
Sysdig Monitor
Kubernetes and cloud monitoring with a managed Prometheus service.
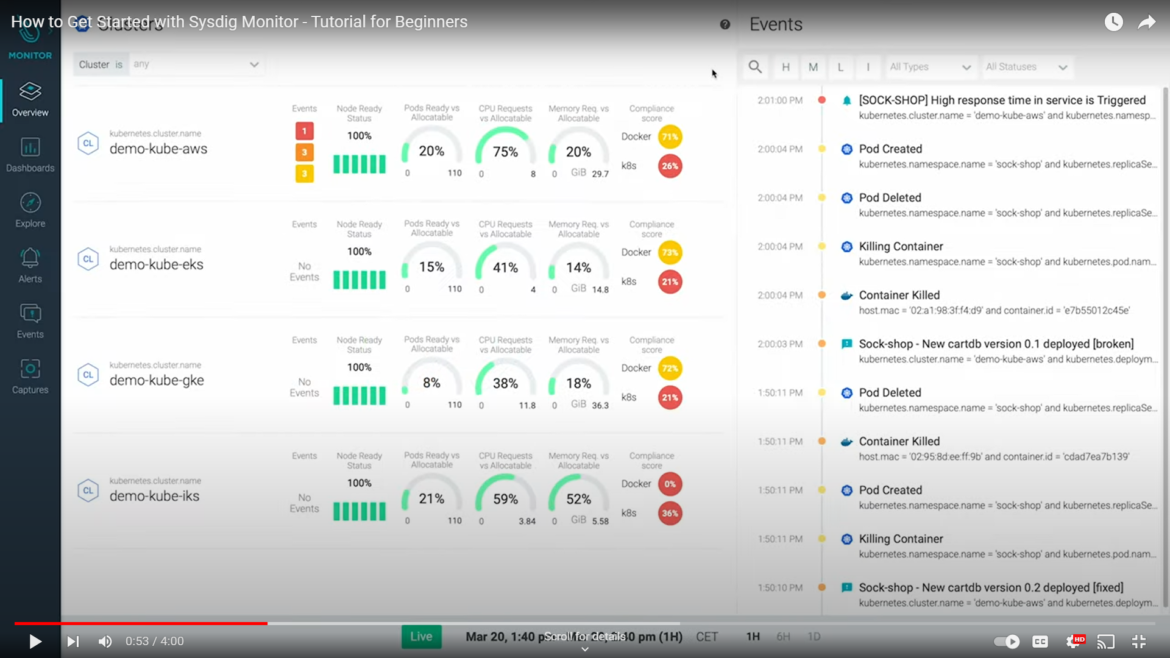
Radically Simplified Monitoring
Sysdig Monitor makes it easy to find detailed information about your Kubernetes environment. Bonus: We are fully Prometheus compatible!
Kubernetes
Monitoring
See all Kubernetes details in one place and troubleshoot Kubernetes errors up to 10x faster.
Managed
Prometheus
Prometheus made simple with a managed service. Scale quickly with out-of-the-box dashboards, alerts, and integrations.
Optimize Cloud Native Application Costs
Reduce wasted spending by 40% on average and save with low-cost custom metrics.
Sysdig Monitor Advantages
Faster Troubleshooting
Troubleshoot Kubernetes errors faster with a prioritized list of issues, pod details, live logs, and remediation steps.
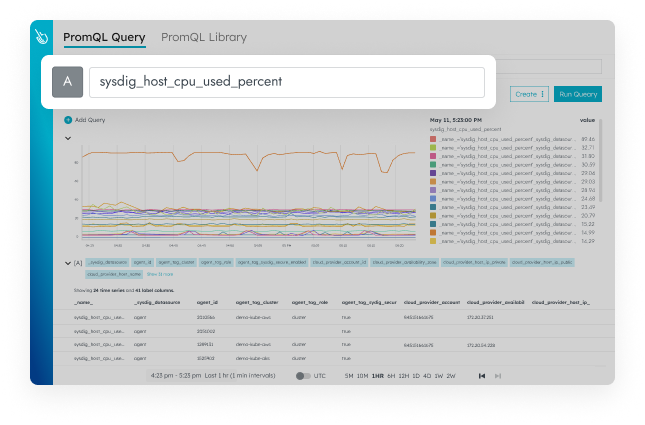
Simplify and Scale Prometheus
Our managed Prometheus service saves time! Use our scalable data store, automatic service discovery, and assisted integration deployment. Keep your PromQL and Grafana dashboards.
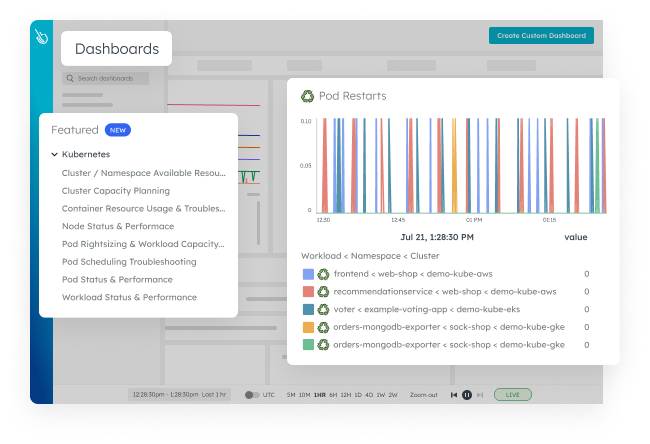
Dashboards and Alerts
Dashboards are available out of the box and you can customize any dashboard easily. Alerts are highly configurable and ready to integrate into your alert management system.
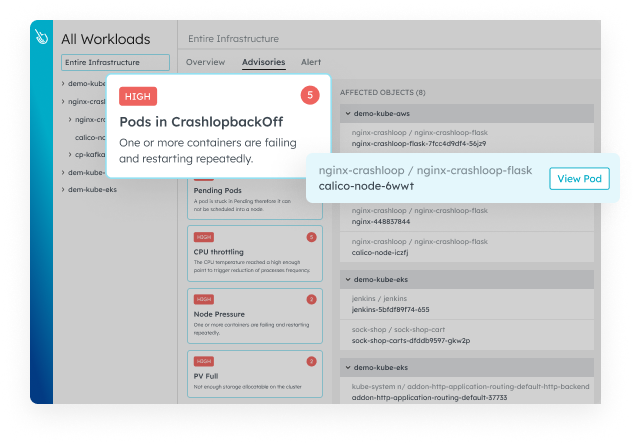
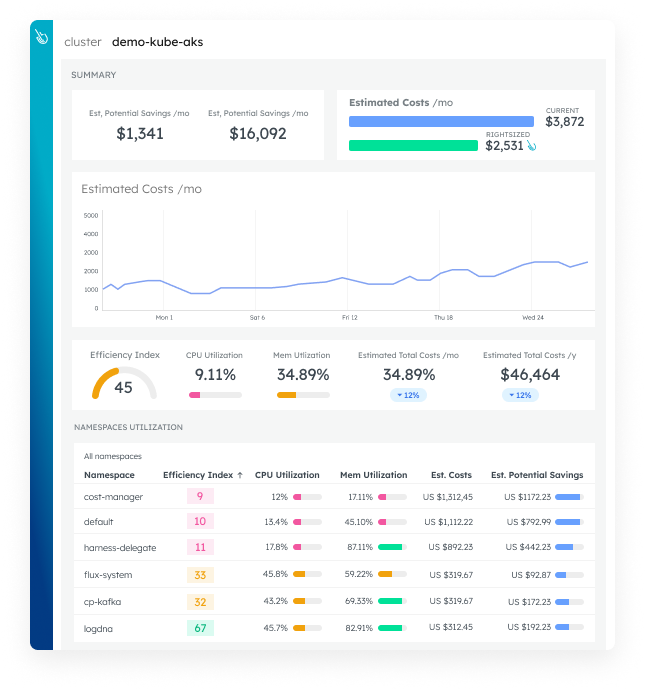
Optimize Costs
See detailed utilization of your Kubernetes resources to eliminate wasteful spending. Cut costs with our affordable custom metrics and quickly see where those metrics are coming from.
Deep Visibility for Containers, Kubernetes, and the Cloud
Kubernetes & Container Monitoring
Gain deep visibility into Kubernetes health and performance.
Learn MoreManaged Service for Prometheus
Monitoring that is radically simple and fully compatible with open source.
Learn MoreKubernetes Cost Optimization
Predictable cost analysis and savings estimates for Kubernetes.
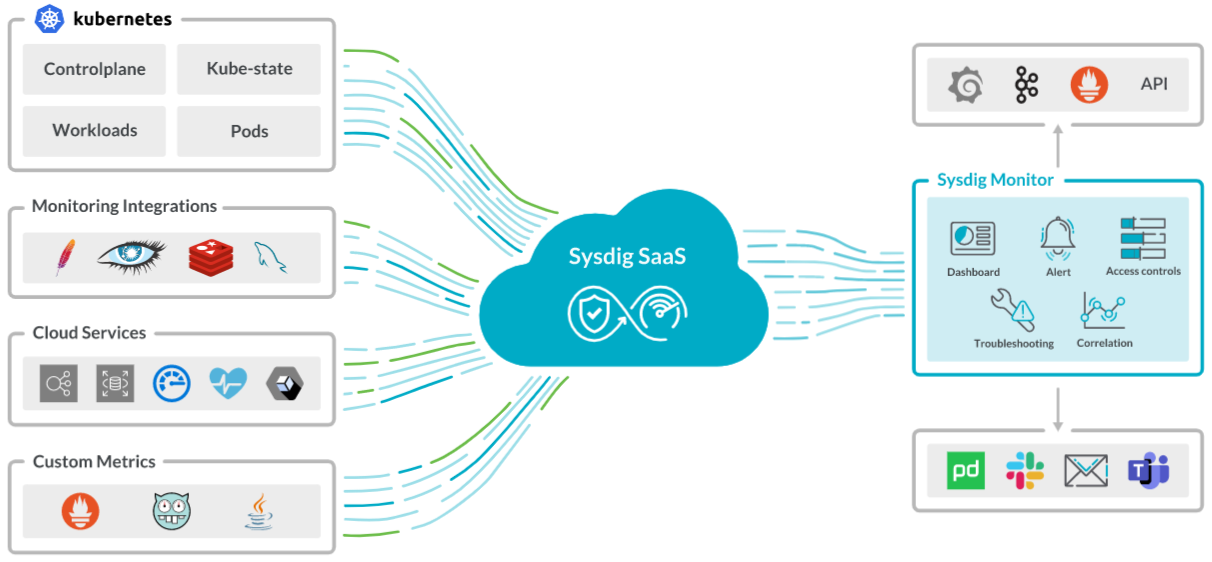
Learn MoreHow It Works
Sysdig Monitor collects metrics about your environment; we then correlate and enrich those metrics so you get application availability, performance, and fast problem resolution.
Based on
Open Standards
Sysdig grew out of open source, and we are a big supporter of open standards. Open standards like Falco and Prometheus benefit users by providing a consistent approach to solving problems while avoiding vendor lock-in.






Take the Next Step!
See a live demo how observability with Sysdig Monitor can help you.
Deep visibility for containers, Kubernetes, and cloud.