

This release brings 50 enhancements, up from 43 in Kubernetes 1.20 and 34 in Kubernetes 1.19. Of those 50 enhancements, 15 are graduating to Stable, 14 are existing features that keep improving, and a whopping 19 are completely new.
It’s great to see old features, that have been around as long as 1.4, finally become GA. For example CronJob, PodDisruptionBudget, and sysctl support.
In the same way, it is unfortunate to see the deprecation of security features like Pod Security Policies.
There is plenty to talk about, so let’s get started with what’s new in Kubernetes 1.21.
Kubernetes 1.21 – Editor’s pick:
These are the features that look most exciting to us in this release (ymmv):
#1769 Memory manager
Memory is vital to ensure the performance of some applications, like Databases. A performance hit might be unacceptable in these workloads. Features like the new Memory manager are making migrating delicate deployments to Kubernetes more attractive.
Carlos Arilla – Manager, Integrations Engineering at Sysdig
#1923 & #2249 Scheduler: Nominated nodes and Pod affinity selector
Kubernetes is constantly acknowledging that not all workloads are the same. This speaks to the maturity this project is reaching. Since the main use cases are mostly covered and more resources are available, effort can be redirected to customization and edge cases.
More flexibility and control on how a node is chosen to deploy a Pod is really welcome, as it will make it easier to manage big clusters. Making life easier to cluster administrators is a key for Kubernetes adoption.
Jesús Ángel Samitier – DevOps Content Engineer at Sysdig
#2185 & #2255 ReplicaSet downscaling
Kubernetes autoscaling is one of its greatest features. However, there has been little control on what happens after a load spike passes and it’s time to downscale.
Having two new strategies to downscale clusters (semi-random and cost-based) will remove the need for manual checks. This makes Kubernetes friendlier to workloads that require high availability.
Carlos Arilla – Manager, Integrations Engineering at Sysdig
#2214 Indexed Job
This enhancement simplifies deploying highly parallelizable workloads into Kubernetes. Hello, scientific researchers? I’m hyped right now with the doors Kubernetes are opening lately.
Víctor Jiménez – Content Engineering Manager at Sysdig
#2079 Network policy port ranges
Simpler configuration files makes everyone happy. Now, if I want to define a network policy over 20 consecutive ports, I no longer have to write 20 rules… Just one!
Jesús Ángel Samitier – DevOps Content Engineer at Sysdig
Deprecations in Kubernetes 1.21
#5 Pod Security Policy
Feature group: auth
Pod Security Policies (PSPs) are a great Kubernetes-native tool to restrict what deployments can do, like limiting the execution to a list of users, or access resources like the network or volumes.
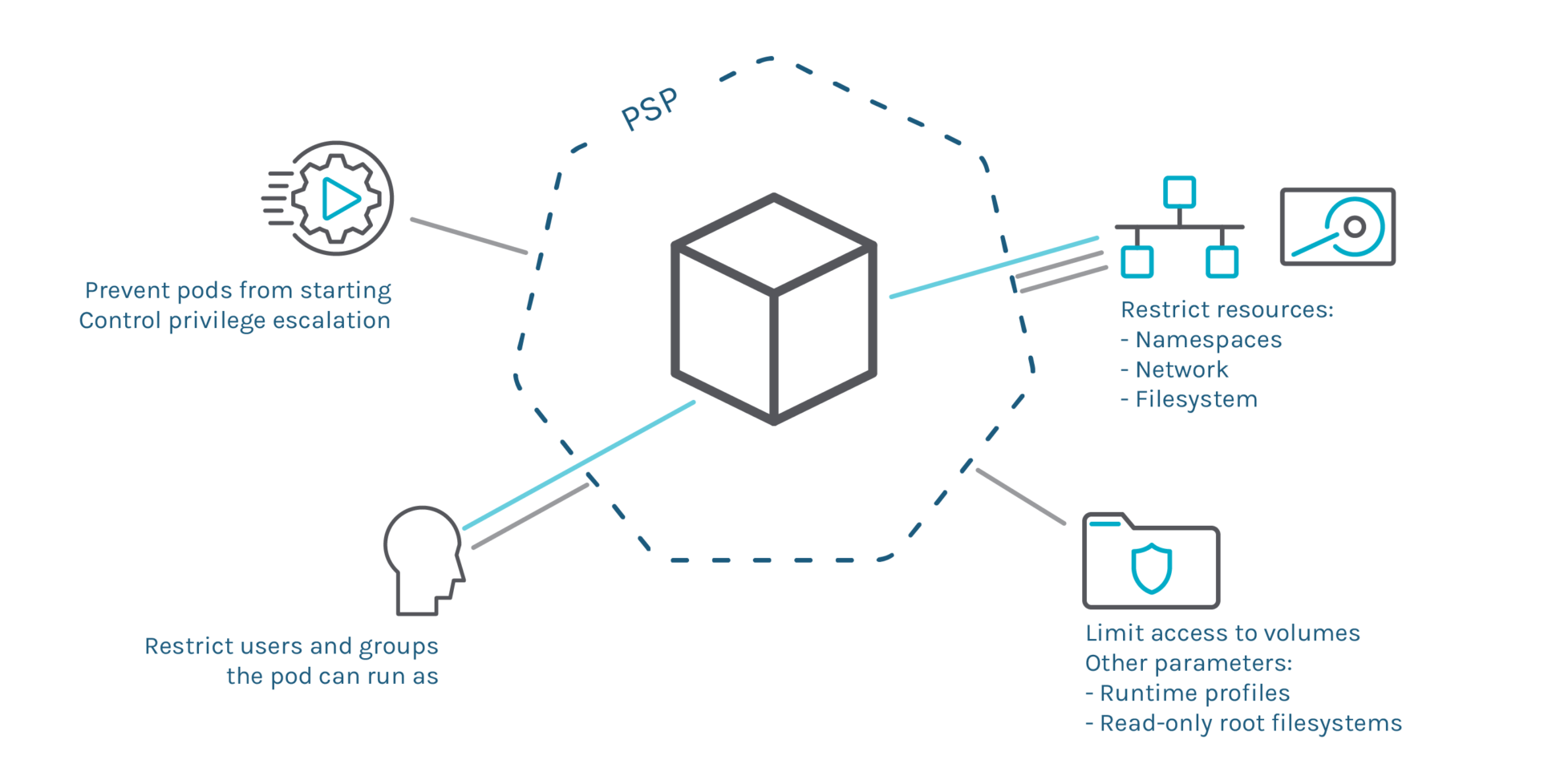
Although it’s been in beta since 1.8, this feature has serious limitations that block its GA release. The dual authorization model weakens security, can’t be enabled by default, and the API has grown with lots of inconsistencies.
Following the new feature promotion model, introduced in Kubernetes 1.19, work on PSPs should have started to make this a stable feature. The Kubernetes team is deciding the next steps. Should they fix all the PSPs flaws in a v2 that breaks compatibility? Should they maintain backward compatibility, possibly complicating development? Should they abandon this feature and let the existing alternatives take over?
There is not a clear path at the moment. As a result, Pod Security Policies are being marked as deprecated in Kubernetes 1.21 and will be completely removed in Kubernetes 1.25.
#536 Topology aware routing of services
Feature group: network
Initially introduced in Kubernetes 1.17, this feature aimed for a more efficient network routing between Kubernetes services.
This has been deprecated in favor of #2433 and #2086.
Scheduling in Kubernetes 1.21
#1923 Prefer nominated node
Stage: Alpha
Feature group: scheduling
When scheduling a pod, evaluating all nodes looking for the best candidate can be time-consuming in large clusters. To speed up the process, this feature lets you define a preferred node with the .status.nominatedNodeName field inside a Pod. If the pod doesn’t fit in the nominated node, the scheduling cycle will continue to evaluate the rest of the nodes in the cluster as usual.
To check all of the details of this feature, check the KEP.
#2249 Pod affinity NamespaceSelector and scope
Stage: Alpha
Feature group: scheduling
By defining node affinity in a deployment, you can constrain which nodes your pod will be scheduled on.
For example, deploy on nodes that are already running Pods with a label-value for an example-label:
apiVersion: v1
kind: Deployment
…
spec:
…
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: example-label
operator: In
values:
- label-value
namespaces: […]
namespacesSelector: …
…
By default, these constraints are calculated against the pods in the same namespace, or in the ones listed in the namespaces field. However, you may not know the namespace names in advance, or you may prefer to use another property that’s more specific.
This enhancement adds a namespaceSelector field so you can specify the namespaces by their labels, rather than their names. With this field, you can dynamically define the set of namespaces.
The affinity term is applied to all the namespaces selected by namespaceSelector and namespaces field.
As there are some security implications that come from targeting a deployment where a namespace is running, this enhancement also introduces the CrossNamespaceAffinity resource quota scope. For example, to block deployments of the foo-ns namespace from using the namespaceSelector feature, you can set a quota with a hard limit of 0:
apiVersion: v1
kind: ResourceQuota
metadata:
name: disable-cross-namespace-affinity
namespace: foo-ns
spec:
hard:
pods: "0"
scopeSelector:
matchExpressions:
- scopeName: CrossNamespaceAffinity
Kubernetes 1.21 Apps
#2185 Random Pod selection on ReplicaSet downscale
Stage: Alpha
Feature group: apps
The current downscaling algorithm for ReplicaSets deletes the Pods that have been running for the least amount of time. But this heuristic is bad for high availability scenarios, as it imbalances the replica distribution.
To mitigate this, the LogarithmicScaleDown feature gate has been added. When enabled, a semi-random selection of Pods will be used, based on logarithmic bucketing of pod timestamps.
#2255 ReplicaSet Pod deletion cost
Stage: Alpha
Feature group: apps
As mentioned in the previous enhancement, when scaling down, the youngest Pods are the first to go. This is far from ideal in several use cases.
This enhancement adds to Kubernetes 1.21 yet another heuristic to select pods while scaling down.
In particular, you can now annotate Pods with controller.kubernetes.io/pod-deletion-cost=10, with 0 being the default value. A best effort will be made to remove Pods with a lower deletion cost.
#2214 Indexed Job
Stage: Alpha
Feature group: apps
This enhancement makes it easier to schedule highly parallelizable Jobs (also known as embarrassingly parallel).
apiVersion: batch/v1 kind: Job metadata: name: 'indexed-job' spec: completions: 5 parallelism: 3 completionMode: Indexed …
When using completionMode: Indexed, each Pod gets a different index in the range 0 to completions – 1. The Job will be considered complete when there is one successfully completed Pod for each index.
Learn all the details about this feature in the documentation.
#2232 Stopped Job
Stage: Alpha
Feature group: apps
A Job creates one or more Pods and will continue to retry execution of the Pods until a specified number of them successfully terminate. As pods successfully complete, the Job tracks those successful completions.
Since Kubernetes 1.21 Jobs can be temporarily suspended by setting the .spec.suspend field of the job to true, and resumed later by setting it back to false.
#19 Graduate CronJob to stable
Stage: Graduating to Stable
Feature group: apps
Introduced in Kubernetes 1.4 and in beta since 1.8, CronJobs are finally on the road to become Stable.
CronJobs runs periodic tasks in a Kubernetes cluster, similar to cron on UNIX-like systems.
Read more on the release for 1.20 in the What’s new in Kubernetes series.
#85 PodDisruptionBudget and /eviction subresource
Stage: Graduating to Stable
Feature group: apps
Introduced in Kubernetes 1.4 and in beta since 1.5, PodDisruptionBudget finally graduates to Stable.
With this API, you can define a minAvailable number of replicas for a Pod. If you try to voluntarily disrupt a Pod in a way that violates minAvailable value, it won’t be deleted.
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: zk-pdb
spec:
minAvailable: 2
selector:
matchLabels:
app: zookeeper
A noteworthy change between the policy/v1beta1 and policy/v1 APIs is the default value of this field. In the beta, an empty selector matches zero pods, while for policy/v1, an empty selector matches every pod in the namespace.
#592 TTL after finished controller
Stage: Graduating to Beta
Feature group: apps
This feature will clean up Finished or Complete jobs automatically. This is helpful, as these Jobs are usually no longer needed in the system and keeping them around will generate more load in the API server.
A ttlSecondsAfterFinished field can now be configured to have a controller clean them.
This feature is now enabled by default. Read more in the Jobs docs.
Read more on the release for 1.12 in the What’s new in Kubernetes series.
Instrumentation in Kubernetes 1.21
#2305 Metric cardinality enforcement
Stage: Alpha
Feature group: instrumentation
In the past, there have been occurrences of metrics causing memory leaks. In those cases, the issue couldn’t be solved until a new Kubernetes binary was released.
To mitigate the issue, this enhancement introduces two new command line options in Kubernetes 1.21.
The --disabled-metrics flag will allow you to disable problematic metrics.
The --allow-label-value option allows you to define a list of accepted values for a metric.
#1209 Metrics stability enhancement
Stage: Graduating to Stable
Feature group: instrumentation
This enhancement follows up on the recent efforts to better handle the deprecation of Kubernetes features.
Currently, metrics fall into either the ALPHA or the STABLE categories. Alpha metrics can be deleted at any time, but stable metrics are guaranteed to not change. So a deprecation life cycle has been put into place to better handle deprecation of stable metrics.
When a stable metric is deprecated, it will first be marked as deprecated. This will come in the form of a notice in the description text (Deprecated from x.y), and a warning log will be emitted during the metric registration.
After a couple of releases, the metric will be hidden, not being registered by default. Sysadmins can enable those metrics back with the command line option --show-hidden-metrics-for-version.
On the next release, the metric will be removed.
#1602 Structured logging
Stage: Graduating to Beta
Feature group: instrumentation
This enhancement defines a standard structure for Kubernetes log messages, like:
E1025 00:15:15.525108 1 controller_utils.go:114] "Failed to update pod status" err="timeout"
Read more on the release for 1.19 in the What’s new in Kubernetes series or in the Kubernetes documentation.
#1748 Expose metrics about resource requests and limits that represent the pod model
Stage: Graduating to Beta
Feature group: instrumentation
The kube-scheduler now exposes more metrics on the requested resources and the desired limits of all running pods. This will help cluster administrators better plan capacity and triage errors.
Read more on the release for 1.20 in the What’s new in Kubernetes series.
#1933 Defend against logging secrets via static analysis
Stage: Graduating to Beta
Feature group: instrumentation
Static analysis performed while preparing #1753 to provide insight on where sensitive data is used.
Read more on the release for 1.20 in the What’s new in Kubernetes series.
Kubernetes 1.21 Network
#1959 Service Type=LoadBalancer Class
Stage: Alpha
Feature group: network
This enhancement allows you to leverage multiple Service Type=LoadBalancer implementations in a cluster by introducing the service.spec.loadBalancerClass field in Service.
This is already addressed for the GatewayClass resource. However, this enhancement serves as a light-weight alternative until the Gateway API becomes mature.
#2079 Network policy port ranges
Stage: Alpha
Feature group: network
Currently, when defining a NetworkPolicy, you need to specify all the ports in a range one by one:spec:
egress:
- ports:
- protocol: TCP
port: 32000
- protocol: TCP
port: 32001
…
- protocol: TCP
port: 32768
If enabled via the NetworkPolicyEndPort feature gate, this enhancement will allow you to define all ports as a range:
spec:
egress:
- ports:
- protocol: TCP
port: 32000
endPort: 32768
Keep in mind that in order to use this feature, your CNI plugins must also support it.
#2086 Service internal traffic policy
Stage: Alpha
Feature group: network
This enhancement is one more step to building more efficient networking in Kubernetes.
After the ServiceTrafficPolicy feature gate is enabled, a new spec.trafficPolicy field will be available on Service objects.
When this field is set to Cluster, the routing will behave as usual.
When set to Topology, it will use the topology-aware routing.
When set to PreferLocal, it will redirect traffic to services on the same node. When set to Local, it will only send traffic to services on the same node.
#2433 Topology Aware Hints
Stage: Alpha
Feature group: network
This new approach for a more optimal network routing will replace the #536 Topology aware routing introduced in Kubernetes 1.17.
The goal is to provide a flexible mechanism to provide hints to components, like kube-proxy, so they can be more efficient when routing traffic. The main use case for this feature is to keep service traffic within the same availability zone.
When enabled via the TopologyAwareHints feature gate, you’ll be able to define hints in an EndpointSlice:
apiVersion: discovery.k8s.io/v1
kind: EndpointSlice
…
endpoints:
- addresses:
- "10.1.2.3"
conditions:
ready: true
hostname: pod-1
zone: zone-a
hints:
forZones:
- name: "zone-a"
#2365 IngressClass namespaced params
Stage: Alpha
Feature group: network
With this enhancement, you can now specify parameters for an IngressClass with a Namespace scope:
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: external-lb
spec:
controller: example.com/ingress-controller
parameters:
apiGroup: k8s.example.com
kind: IngressParameters
name: external-lb
namespace: external-configuration
scope: Namespace
#752 EndpointSlice
Stage: Graduating to Stable
Feature group: network
The new EndpointSlice API will split endpoints into several Endpoint Slice resources. This solves many problems in the current API that are related to big Endpoints objects. This new API is also designed to support other future features, like multiple IPs per pod.
Read more on the release for 1.20 in the What’s new in Kubernetes series.
#2200 Block service ExternalIPs via admission
Stage: Graduating to Stable
Feature group: network
This enhancement comes as a response to CVE-2020-8554, where an attacker could act as a man in the middle. This is done by creating a ClusterIP service and setting the spec.externalIPs field to the targeted IP. Then the attacker can intercept the traffic to that IP.
The Service.spec.externalIPs[] feature has some design flaws. Part of its functionality can be replaced with the existing type=LoadBalancer, so this externalIPs field is practically not needed anymore.
A new DenyServiceExternalIPs admission controller has been created that will block any resource that uses the externalIPs field from deployment.
#563 IPv4/IPv6 dual-stack support
Stage: Graduating to Beta
Feature group: network
This feature summarizes the work done to natively support dual-stack mode in your cluster, so you can assign both IPv4 and IPv6 addresses to a given pod.
Now that it is graduated to Beta, dual stack is enabled by default.
Read more on the release for 1.20 in the What’s new in Kubernetes series.
Nodes in Kubernetes 1.21
#1769 Memory manager
Stage: Alpha
Feature group: node
A new Memory Manager component is available in kubelet to guarantee memory and hugepages allocation for pods. It will only act on Pods in the guaranteed QoS class.
This is useful for applications where memory optimization is key for performance, like packet processing with DPDK, databases, or virtual machines.
The new Memory Manager also acts as a hint provider for Topology Manager.
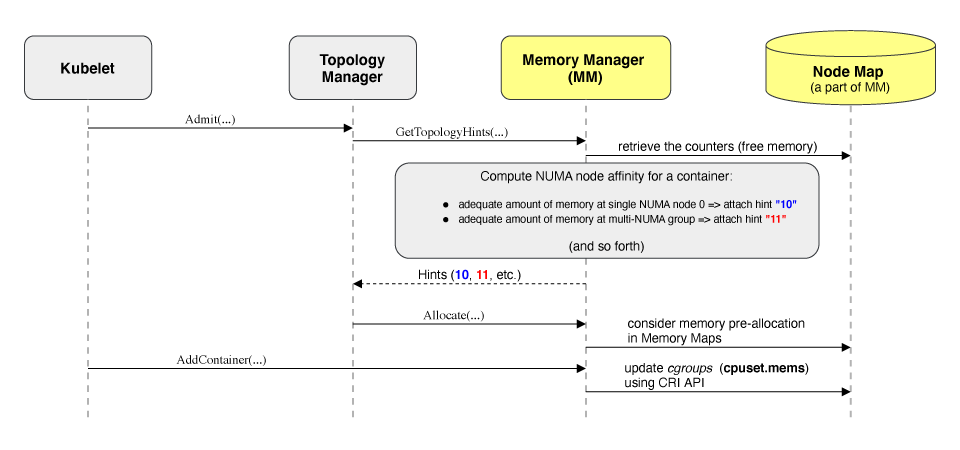
To read more about this new component, check the KEP documentation.
#2238 Add a configurable grace period to liveness probes
Stage: Alpha
Feature group: node
There is an edge case when using liveness probes together with a long grace period.
Introduced in Kubernetes 1.20, the terminationGracePeriodSeconds field of a Pod spec instructs Kubernetes to wait for a given number of seconds before killing a container after termination. This leaves the processes time to free resources and flush any important data.
Liveness probes are periodic checks that help Kubernetes know if a process is running properly, or if it is a zombie and must be killed.
One would expect that once a process freezes and does not answer its liveness probes, it should be killed right away. However, Kubernetes respected terminationGracePeriodSeconds up until now.
The edge case would be a service that needs up to one hour to shut down to properly dump data to some clients that connect to it very sparsely. If the service hangs, instead of being restarted right away, it can take up to one hour to be restarted.
This enhancement introduces a second terminationGracePeriodSeconds field, inside the livenessProbe object, to differentiate two situations: How much should Kubernetes wait to kill a container under regular circumstances, and when is the kill due to a failed livenessProbe?
spec:
terminationGracePeriodSeconds: 3600 # pod-level
containers:
- name: test
image:
…
livenessProbe:
…
# Override pod-level terminationGracePeriodSeconds #
terminationGracePeriodSeconds: 60
#34 Add sysctl support
Stage: Graduating to Stable
Feature group: node
Since Kubernetes 1.4, it has been possible to interact with the Linux sysctls service to tune specific OS parameters, according to the needs of the deployed Pods.
What graduates to Stable now is a change on how that configuration is declared in Pods. Before, annotations were used:
apiVersion: v1
kind: Pod
metadata:
name: sysctl-example
annotations:
security.alpha.kubernetes.io/sysctls: kernel.shm_rmid_forced=1
Now, fields are used:
apiVersion: v1
kind: Pod
metadata:
name: sysctl-example
spec:
securityContext:
sysctls:
- name: kernel.shm_rmid_forced
value: 1
#213 Provide RunAsGroup feature for Containers in a Pod
Stage: Graduating to Stable
Feature group: node
Being in beta since Kubernetes 1.14, this is yet another feature that is now officially GA.
Using the runAsGroupfield inside the securityContext section in a Pod definition, you can now specify the primary groups that will be assigned to the processes inside the pod containers. Note that you can also configure the fsGroupfield inside securityContext to specify supplementary group IDs.
#2129 Remove cAdvisor json metrics from the Kubelet
Stage: Graduating to Stable
Feature group: node
There are two main problems of cAdvisor being integrated into the kubelet:
- It only works in linux.
- If vendors want to provide an alternative implementation, they cannot disable the existing implementation.
That’s why the cAdvisor metrics were disabled by default in Kubernetes 1.18.
This enhancement summarizes the work done to revise this deprecation before they are removed permanently.
#2403 Extend podresources API to report allocatable resources
Stage: Graduating to Stable
Feature group: node
This addition to the kubelet pod resources endpoint (pod resources API) will allow third-party consumers to learn about the compute resources allocated to a Pod. It will include things like the name, namespaces, and containers of a Pod, and also the cpu_ids assigned to a container.
This way, alongside the existing pod resources API endpoint, it will be easier to evaluate a node capacity. Check the full details in the Kubernetes documentation.
#2411 CRIContainerLogRotation
Stage: Graduating to Stable
Feature group: node
This enhancement summarizes the work done to finally bring this feature up to Stable after being in beta since Kubernetes 1.11.
For container runtimes that communicate with the kubelet via the Container Runtime Interface (CRI), the kubelet is the one in charge of handling the container runtime logs, as well as providing the log file path to the container runtime.
When it came to implementing log rotation, it was decided that the kubelet took care of that too.
Two command line options have been added to tweak the log rotation behavior: --container-log-max-size and --container-log-max-files.
#2000 Graceful node shutdown
Stage: Graduating to Beta
Feature group: node
With the GracefulNodeShutdown feature gate enabled, Kubelet will try to gracefully terminate the pods that run in the node when shutting down. The implementation works by listening to systemd inhibitor locks (for Linux).
Read more on the release for 1.20 in the What’s new in Kubernetes series.
#2053 Add downward API support for hugepages
Stage: Graduating to Beta
Feature group: node
Pods are now able to fetch information on their hugepage requests and limits via the downward API. This keeps things consistent with other resources like cpu, memory, and ephemeral-storage.
Read more on the release for 1.20 in the What’s new in Kubernetes series.
Kubernetes 1.21 storage
#1432 Volume health
Stage: Alpha
Feature group: storage
Currently, issues in persistent volumes are hard to troubleshoot. Sometimes, it’s not easy to know if the disk where the volume resides is damaged, or if the volume was deleted by accident outside Kubernetes.
To help in this troubleshooting, the CSI API has been expanded, modifying existing RPCs and adding new ones to provide information on the volume health.
CSI drivers can load an external controller as a sidecar that will check for volumes health, and they can also provide extra information in the NodeGetVolumeStats function that Kubelet already uses to gather information on the volumes.
Check out the full implementation details in the KEP document.
#1845 Prioritizing nodes based on volume capacity
Stage: Alpha
Feature group: storage
When the initial Pod volume topology constraints were implemented (Stable since Kubernetes 1.13), the goal was to help schedule PersistentVolumes in nodes with enough capacity.
However, given a scenario with a request for a 10Gi volume, and where two nodes have enough capacity:
- Node 1: Has a 1Ti
PersistentVolumesavailable. - Node 2: Has a 10Gi
PersistentVolumesVolume available.
Both volumes have the same chance to be bound to the request. If the 1Ti one is chosen, that would be a waste of resources.
A new Score strategy is available for the VolumeBinding setting of the scheduler to mitigate this issue.
When set, for each PersistentVolumeClaim, the PersistentVolumes will be scored so the most appropriate is chosen. You can check the details of the algorithm in the KEP document.
#1412 Immutable secrets and configmaps
Stage: Graduating to Stable
Feature group: storage
A new immutable field has been added to Secrets and ConfigMaps. When set to true, any change done in the resource keys will be rejected. This protects the cluster from accidental bad updates that would break the applications.
A secondary benefit derives from immutable resources. Since they don’t change, Kubelet doesn’t need to periodically check for their updates, which can improve scalability and performance.
Read more in the release for 1.18 of the What’s new in Kubernetes series.
#1472 Storage capacity tracking for pod scheduling
Stage: Graduating to Beta
Feature group: storage
This enhancement tries to prevent pods to be scheduled on nodes connected to CSI volumes without enough free space available.
Read more in the release for 1.19 of the What’s new in Kubernetes series.
#1698 PVC inline ephemeral volumes (work with CSI driver)
Stage: Graduating to Beta
Feature group: storage
This enhancement provides a simple API to define inline ephemeral volumes that will work with any storage driver that supports dynamic provisioning.
Read more in the release for 1.19 of the What’s new in Kubernetes series.
#1885 AzureFile CSI migration
Stage: Graduating to Beta
Feature group: storage
This enhancement summarizes the work to move Azure File code out of the main Kubernetes binaries (out-of-tree).
It is part of the ongoing efforts to migrate existing code to CSI drivers (#178, #625, #1490), making the Kubernetes code easier to maintain.
#2047 CSI service account token
Stage: Graduating to Beta
Feature group: storage
With this enhancement, CSI drivers will be able to request the service account tokens from Kubelet to the NodePublishVolume function. Kubelet will also be able to limit what tokens are available to which driver. And finally, the driver will be able to re-execute NodePublishVolume to remount the volume by setting RequiresRepublish to true.
This last feature will come in handy when the mounted volumes can expire and need a re-login. For example, a secrets vault.
Read more in the release for 1.20 of the What’s new in Kubernetes series.
Kubernetes 1.21 API
#2155 Apply for client-go’s typed clients
Stage: Graduating to Stable
Feature group: api-machinery
When a Kubernetes API client based on client-go wants to invoke the server side apply, it has to call Patch, providing a []byte containing a YAML or JSON.
This is error prone, as there are no type checks involved and an error in the payload can cause unexpected effects.
To mitigate this, new Apply methods have been implemented that will complement the existing Patch, making things easier (and safer) for developers.
#1904 Efficient watch resumption
Stage: Graduating to Beta
Feature group: api-machinery
From now on, kube-apiserver can initialize its watch cache faster after a reboot.
Read more in the release for 1.20 of the What’s new in Kubernetes series.
#2161 APIServer defaulted labels for all namespaces
Stage: Graduating to Beta
Feature group: api-machinery
As namespaces are not guaranteed to have any identifying labels by the Kubernetes API, you would have to use a field selector to select a namespace, instead of its name. This complicates tasks like writing default network policies and other label-driven namespace functionalities in the Kubernetes API.
A new immutable label kubernetes.io/metadata.name has been added to all namespaces, whose value is the namespace name. This label can be used with any namespace selector, like in the previously mentioned NetworkPolicy objects.
Authentication in Kubernetes 1.21
#541 External client-go credential providers
Stage: Graduating to Beta
Feature group: auth
This enhancement allows Go clients to authenticate using external credential providers, like Key Management Systems (KMS), Trusted Platform Modules (TPM), or Hardware Security Modules (HSM).
Those devices are already used to authenticate against other services, are easier to rotate, and are more secure, as they don’t exist as files on the disk.
Initially introduced on Kubernetes 1.10, this feature continues the work done in 1.20 and is expected to be GA in Kubernetes 1.22.
#542, #1205 TokenRequest API and Kubelet integration
Stage: Graduating to Stable
Feature group: auth
The current JSON Web Tokens (JWT) that workloads use to authenticate against the API have some security issues. This enhancement comprises the work to create a more secure API for JWT.
Read more in the release for 1.20 of the What’s new in Kubernetes series.
#1393 ServiceAccountIssuerDiscovery GA
Stage: Graduating to Stable
Feature group: auth
Kubernetes service accounts (KSA) can currently use JSON Web Tokens (JWT) to authenticate against the Kubernetes API, using kubectl --token <the_token_string> for example. This enhancement allows services outside the cluster to use these tokens as a general authentication method without overloading the API server.
Read more on the release for 1.18 in the What’s new in Kubernetes series.
Other enhancements
#859 Include kubectl command metadata in http request headers
Stage: Alpha
Feature group: cli
Starting in Kubernetes 1.21, kubectl will include additional HTTP headers in the requests to the API server. By knowing what kubectl command triggered a given request, administrators will have useful information to aid in troubleshooting and enforcing best practices.
These extra headers are:
X-Kubectl-Command: With the kubectl command (apply, delete, create secret tls).X-Kubectl-Flags Header: With the command flags (–filename=local).X-Kubectl-Session Header: Containing the session id, linking multiple requests.X-Kubectl-Deprecated Header: If the given command is deprecated.X-Kubectl-Build Header: Containing a string, customizable in build time.
#2227 Default container annotation to be used by kubectl
Stage: Alpha
Feature group: cli
The first container to be executed is currently considered the default container of a Pod. However, with Service Mesh, Pods can always have two containers: The main one and the sidecar that runs first.
This complicates several admin tasks, like reading the information from kubectl logs or using kubectl exec (as without the -c flag it will use the default container).
A new kubectl.kubernetes.io/default-container annotation has been added to Pod to define the default container.
#2436 Leader migration for controller managers
Stage: Alpha
Feature group: cloud-provider
As we discussed in #1885, there is an active effort to move code specific to cloud providers outside of the Kubernetes core code (from in-tree to out-of-tree).
However, this breaking change will be problematic for clusters with strict requirements on control plane availability.
This enhancement establishes a migration process for those clusters, focused on migrating them from running kube-controller-manager to run cloud-controller-manager.
Check the Kubernetes documentation to get the details.
#2420 Reducing Kubernetes build maintenance
Stage: Graduating to Stable
Feature group: testing
Kubernetes currently maintains multiple build systems which increases the required maintenance, and causes friction and confusion.
This enhancement summarizes the work done to move all build scripts to make build, and remove bazel build.
That’s all for Kubernetes 1.21, folks! Exciting as always; get ready to upgrade your clusters if you are intending to use any of these features.
If you liked this, you might want to check out our previous ‘What’s new in Kubernetes’ editions:
- What’s new in Kubernetes 1.20
- What’s new in Kubernetes 1.19
- What’s new in Kubernetes 1.18
- What’s new in Kubernetes 1.17
- What’s new in Kubernetes 1.16
- What’s new in Kubernetes 1.15
- What’s new in Kubernetes 1.14
- What’s new in Kubernetes 1.13
- What’s new in Kubernetes 1.12
And if you enjoy keeping up to date with the Kubernetes ecosystem, subscribe to our container newsletter, a monthly email with the coolest stuff happening in the cloud-native ecosystem.