



Falco Feeds extends the power of Falco by giving open source-focused companies access to expert-written rules that are continuously updated as new threats are discovered.

\rThe situation involving the log4j ( log4shell ) vulnerability has been rapidly evolving since its release a little over a week ago. A new exploit, CVE-2021-45046, was found which was not covered by the initial 2.15.0 patch. Not long after the 2.16.0 patch was released, another issue was found, CVE-2021-45105, which resulted in the release of 2.17.0. There is clearly a lot going on in the log4j library.\r
\r
\rIn such a highly dynamic scenario, standard "scan-patch" vulnerability management is simply not enough. New attack vectors emerge every day, such as through websockets, which could make detection of the exploit attempts even more challenging. There is one thing the attackers using log4j will be hard pressed to change, their post-exploitation activities, and defenders can leverage this to their advantage. \r
\r
\rIn this post we will look at how to use Sysdig Secure to block those activities in your containerized environments. \r
\r\r\r
Response Actions
\r
\rSysdig Secure offers several options to prevent further compromise by using response actions.\r
\r
\rThese include killing, stopping, or pausing the container with notifications using email, webhooks, or other supported methods. These responses are attached to a Policy, which in turn contains a list of rules. When any rule in the policy triggers, we can automatically kill the affected container, preventing any further damage from a compromise. \r
\r
\rResponse actions can be tailored to your incident response processes. \r
\r
\rFor example, a paused container can be retrieved at a later time for forensic analysis. By taking container-specific actions, the entire compromised environment can be easily contained or eradicated while a clean version is restored. \r
\r
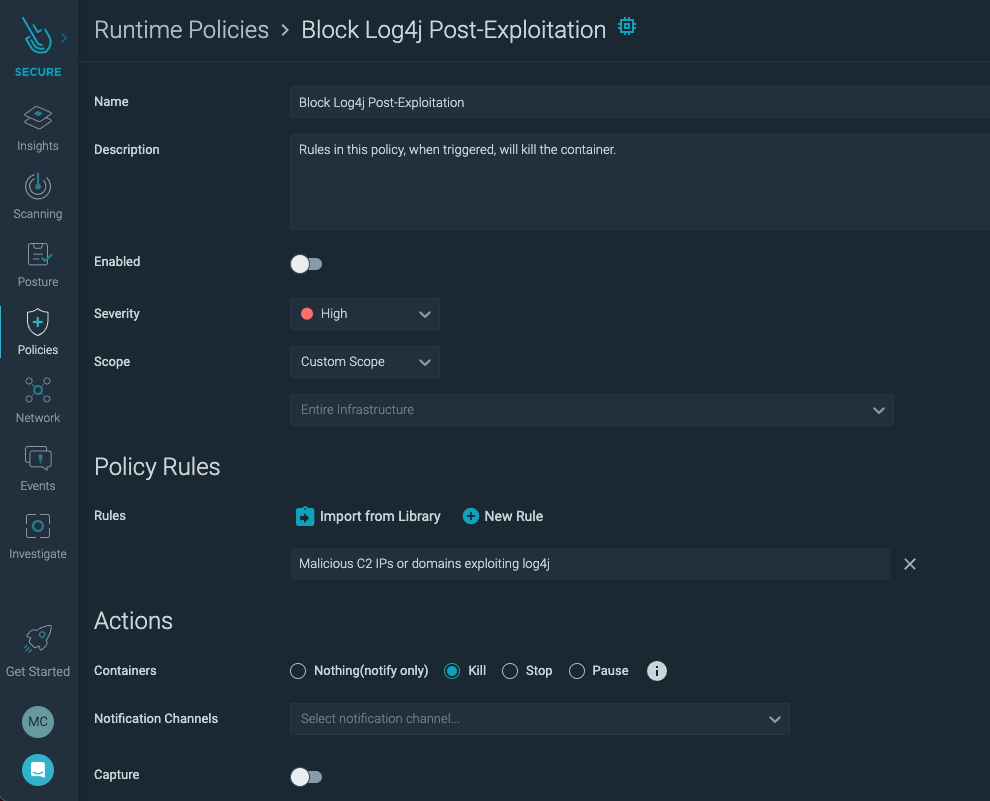
\rWhen creating a policy for the purpose of response for containers, choose a Workload Policy. While choosing the rules in which to import into the policy, consider that they will cause the container to be killed. Only high-confidence, low false positive rules should be chosen for this policy to avoid disrupting unaffected workloads. \r
\r
\rIn our example, we will use the rule "Malicious C2 IPs or domains exploiting log4j" because it is based on known-bad IP addresses used for the egress stage of the exploit, which is a high fidelity indicator of compromise. \r
\r
\rIf you are a Sysdig customer, the list of log4j IoC's will be automatically updated as we gather more information.\r
\r
\rHere is what our policy looks like:\r
\r
\r
\r
\r
\rNotice under Actions, Kill has been selected. Stop and Pause are also options in case your incident response workflow involves examining the container in certain states before destroying it. Once a container is killed, Kubernetes will often attempt to start a new, uncompromised version. \r
\r\r\r
log4j Attack
\r
\rTo show the response actions, we will run a fairly typical log4j attack against a vulnerable container. We have temporarily added the IP address of our test system to the list of Indicators of Compromise in order to trigger the rule that will execute the policy's response action. \r
\r
\rThese IoC's are based on egress/C2 IP Addresses, not addresses seen sending the JNDI attack string.\r
\r
\r
\r
\r
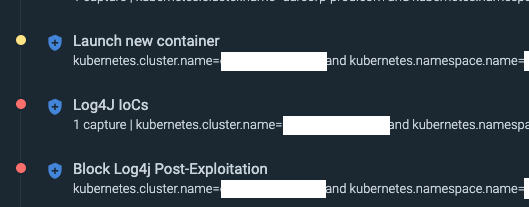
\rThe rules above, explained in chronological order. \r
\r
- \r
- Block Log4j Post-Exploitation\r\r This is the policy we created above that contains both the "Malicious C2 IPs or domains exploiting log4j" rule and the "kill container" action. When the rule is triggered by a malicious IP detection, the action is executed, and the container is killed. Then, the Kubernetes orchestrator will launch a new container to replace the compromised one that we destroyed. \r \r
- Log4J IoCs\r\r This is a similar but more soft policy to the "blocking" version. It contains rules that identify occurrences of log4j IoC's and alert on them. It is only set to generate notifications, not take any actions, so the container will not be killed or replaced by this policy.\r \r
- Launch new container\r\r This policy contains a rule to detect when Kubernetes creates a new container within a pod. Its execution is the result of the "kill" action taken in the first example policy and shows that a new container was deployed to replace the destroyed container.\r\r
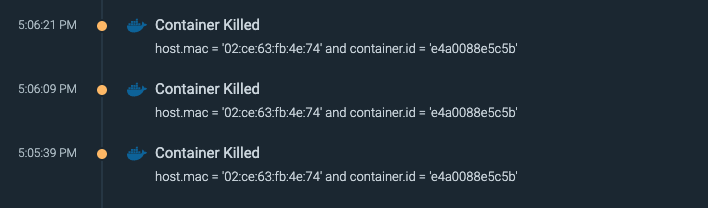
- \r Alternatively, if Sysdig Monitor is enabled the container kill events can be easily viewed on its Events page as seen below.\r
- \r
- \r
\r\r
Rules
\r
\r
- list: "malicious_log4j_c2"\r
items:\r
- "\"5.255.97.172\""\r
- "\"18.228.7.109\""\r
- "\"31.6.19.41\""\r
…\r
\r
\r
- rule: "Malicious C2 IPs or domains exploiting log4j"\r
desc: "Malicious commands detected in pod or host. The rule was triggered by IPs\r
or domains that exploit log4j"\r
condition: "evt.type = connect and evt.dir = < and fd.sip in (malicious_log4j_c2)
"\r
exceptions: []\r
output: "Malicious connections to C2 IPs or domains detected in pod or host exploiting\r
log4j. %proc.cmdline %evt.args"\r
priority: "WARNING"\r
tags: []\r
source: "syscall"\r
\r
\rThe "malicious_log4j_c2" was collected using OSINT sources, such as this greynoise.io gist.\r
\r
\r
- rule: "Launch new container"\r
desc: "Detect the initial process started in a new container. Exceptions are made\r
for known trusted images."\r
condition: "evt.type=container and container and not falco_privileged_containers\r
and not user_privileged_containers\r
output: "New container started (user=%user.name user_loginuid=%user.loginuid command=%proc.cmdline\r
%container.info image=%container.image.repository:%container.image.tag)"\r
priority: "NOTICE"\r
tags:\r
- "container"\r
\r\r\r
Conclusion
\r
\rAlthough patching and preventing attacks are the ideal response to a zero day, in cases like log4j, the threat evolves faster than teams can respond. \r
\r
\rWhen that happens, response actions triggered by post-exploitation behaviors can help limit the damage an attacker can do. Post-exploitation indicators are much more difficult for attackers to change, making this defensive tactic harder to evade. \r
\r
\rSysdig Secure allows you to respond to active attacks in a cloud-appropriate way by killing just the affected container instead of isolating the entire system. \r
\r\r\r
\rAt Sysdig Secure, we extend Falco with out-of-the-box rules along with other open source projects, making them even easier to work with and manage Kubernetes security. Register for our Free 30-day trial and see for yourself!\r