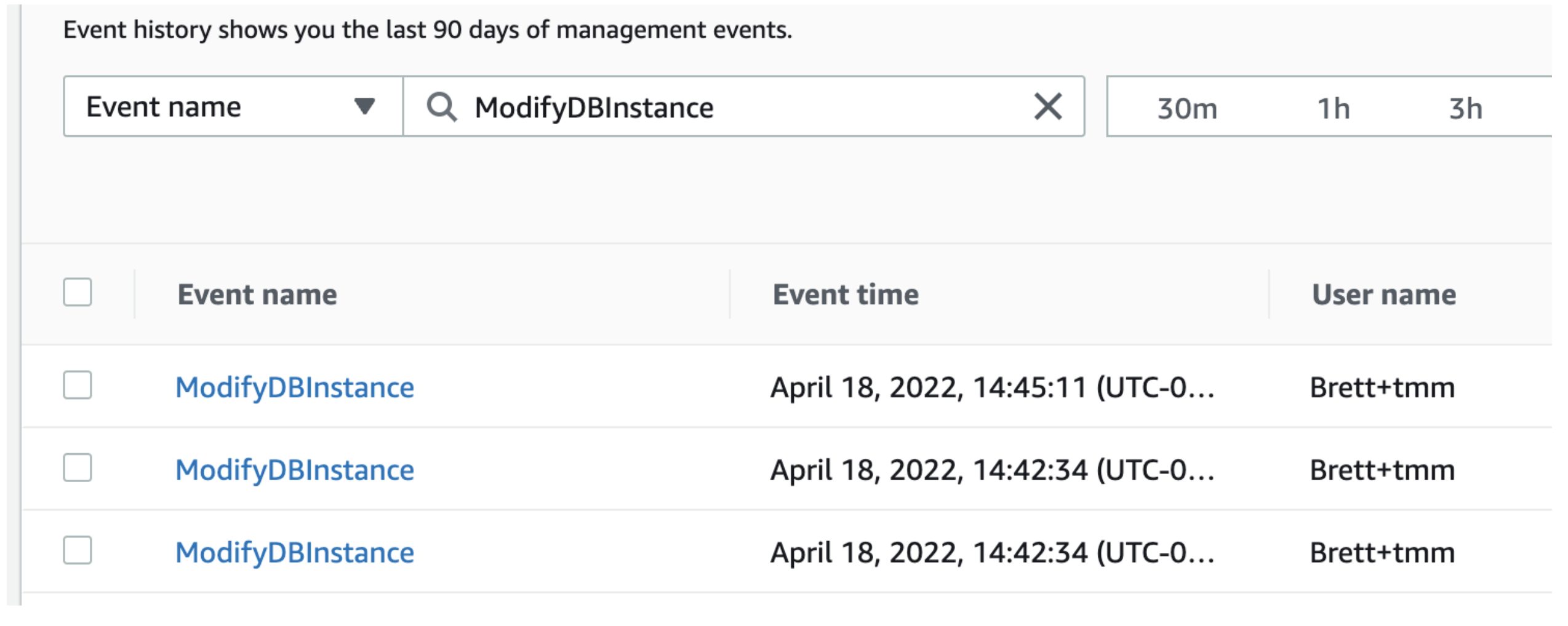
- Obtain the raw material. Assumption: We have prior knowledge that the event name is "ModifyDBInstance". We need to filter for this event in our Trail:
- Export some Trail logs and import these in a Spreadsheet tool (shown below)
- Manually find the right string of text to parse (shown below)
After several tries and false starts, we have succeeded in finding the data as shown below, the "publiclyAccessible: true" string is the smoking gun.
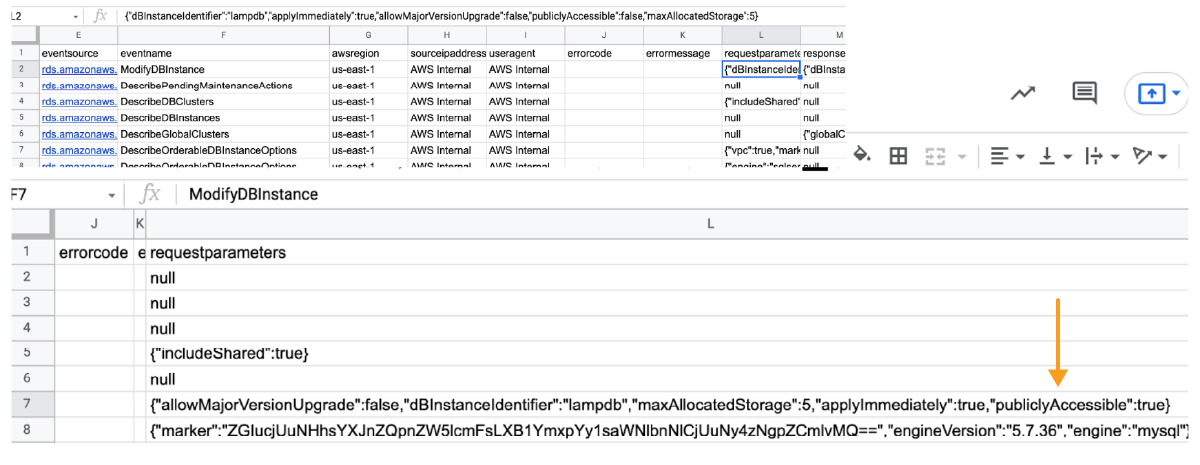
We have proven we can pinpoint the events in the raw Trail logs, but this is a manual process. That will not work; the process has to be automated. Whatever we construct using native services must continuously scan CloudTrail for these Suspicious Events and send actionable alerts, and we need a visualization dashboard to make this usable in production.
We will try additional native AWS services to meet these goals.
Athena
Armed with the right string to look for, we build a SQL query. It works but is fragile. It will break easily if used on other Trails, as the Trail name is hard-coded. Assumption: We have prior knowledge of SQL.
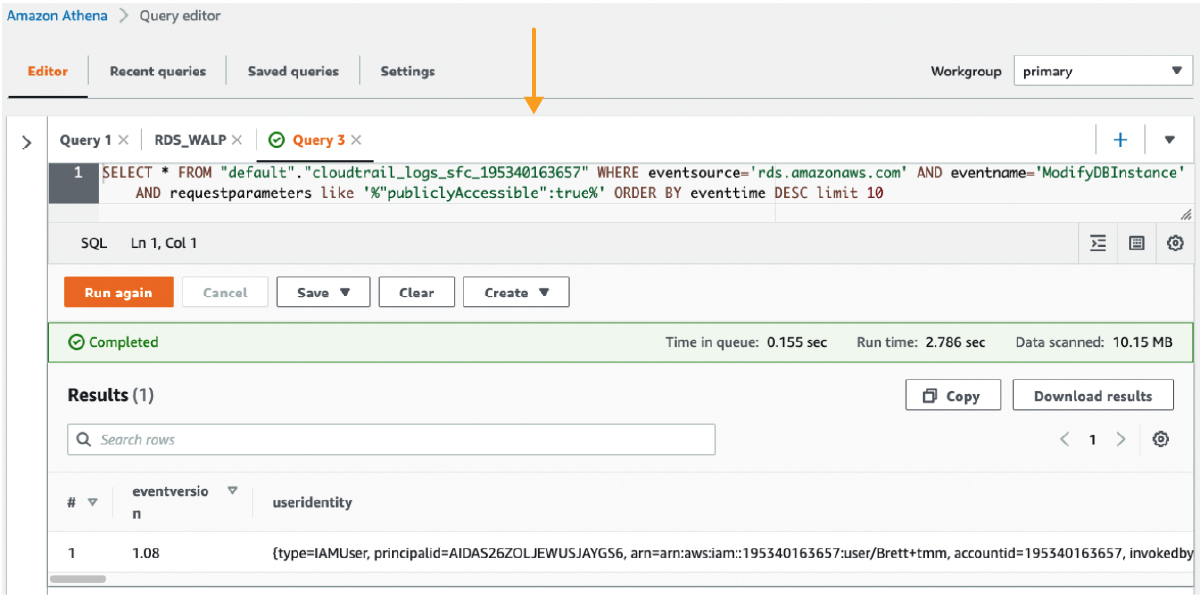
Our SQL works, and we receive a result as a long string of JSON. For this to meet the requirements, we need at least the RDS Instance and the IAM user who initiated this security incident.
The username can be parsed from the useridentity field.
{type=IAMUser, principalid=xxxxxxxxx, arn=arn:aws:iam::xxxxxxx:user/brett+tmm
, accountid=xxxxxxxxx, invokedby=null, accesskeyid=xxxxxxxxx, username=SOMEAWSUSER}
The name of the RDS instance can be parsed from the responseelements field.
{"dBInstanceIdentifier":"lampdb","dBInstanceClass":"db.t3.micro","engine":"mysql","dBInstanceStatus":"available","masterUsername":"lamp","dBName":"lamp","endpoint":{"address":"xxxxxxxx.us-east-1.rds.amazonaws.com","port":3306,"hostedZoneId":"Z2R2ITUGPM61AM"},"allocatedStorage":5,"instanceCreateTime":"Mar 31, 2022 5:56:53"}
The parsing is manual and painful but nevertheless, Athena has allowed us to find the right information. But unfortunately Athena doesn't send Alerts. For that, we will try to use CloudWatch metrics to get both the right information, and the right alerts.
CloudWatch
CloudWatch can send us alerts based on CloudTrail events. Will this finally meet the requirements?
- The first step is to configure the Trail to send events to CloudWatch Logs. This is a multi-step process including special IAM policies, and is covered here.
- The next step is to make a Metric Filter. The actual Filter used was: "\"publiclyAccessible\": true" and all the steps are covered here.
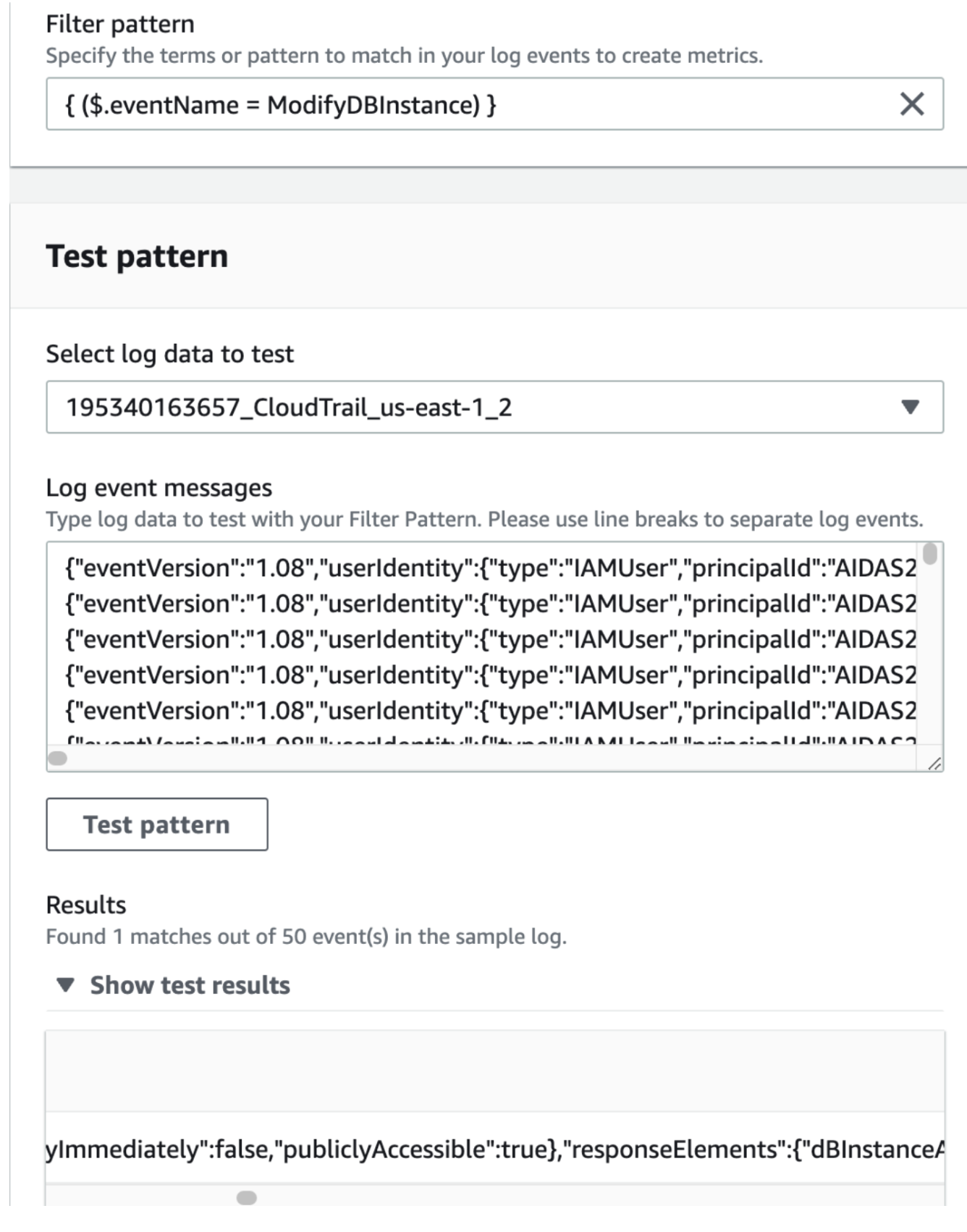
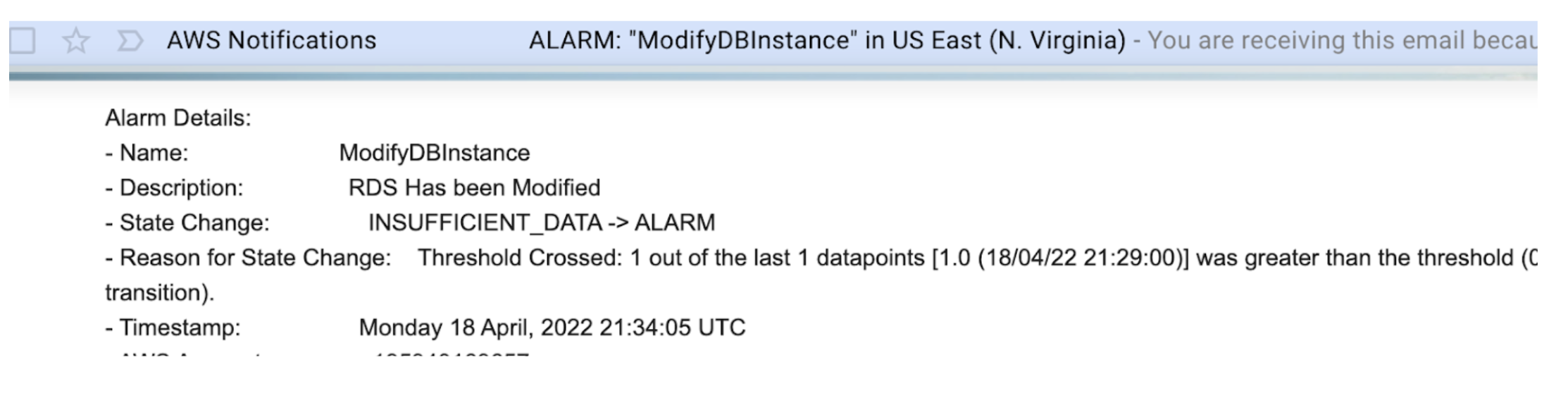
Once again we fell short of meeting the requirements. The good news is we are receiving alerts, but the bad news is the alerts are not actionable, because they do not contain the username and DB instance name.
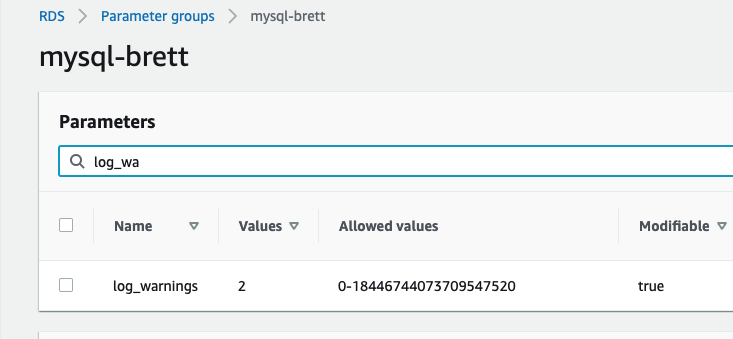
Despite our struggles to achieve our main objective, we found one great feature of CloudWatch worth mentioning: We can force the MySQL5.7 engine itself to log the failed logins. It's a relatively easy if slightly arcane process, we first have to create a custom parameter group and set log_warnings to 2
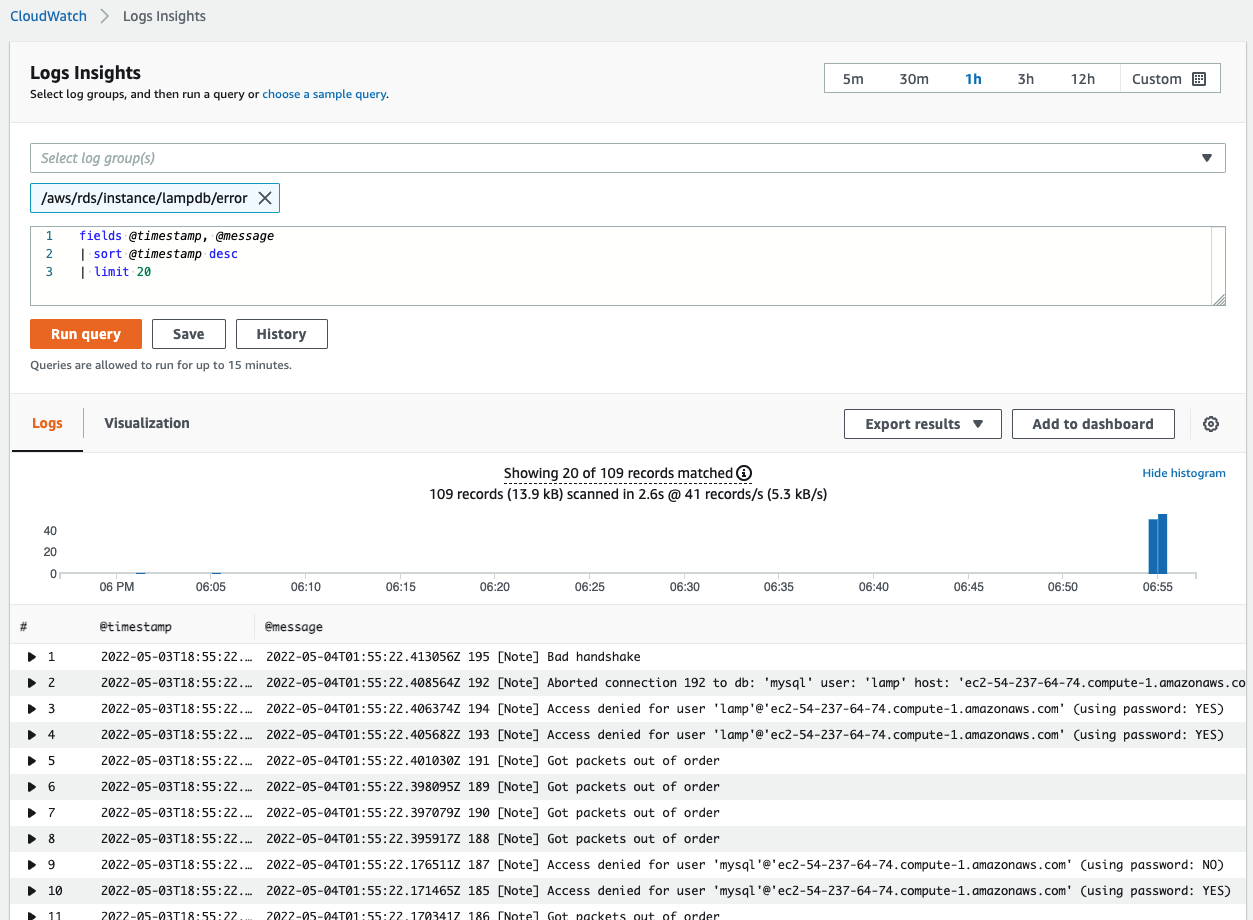
After that, we can see that CloudWatch is tracking these failed logins.
Note: This is not intended to be an exhaustive study of CloudWatch, and given enough time, it may be possible to do much more, but we have to move on.
The level of effort for Cloudwatch was several hours just for this one event. AWS has over 200 services, each with multiple events, we will see the impact of that later.
Guard Duty
Next we try AWS GuardDuty, but we are unable to meet the requirements. After reading the AWS GuardDuty documentation, including an excellent blog post that addresses RDS snapshots, it seems that GuardDuty, while very powerful for what it is designed for, is not designed to meet our objectives.
EventBridge
AWS documentation (including this great blog post) shows EventBridge will monitor RDS events, but there is a catch.
The catch is a high bar to climb over: It requires writing custom Node.JS 14.X Lambda function code, and while it appears promising, following the documentation steps and several hours of testing did not result in success, unfortunately. We may have made mistakes, but we are not Node.JS developers, and nor do we want to be. The whole process seems challenging and once again we ran out of time.
Security Hub
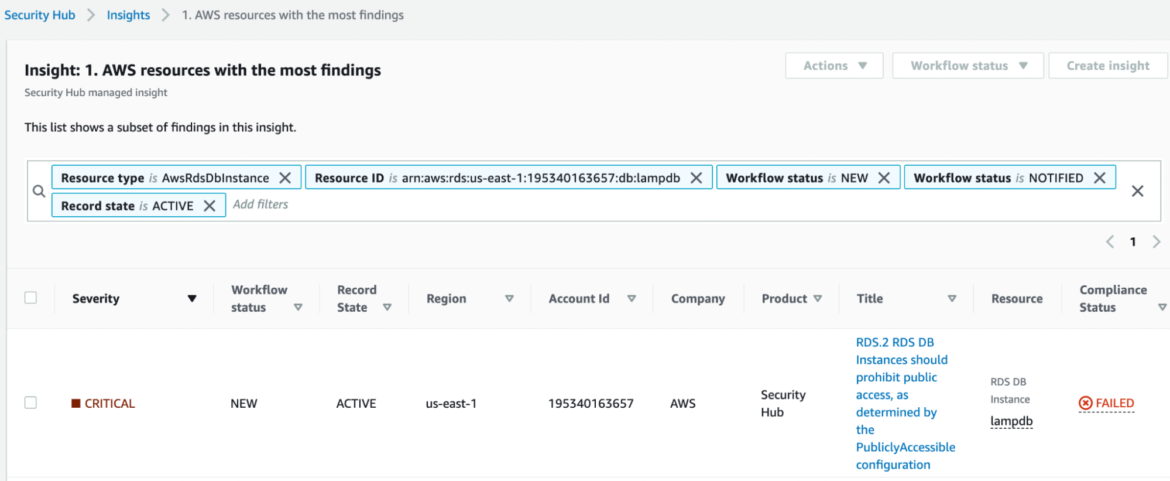
Security Hub looks very promising because it is designed to find the very event we are looking for: Making an RDS instance public. When testing, we found Security Hub does indeed successfully detect the event after roughly 12 hours, which seems like an exceptionally long time to have a database sitting out there exposed on the Internet.
The Security Hub documentation contains the following statement:
"Note that if the configuration is changed to allow public access, the AWS Config rule may not be able to detect the change for up to 12 hours. Until the AWS Config rule detects the change, the check passes even though the configuration violates the rule."
The RDS rules for Security Hub are listed here, but are unfortunately not customizable, and are not very comprehensive. For example, the high-risk event of sharing a snapshot with a foreign AWS account is a glaring omission.
Results of DIY: Painful and Unsuccessful
| DIY Tool | Time Required | Located the Public RDS Event? | Alert created? | Actionable? | Successful? |
| Raw CloudTrail | 1 hour | Yes | No | Yes, we see the Username DB Name, but we don't get alerts | No |
| Athena Query | 1 hour | Yes | No | Yes, we see the IAM user and DB Instance Name | No |
| CloudWatch Metric Alerts | 3 hours | Yes | Yes | No, it does not tell us the Username, nor the DB Instance Name | No |
| EventBridge | 2+ hours | No | No | No | No |
| GuardDuty | 1 hour | No | No | No | No |
| Security Hub | 12+ hours | Yes | Yes | Partial. DB Instance Name is shown, but not the Username | No |
Note: This is still not an apples-to-apples comparison to Sysdig, because we did not build an automation engine, nor a visualization dashboard, nor a reporting system.
The DIY approach falls short of meeting the requirement to be alerted instantly showing who made which database public.
But even if it did, how well does the DIY approach scale? Using the Athena approach as an example, the answer as it turns out is: not very well.
Let's examine the level of effort that might be required.
Assumptions:
- 200 AWS Services and this number will not grow over the next three years
- For each service,
- Finding the exact JSON details in CloudTrail, writing the SQL in Athena, and testing will take 1.5 hours based on what we tried earlier.
- There is an average of 12 risky events per service (some AWS services may have zero, others may have more than 12)
- Eight hour work day and one headcount (resource) on the project
[ 200 x 12 = 2400 events ] x 1.5 hours to DIY each event = 3600 hours
That is the best case, but time estimates must be based on reality.
A good rule of thumb is reality is equal to double the best case.
[ 3600 x 2 = 7200 hours ] / ( 8 hour work day x 5 days/week ) = > 3 years
Besides the 3 years, the final result would be a mountain of SQL that reaches the sky. This would need to be maintained for life, no open community exists to help, and because this is not open source, we can't take it with us.
Sysdig catches Suspicious Events Instantly
As described earlier when we first looked at CloudTrail, the sheer numbers of logs and events can become impossible to manage. This in turn makes it impossible to react in any reasonable timeframe.
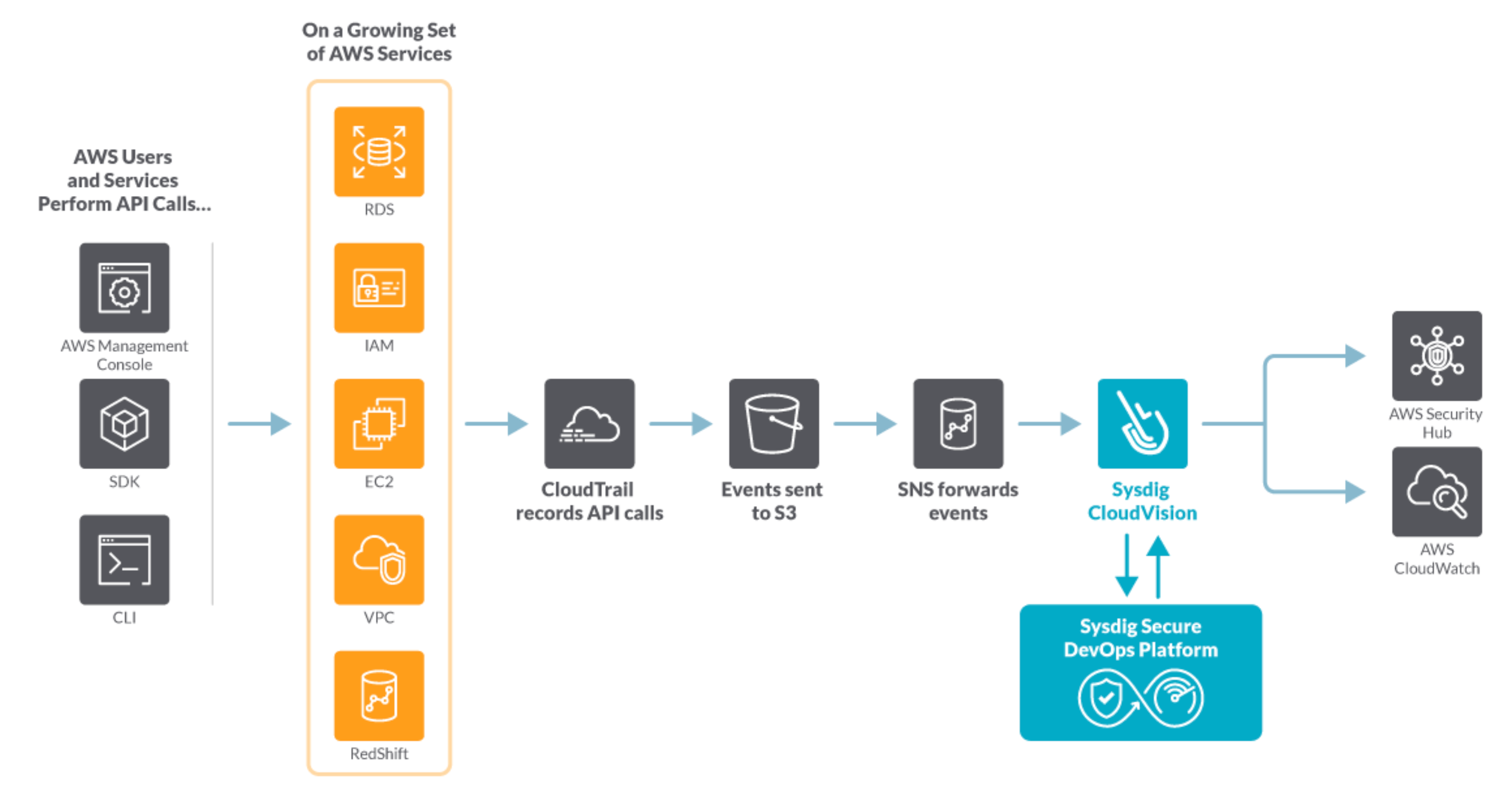
Solving this challenge is where Sysdig Secure comes in. Once deployed in your infrastructure, Sysdig evaluates every CloudTrail entry in real time against a flexible set of security rules.
Like an all-seeing security camera in the cloud, Sysdig Secure continuously watches CloudTrail, and alerts us.
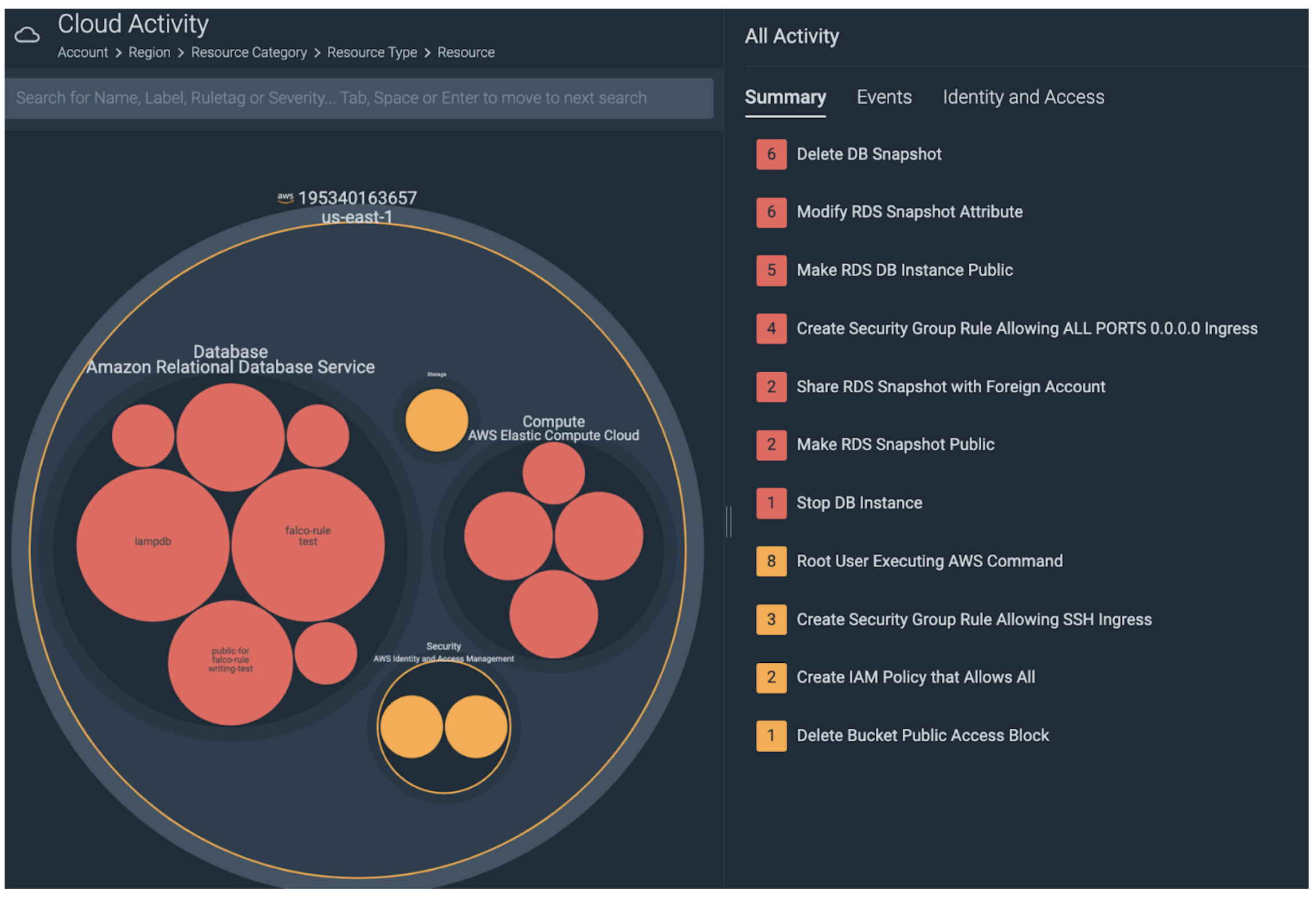
Sysdig Secure Cloud Activity Insights
To get a complete picture of the cloud environment, Sysdig provides the Insights view.
This view scales to high object counts, and while initially we are presented with a high-level overview, the intuitive drill-down workflow enables rapid triage of specific areas.
Here we see the AWS account, within that the RDS services, and within those, the various suspicious RDS events.
Alerting on RDS Events with Sysdig Secure
Compared to DIY using native services, Sysdig Secure promised to be much easier and much more effective.
Installing Sysdig Cloud Connector only requires applying a Terraform plan, takes about 15 minutes, and only has to be done once.
Policies are a construct used to keep rules organized, and can be mixed and matching according to our needs. While Sysdig already includes many out-of-the-box policies for AWS, for this blog we will create a new Runtime Policy named RDS Suspicious Activities:
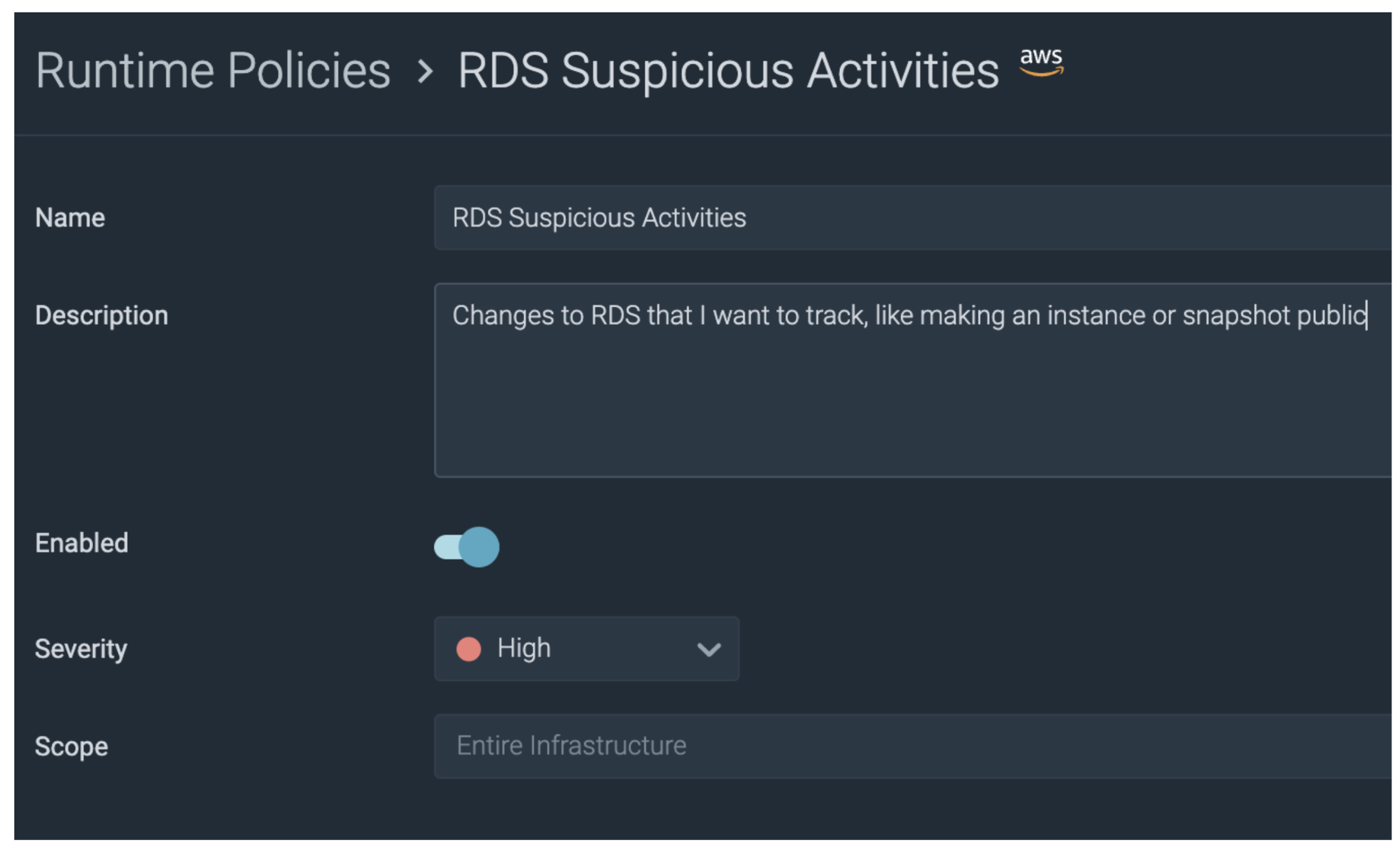
With a few clicks we attach all of the OOTB (out-of-the-box) RDS rules to our new Policy. While this set of rules is comprehensive, we can add our own custom rules as we will see a little later.
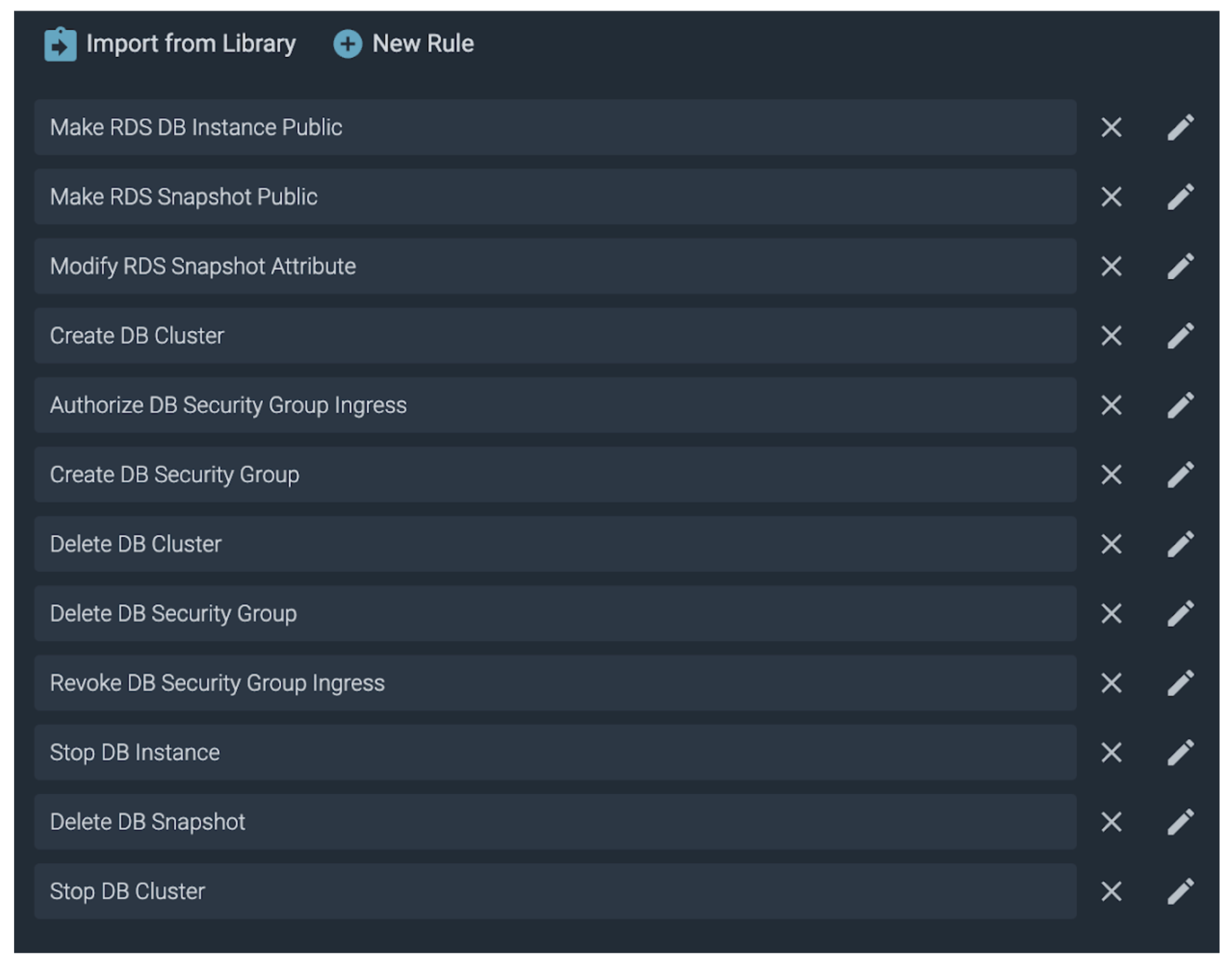
Testing Sysdig Secure
After making the RDS Instance public, Sysdig Secure alerts us almost instantly, exceeding the requirements.
Click start in the micro-demo to see for yourself:
Clicking on the events tab reveals important details including the timestamp, the policy and rule which triggered this. And of course we see the culprit (the user responsible for making the change), the region, and the RDS instance name.
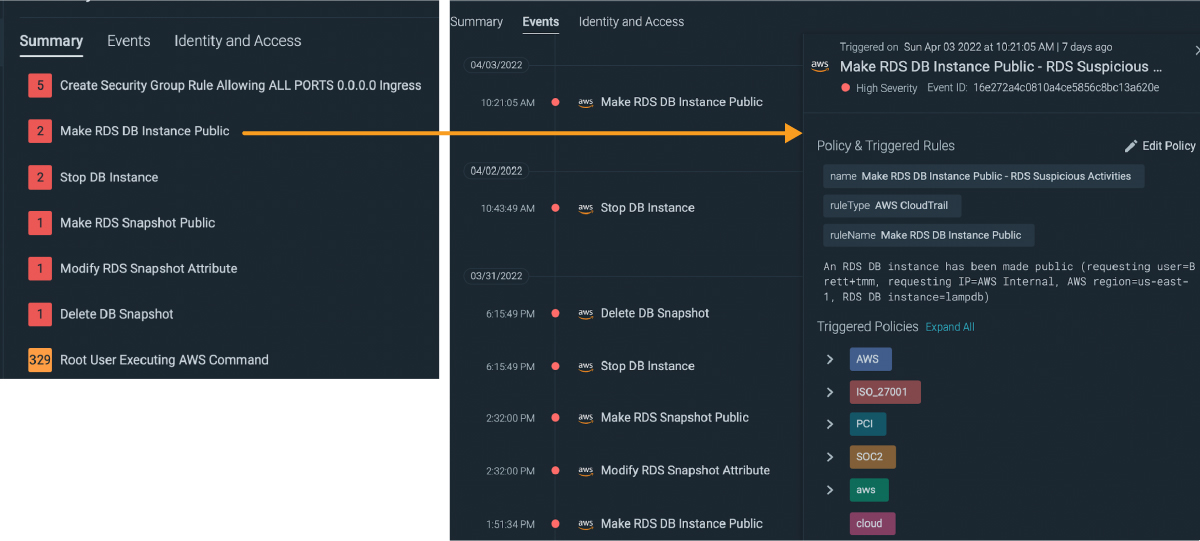
We now have the right information to quickly take evasive action, which in this case should probably include at the very least*
- Making the database private immediately
- Vigorously restricting the privileges of the user
- Examining the logs inside the database itself for any unexpected logins or changes to data or schema
- Taking a snapshot of the current state for forensic purposes
- And we should probably restore from a valid backup that occurred before the first time the database was made public.
Note: This opinionated example is not meant to be a substitute for proper incident response. Please follow your own incident response plan when it comes to anything resembling the types of situations described in this blog post.
Results of using Sysdig: Easy and Effective
Configuring Sysdig Secure for RDS needed low effort and low complexity. In well under a half-hour (including installation) all the requirements were met or exceeded.
Sysdig Secure alerts us the moment a risky event posts to CloudTrail, because nobody can afford to wait around in these types of situations.
We viewed the critical events and triaged the situation using the intuitive Sysdig Insights view, without any additional tools or logging infrastructure.
Extending the Rules
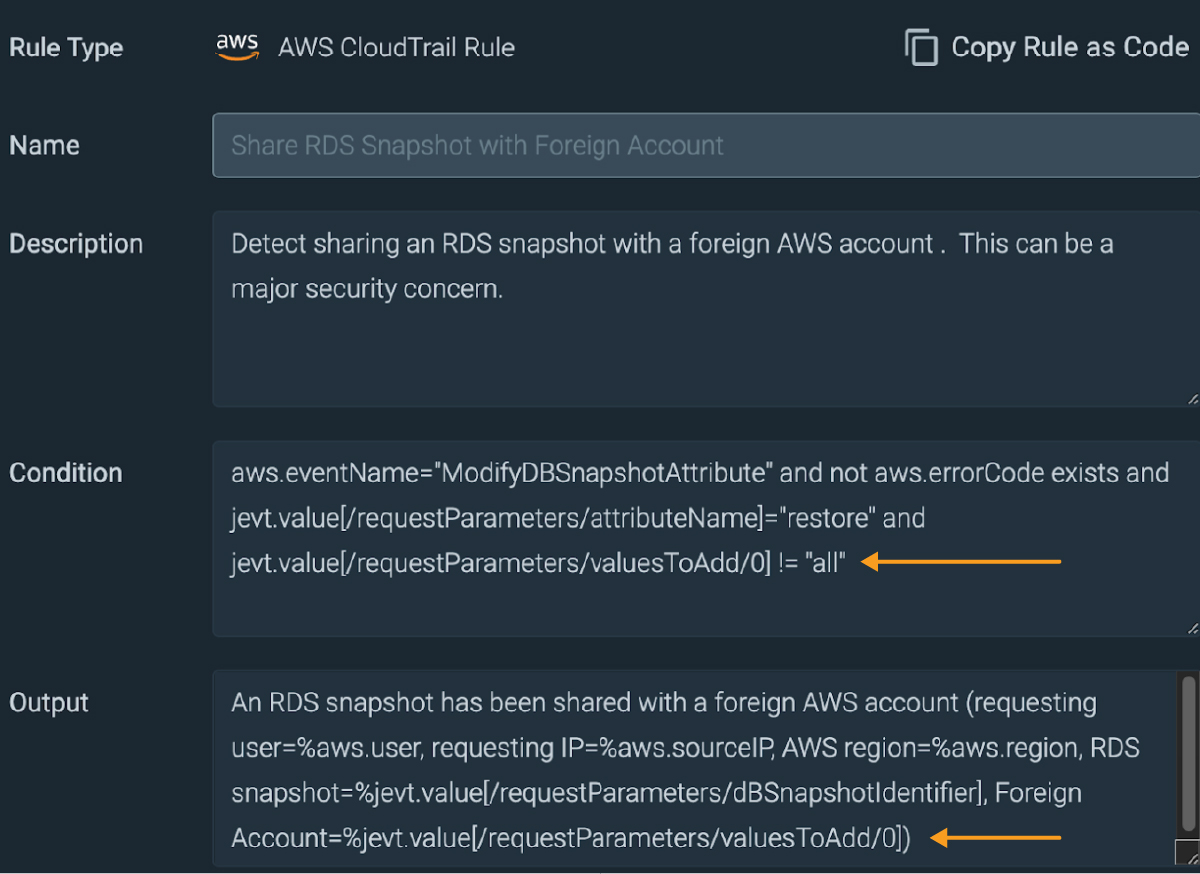
Ever wonder what is happening under the hood? Not knowing how something works can be frustrating. Fortunately, Sysdig rules use the open-source Falco format.
Looking at the CloudTrail event, we can easily see how the key values in this event correspond to the Falco rule.
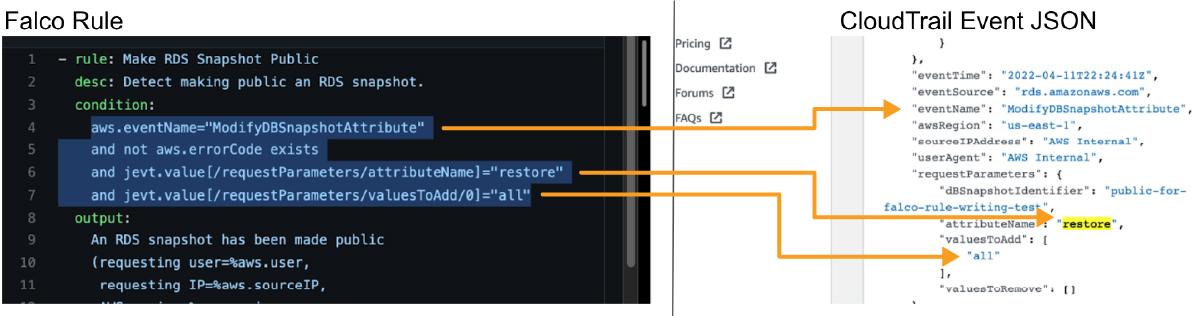

It is even easy to write our own rules to extend the capabilities!
For example, we may wish to know if an RDS Snapshot is shared with a foreign AWS account, an event that might be a data exfiltration attempt.
Instead of writing the rule from scratch, we just copy and paste an existing rule and make a few simple changes. There is no need to read any documentation!

The only changes we make are:
- Inserting just a single ASCII character – a bang! (A zero is CloudTrail's way of indicating Public, so the opposite of zero means a specific AWS account!)
- Adding the target AWS account in the output to capture this in the log.
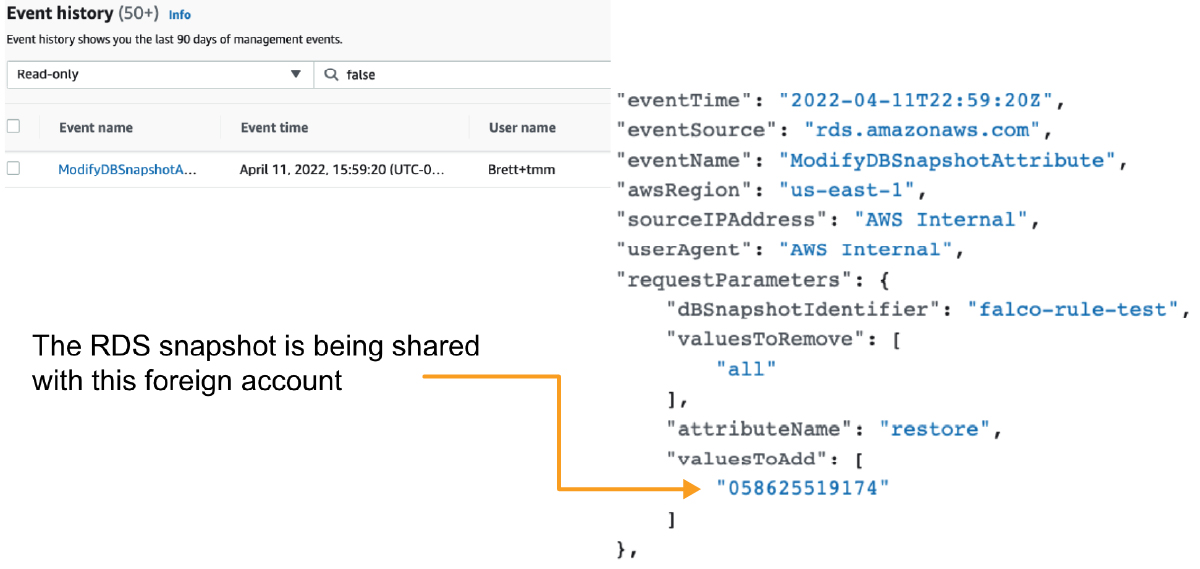
We test by sharing a snapshot with a different AWS account.
This results in the following suspicious event being posted to our Trail:
Checking Sysdig, we easily see the event, confirming that it works!
Start your own hunting Today
In this post, we unearthed several RDS suspicious events that may lead to major security problems. We reviewed how high risk events can occur in post-deployment drift, even if the initial configuration follows best practices.
The data shows public AWS RDS instances exist at significant scale. This is bad news considering we saw how attackers can locate and brute-force public RDS instances.
We dug deep into CloudTrail, uncovered why continuous scanning matters, and discovered the urgency of being alerted as quickly as possible.
DIY is possible, but we found this approach was not very effective. To handle all 200+ AWS services with the DIY approach, we calculated it might take multiple years.
Fortunately, Sysdig Secure provides an out-of-the-box solution in minutes, and we found that extending and adding custom rules is easy to do.
Most importantly, Sysdig Secure enables you to secure not just RDS, but all the AWS services in your environments.
What threats may be lurking in your AWS environment? It's time to start hunting down those high-risk AWS events today, using the right tools for the job. If you have not had the chance already, get started for free with Sysdig Secure to discover how easy this can be.