
Microsoft has discovered a new large-scale attack targeting Kubeflow instances to deploy malicious TensorFlow pods, using them to mine Monero cryptocurrency in Kubernetes cluster environments.
Kubeflow is a popular open-source framework often used for running machine learning tasks in Kubernetes. TensorFlow, on the other hand, is an open-source machine learning platform used for implementing machine learning in a Kubernetes environment.
Machine learning workloads require huge amounts of processing power, and they often have access to GPUs. As those are the same requirements for a crypto mining rig, clusters running Kubeflow and TensorFlow are the perfect targets for these attacks.
One would think that with the value of crypto mining crashing, crypto mining attacks should be less frequent. However, not only do we keep seeing these attacks, but we are also discovering new variants specifically targeting machine learning workloads.
Since the attack is really recent and perhaps still ongoing, any new Kubernetes clusters that run Kubeflow could already be compromised.
Affected users may notice degraded performance and an increase on their infrastructure bills due to the intensive crypto mining process.
In this article, we’ll introduce you to Kubeflow and TensorFlow, track how this attack works, and cover steps to detect if you are affected, and mitigate its effects.

What are Kubeflow and TensorFlow?
Kubeflow is an end-to-end Machine Learning (ML) project that provides infrastructure components for each stage in the ML lifecycle. It is built on top of Kubernetes to reuse k8s core components, adapting them for specific machine learning use cases.
Kubeflow provides different components to support the machine learning deployment in a Kubernetes cluster. In particular, the component Kubeflow Pipelines is used to create a complete machine learning workflow.
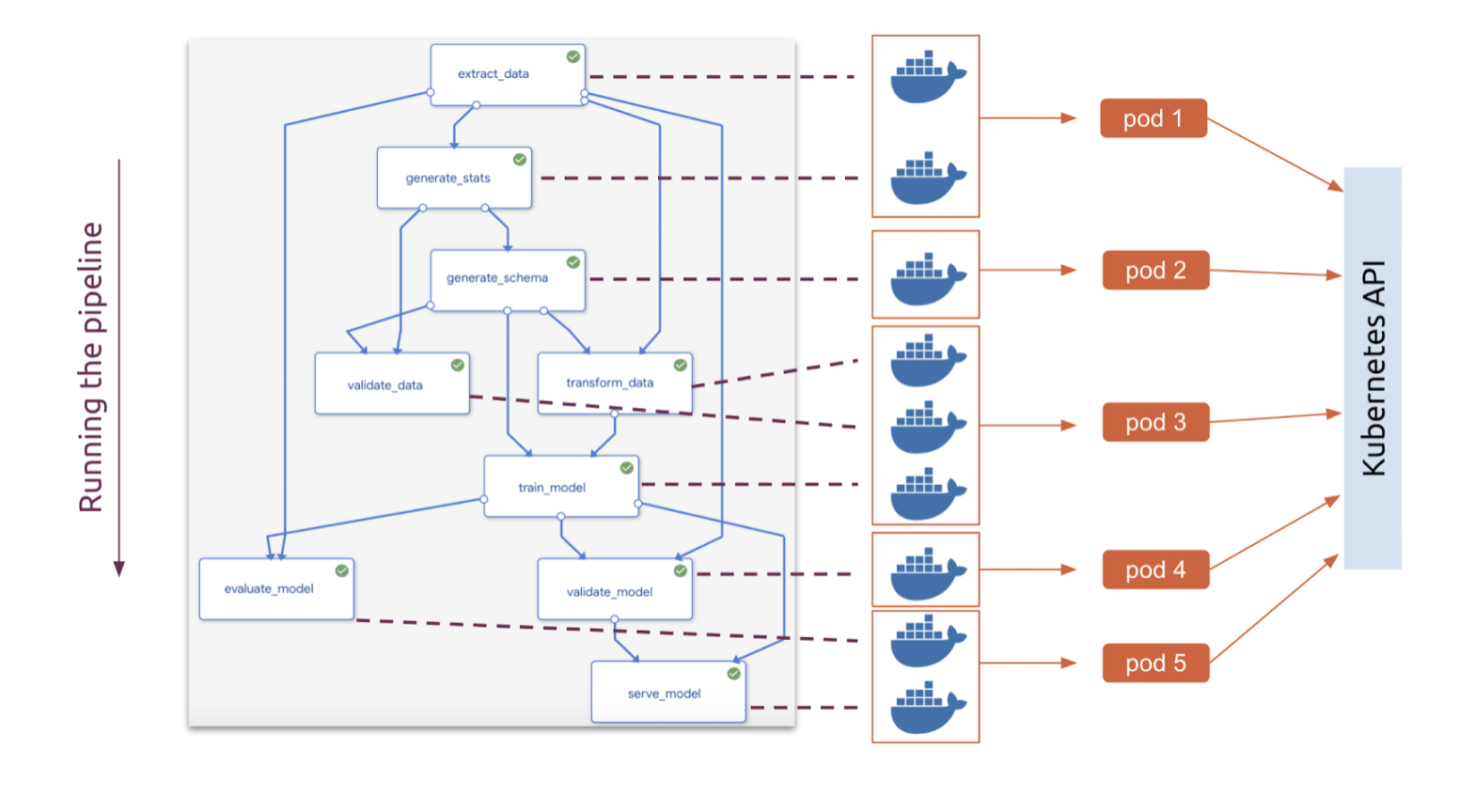
A pipeline is a series of steps, each one is an independent container. Each step is a piece of code packaged as an image which contains inputs and outputs and performs a specific machine learning task. All together they form the ML workflow.
Using Kubeflow Pipelines, it’s possible to deploy TensorFlow models in Kubernetes environments.
Tensorflow (TF) is a general purpose graph-based computation engine. TF offers an abstraction for building and training machine learning models. Furthermore, TF provides a full production ML pipeline to simplify the model release and the framework also supports GPU hardware acceleration.
Now that we have a brief overview of Kubeflow and TensorFlow, we can move on to the attack scenario and the security issue.
The Attack Scenario
Microsoft observed a consistent increase of TensorFlow pods deployed on various Kubernetes clusters. Different from what sometimes happens in similar attacks, the pods used are the legitimate TensorFlow images from the official Docker Hub account.
The two different TensorFlow images used were:
- tensorflow/tensorflow:latest: Latest version of TensorFlow.
- tensorflow/tensorflow:latest-gpu: Latest version of TensorFlow with GPU support.
In the attack scenario reported by Microsoft, the attackers were able to:
- Get access to the Kubeflow UI dashboard.
- Create a new deployment pipeline in the infrastructure.
- With a new pipeline, they proceeded with the Tensorflow images deployment and the execution of additional malicious code.
The malicious code downloaded and executed the famous Monero miner in the Kubernetes cluster, and started mining.
The issue
The Kubeflow dashboard is exposed by the Istio ingress gateway and is accessible by default internally only. Using the port-forward mechanism, users are able to access the dashboard and tunnel the traffic through the Kubernetes API server.
Users prefer a more flexible and immediate way to access the service without any hassles. In this case, by setting the Istio Service to Load-Balancer, the service is going to be exposed on the Internet, allowing users to access the UI directly. This flexibility and easy-to-use configuration might open a big security issue since the dashboard is directly exposed on the Internet without any restrictions.
Combining this configuration with weak credentials may end in a compromission of the entire environment.
This is a quite common pattern where attackers use legitimate images for running their malicious code. In this case, if the company is using TensorFlow images in the cluster for machine learning purposes, the new pipeline might look totally legitimate.
In the attack reported, adversaries use totally legitimate images even though security mechanisms are in place, so the malicious deployment won’t be detected at all. In addition, the TensorFlow images are optimized to run machine learning tasks efficiently, which require a huge amount of computational resources.
This is exactly what attackers are looking for. The chance to compromise this kind of infrastructure and image is absolutely priceless for adversaries, allowing the attacker to maximize the mining gains from the host.
Mitigating the attack
For this specific scenario, the attack was possible due to the change in the configuration to publicly expose the Kuberflow centralized dashboard on the internet, which is a huge security issue.
To mitigate this issue:
- All the management dashboards and consoles should be kept internal only and not reachable using port forwarding or another mechanism.
- In case that the service must remain public, strong authentication mechanisms should be in place, using complex passwords or MFA mechanisms.
Detecting the attack
What has been reported by Microsoft emphasizes the trend we have seen in the recent years, where mine cryptocurrency is still one of the main attacks performed by attackers. Blue teams need to have efficient and powerful detection mechanisms to identify these kinds of compromissions and bad behaviors as soon as possible.
Luckily, the detection of this specific attack scenario can be done in different ways and with different tools. Since crypto miners follow very distinctive patterns, we can use their behavior to create a strong detection.
One way is using infrastructure monitoring tools, scanning the pod resources used, and alerting on high CPU or GPU usage.
The other option is the “security” way, by detecting suspicious connections or malicious binary executions inside the pod.
Let’s dive into both approaches.
Falco Detection
Falco is the CNCF open-source project for runtime threat detection for containers and Kubernetes.
One of the benefits of Falco is in leveraging its powerful and flexible rules language. As a result, Falco will generate security events when it finds abnormal behaviors as defined by a customizable set of rules. Meanwhile, Falco comes with a handful of out-of-the-box detection rules.
The following rules will detect both crypto miner processes, and connections to mining pools:
# Note: falco will send DNS request to resolve miner pool domain which may trigger alerts in your environment.
- rule: Detect outbound connections to common miner pool ports
desc: Miners typically connect to miner pools on common ports.
condition: net_miner_pool and not trusted_images_query_miner_domain_dns
enabled: false
output: Outbound connection to IP/Port flagged by cryptoioc.ch (command=%proc.cmdline port=%fd.rport ip=%fd.rip container=%container.info image=%container.image.repository)
priority: CRITICAL
tags: [network, mitre_execution]
- rule: Detect crypto miners using the Stratum protocol
desc: Miners typically specify the mining pool to connect to with a URI that begins with 'stratum+tcp'
condition: spawned_process and proc.cmdline contains "stratum+tcp"
output: Possible miner running (command=%proc.cmdline container=%container.info image=%container.image.repository)
priority: CRITICAL
tags: [process, mitre_execution]
- rule: Container Drift Detected (chmod)
desc: New executable created in a container due to chmod
condition: >
chmod and
consider_all_chmods and
container and
not runc_writing_var_lib_docker and
not user_known_container_drift_activities and
evt.rawres>=0 and
((evt.arg.mode contains "S_IXUSR") or
(evt.arg.mode contains "S_IXGRP") or
(evt.arg.mode contains "S_IXOTH"))
exceptions:
- name: proc_name_image_suffix
fields: [proc.name, container.image.repository]
comps: [in, endswith]
- name: cmdline_file
fields: [proc.cmdline, fd.name]
comps: [in, in]
values:
- [["runc:[1:CHILD] init"], [/exec.fifo]]
output: Drift detected (chmod), new executable created in a container (user=%user.name user_loginuid=%user.loginuid command=%proc.cmdline filename=%evt.arg.filename name=%evt.arg.name mode=%evt.arg.mode event=%evt.type)
priority: ERROR
- rule: Outbound Connection to C2 Servers
desc: Detect outbound connection to command & control servers
condition: outbound and fd.sip in (c2_server_ip_list)
exceptions:
- name: proc_proto_sport
fields: [proc.name, fd.l4proto, fd.sport]
output: Outbound connection to C2 server (command=%proc.cmdline connection=%fd.name user=%user.name user_loginuid=%user.loginuid container_id=%container.id image=%container.image.repository)
priority: WARNING
tags: [network]
Resource Monitoring
Since the main adversaries goal is to run a crypto miner in your infrastructure and use your resources for cryptocurrency, it’s possible to use any monitoring tool to check and get alerted in case something is using a high percentage of cpu inside your infrastructure.
To discover a significant increase of pods, we can compare the current existing pods per namespace versus the ones existing 1 day ago at the same hour of the day. This is a metric that can present noise, especially if kubeflow is creating and destroying pods. To remove the noise, we can average over the last hour.
We could query such data with PromQL:
100 * avg_over_time(sum by (namespace) (kube_pod_info)[1h:1h]) / avg_over_time(sum by (namespace) (kube_pod_info)[1h:1h] offset 5m)
The result of this query will show the percentage of additional pods in different namespaces, on average per hour, that are running currently, compared with the number of pods running yesterday at the same hour.
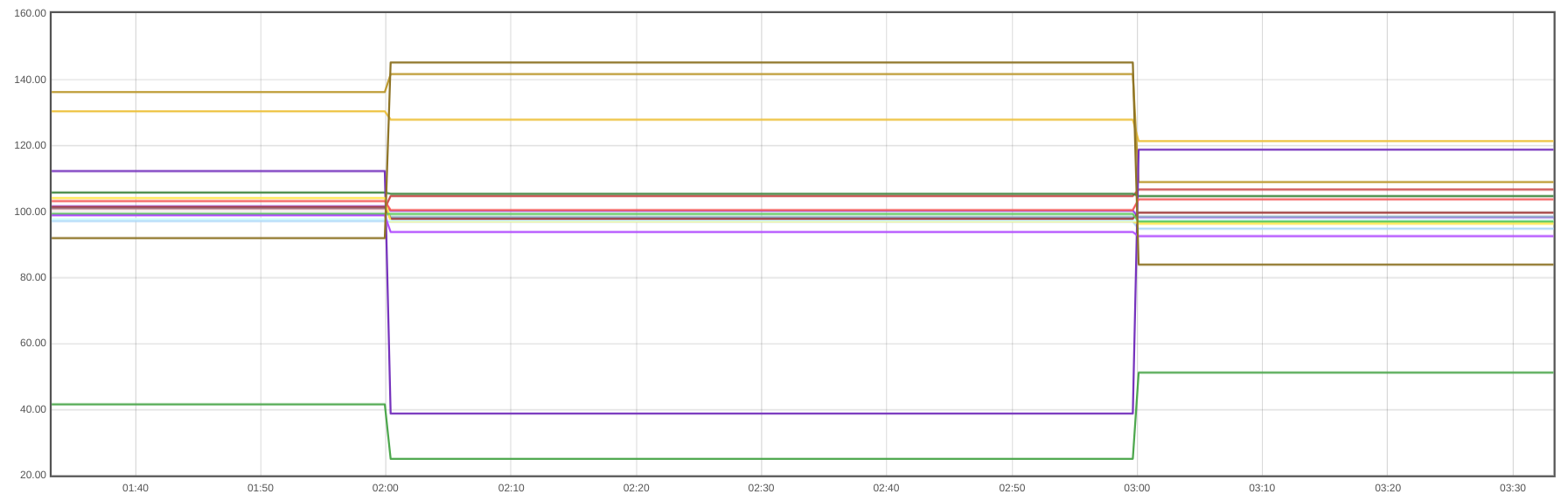
You can set an alert with this PromQL query, setting a threshold for example of 125. This will mean that if there are 25% more pods than yesterday, you’ll receive an alert.
100 * avg_over_time(sum by (namespace) (kube_pod_info)[1h:1h]) / avg_over_time(sum by (namespace) (kube_pod_info)[1h:1h] offset 5m) > 125
We can also do something similar with the amount of CPU used by namespace. The query would be:
100 * avg_over_time(sum by (namespace)(rate(container_cpu_usage_seconds_total{container!="POD",container!=""}[5m]))[1h:1h]) / avg_over_time(sum by (namespace)(rate(container_cpu_usage_seconds_total{container!="POD",container!=""}[5m]))[1h:1h] offset 1d)
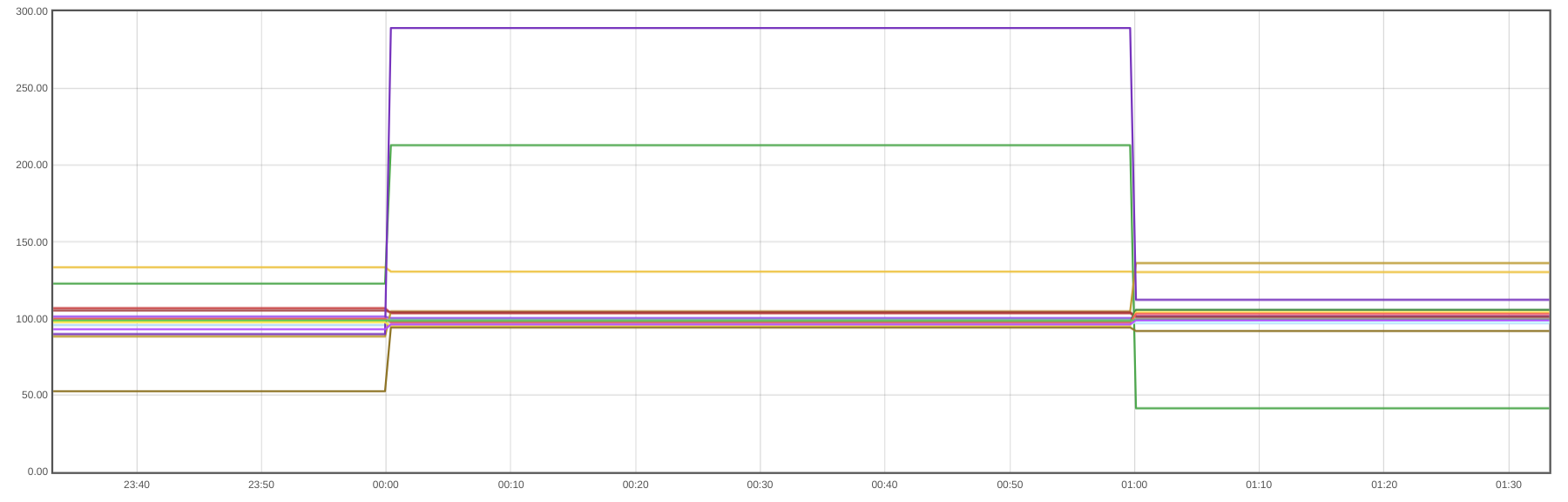
In a similar way, we can set alerts to detect that the CPU per namespace is 50% over the CPU used yesterday at the same hour of the day:
100 * avg_over_time(sum by (namespace)(rate(container_cpu_usage_seconds_total{container!="POD",container!=""}[5m]))[1h:1h]) / avg_over_time(sum by (namespace)(rate(container_cpu_usage_seconds_total{container!="POD",container!=""}[5m]))[1h:1h] offset 1d) > 150
Conclusion
Despite the huge drop in value of cryptocurrency, your infrastructure is still free money for attackers. It’s even more so if your cluster is powerful enough to run machine learning workloads.
Security best practices, like keeping your management tools private or using strong authentication mechanisms, will help you mitigate such attacks.
Fortunately, these attacks are easy to detect. Security tools like Falco can detect crypto mining processes and connections to mining pools, and your monitoring solution can help you detect a rise in resource usage.
If you would like to find out more about Falco:
- Get started in Falco.org.
- Check out the Falco project in GitHub.
- Get involved with the Falco community.
- Meet the maintainers on the Falco Slack.
- Follow @falco_org on Twitter.
Sysdig Secure extends Falco with out-of-the-box rules along with other open source projects, making them even easier to work with and manage Kubernetes security. Register for our Free 30-day trial and see for yourself!