


Falco Feeds extends the power of Falco by giving open source-focused companies access to expert-written rules that are continuously updated as new threats are discovered.

Vulnerability assessment and vulnerability management practices are critical to minimizing the exposure and attack surface of your whole infrastructure.
We're human, and many things we build aren't perfect. That's why we take our cars for a periodic inspection, and also why we have organizations certifying that products are safe to use.
Software is no different.
Over the last decade, software has increased in complexity. Moreover, pressure for faster and constant delivery of new features often translates into subtle bugs that might go unnoticed by testing and QA. Many of these bugs will be harmless, although possibly annoying, but others will cause software and systems to be vulnerable. For example:
- Completely take your hosts out of service by placing a crafted container image in a repository, as CVE-2021-20291 in CRI-O and Podman.
- Enable lateral movement and compromise a whole cloud account by exploiting a vulnerable container.
- Bring down the Internet by triggering a bug with a simple configuration change performed by an unprivileged user.
If software vulnerabilities are inevitable, and often out of our control, is there anything we can do about them?
Check these top 10 vulnerability assessment and vulnerability management best practices to learn how to secure your infrastructure from attacks, keep your vulnerabilities under control, and avoid distractions, letting you confidently focus on the key aspects of your business.
Detecting vulnerabilities
Before you can assess how badly vulnerabilities are affecting your infrastructure, and before you start building an action plan to manage them, you need to know what vulnerabilities you're dealing with.
Let's look at tools and techniques that can detect known vulnerabilities in different phases of the software lifecycle, from development to runtime. We're placing a big emphasis on known. As we'll cover later on, vulnerabilities might be present but may not be discovered yet. More about this in a bit.
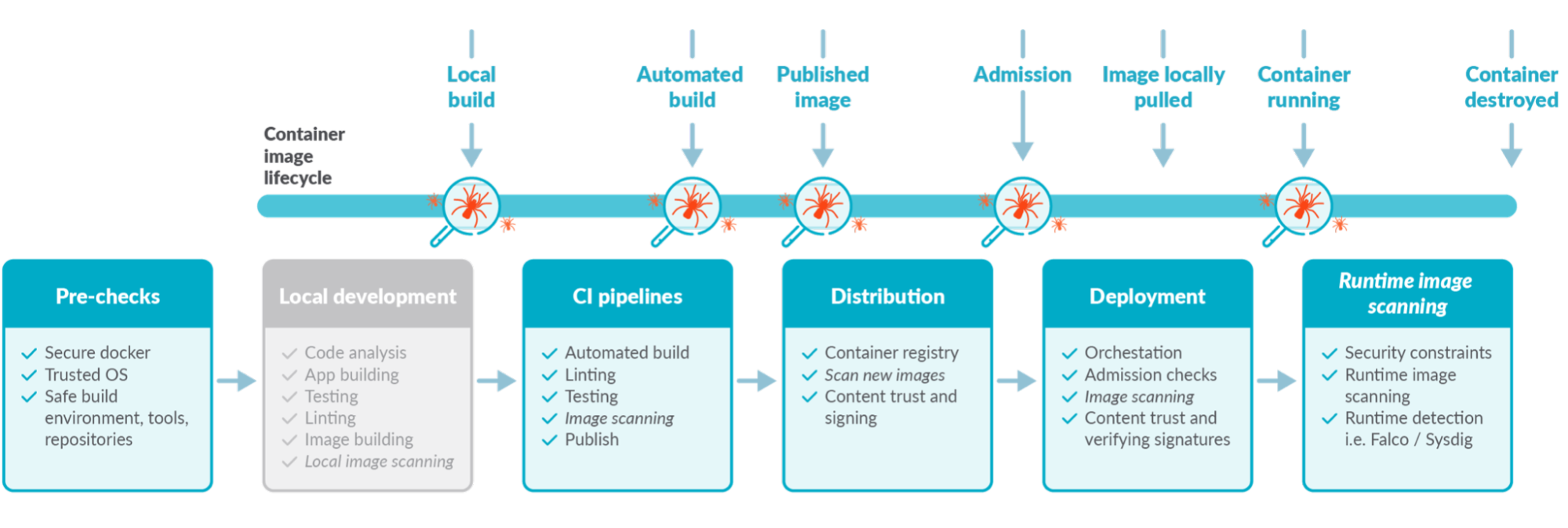
1. Vulnerability assessment at development
Package management tools usually offer integrated vulnerability scanning for installed packages. For example, npm audit for node (it will automatically run when installing a new package) and maven dependency-check allow the developer to detect existing vulnerabilities in your library dependencies.
Github dependabot, Gitlab security scanner, and artifact repositories usually offer options to scan package dependencies and report vulnerabilities, or integrate with other tools to perform the scanning.
Developers can and should take measures to avoid using packages with known vulnerabilities. Usually, the cause is using outdated packages and the fix is to simply bump the version to a newer one containing the fix, and tackle breaking changes on some occasions (see more in the planning section!).
Also, tools for static code analysis can warn the developer of bad practices or bugs in the code that can turn into vulnerabilities.
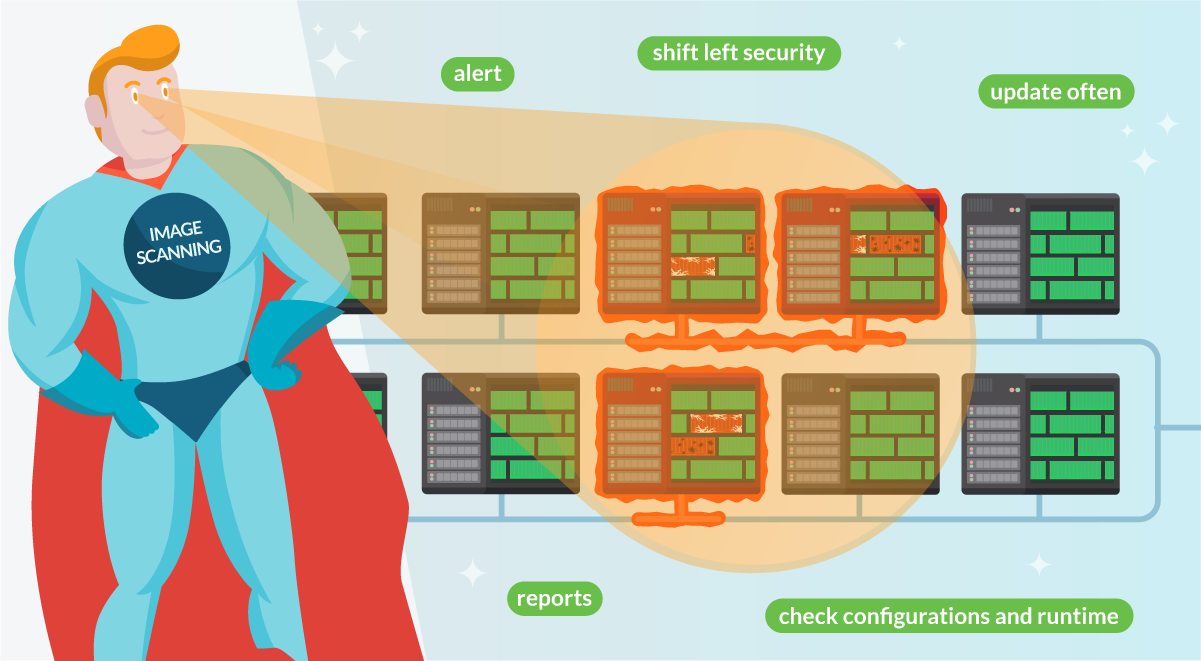
2. Enable vulnerability assessment and management with image scanning
Containers are a pretty convenient way of shipping software. They increase security by running processes in their jailed environment by using kernel namespaces and other mechanisms. Containers lay somewhere in between the full isolation provided by Virtual Machines, and the lighter processes running in a shared environment.
If your software is delivered as a "container image," it will include the main binaries and all the required dependencies. This makes it easier to analyze its contents, including all dependencies, packages, and libraries, as well as the ability to compare them against known vulnerability databases. This way, you can get a picture of which vulnerabilities might affect you when running the container.
Performing this scanning process for everything you deploy in production is key to assessing your security posture. This extends to both the images you are building and third-party images.
Automated image scanning is the tool that enables this process. It's good to review image scanning best practices from time to time. After all, the deeper your image scanning digs, the easier it will be to assess and manage the vulnerabilities you discover. For example, is your scanner just looking on the images metadata, or does it also check the third-party libraries they contain?
3. Scan your cloud tasks
Serverless services, like Fargate or the newly introduced AWS App Runner, are trending. By leveraging them, teams can deploy their containers without worrying too much about the infrastructure. That way, they can focus on what's really important: shipping new features faster.
One could naively think that, as a managed service, you can forget about security. But that's pretty far from the truth. Look at this example scenario, where a vulnerable container can enable lateral movement to compromise a whole cloud account.
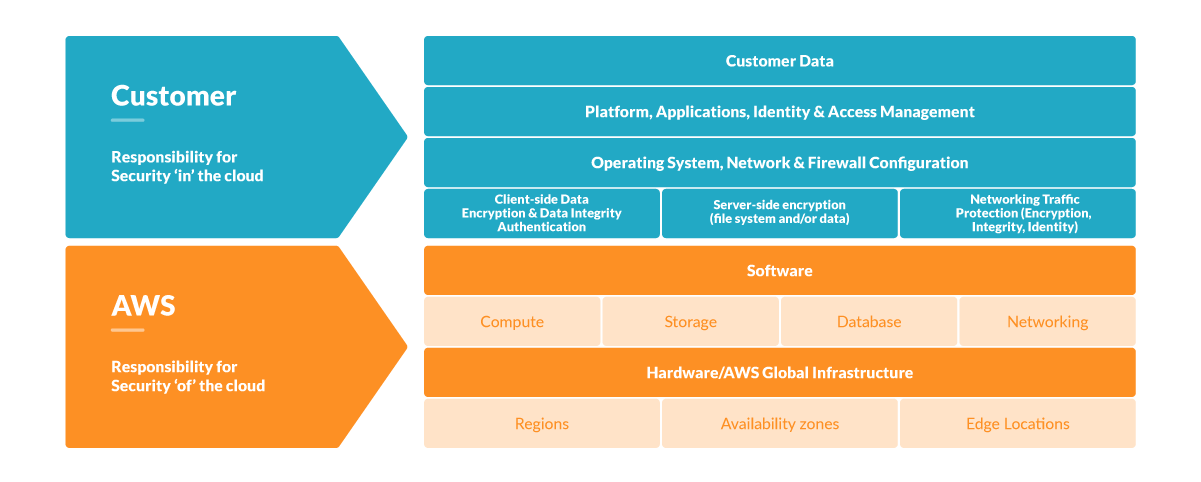
Cloud providers operate under a shared responsibility model. So, providers will secure the underlying service, providing fixes for low-level vulnerabilities like Meltdown and Spectre. Meanwhile, you'll secure the apps you deploy on that service. You can dig deeper into this subject by checking the ECS Fargate threat modeling.
Whether via a CI/CD Pipeline or from a container registry, it is a vulnerability management best practice to scan the cloud tasks you deploy on serverless services.
4. Don't forget host scanning as part of your vulnerability assessment
It would be easy to forget about the host that is actually running your containers. After all, access to them is highly secured, making it nearly impossible to exploit a vulnerability on a host.
As a result we often see how teams implement host scanning just to check a box in their compliance validation. Not integrating the results of the scan into the vulnerability assessment and management process renders host scanning useless.
Keep these two scenarios in mind:
- After compromising one container, an attacker will look for a vulnerability that allows escaping the container. If they succeed, they may exploit vulnerabilities in the host to perform cloud lateral movement, compromising your whole infrastructure.
- Some vulnerabilities, like CVE-2021-20291 for CRI-O and Podman, can be exploited without access to your hosts. Uploading a crafted image to your registry is enough to successfully perform a DoS attack on affected hosts.
It is a vulnerability assessment best practice to treat host scanning at the same level as regular image scanning.
Sysdig Secure consolidates image and host scanning, speeding up fixes, making it easier to validate compliance across your whole infrastructure. And it's radically simple to deploy.
Check our demo to learn more →
5. Check for misconfigurations that renders your infrastructure vulnerable
It doesn't matter that you patched all your software vulnerabilities if your configuration is leaving the door open.
It is a vulnerability assessment best practice to check and alert on vulnerable configurations.
Most image scanners can check for exposed ports or leaked credentials. Leverage those features.
When static configuration is managed through a code repository (infra as code), it can pass the same QA processes that the rest of your software goes through. Avoid changing configurations without a review process, and implement static code scanning.
And for cloud services, you can leverage tools like cloud custodian to alert on misconfigurations, like having S3 buckets accessible to the public.
Network security is especially sensible, as it's the main tool to isolate services and block malicious actors from performing lateral movement. Take special care to monitor changes on network configurations.
Blocking vulnerabilities
Now that we agree that image scanning is basic for vulnerability assessment, the next question is: When should you perform the scans?
The answer is anytime possible.
The sooner you detect a vulnerability, the earlier you can act and the easier it is to fix.
6. Block vulnerabilities as soon as they are generated
If developers get a warning while writing the software, they can address it right away and the vulnerabilities will never reach production.
You are probably already using build scripts with make, npm, or maven. You can leverage them to include an inline image scanning step and let your developers fix the vulnerabilities before even committing the code.
As an extra step, you can also implement scanners in your code repositories (e.g., Jenkins or Github Actions run checks) to block merging Pull Requests in code containing vulnerabilities.
7. Do not publish vulnerable containers
If you are building and publishing images from a CI/CD pipeline, you can perform a quick inline image scan to ensure no vulnerabilities are published to a registry and used by mistake.
Let's highlight the convenience of performing the scan inline (i.e., in the same pipeline that creates the image) and before we publish it in a registry.
This strategy is not only fast, but can also be leveraged to detect credentials included by mistake. Blocking those images will prevent the credentials from being published in a registry, where they could reach unwanted hands.
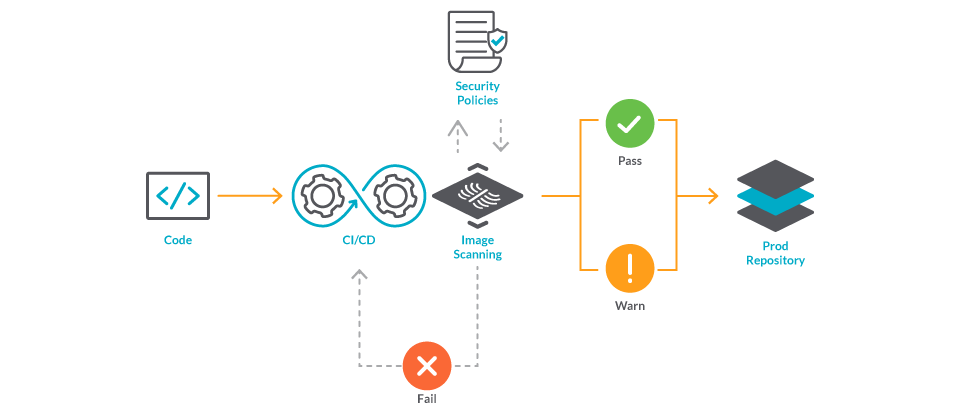
8. Stop vulnerabilities from reaching production
Some container image registries, like Harbor, will scan your images directly from the registry. And strengthening security even further, they can block your services from pulling the images that don't pass the scan.
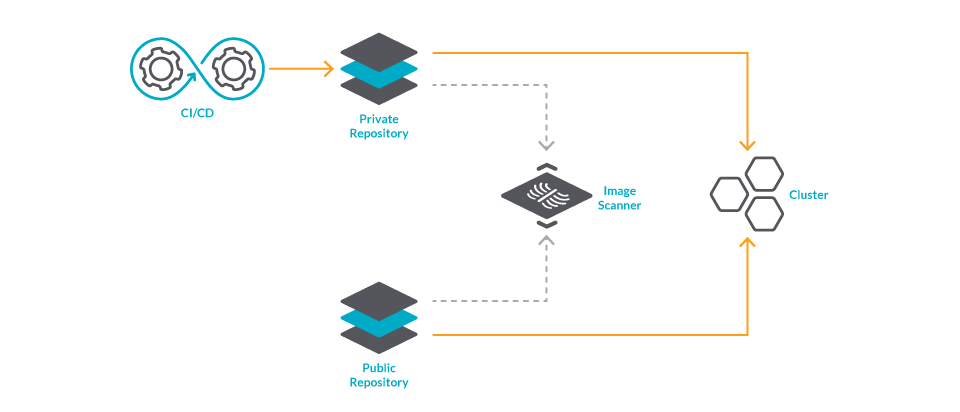
Finally, to cover for images that may be deployed from external repositories, you can perform image scanning at the Kubernetes admission level.
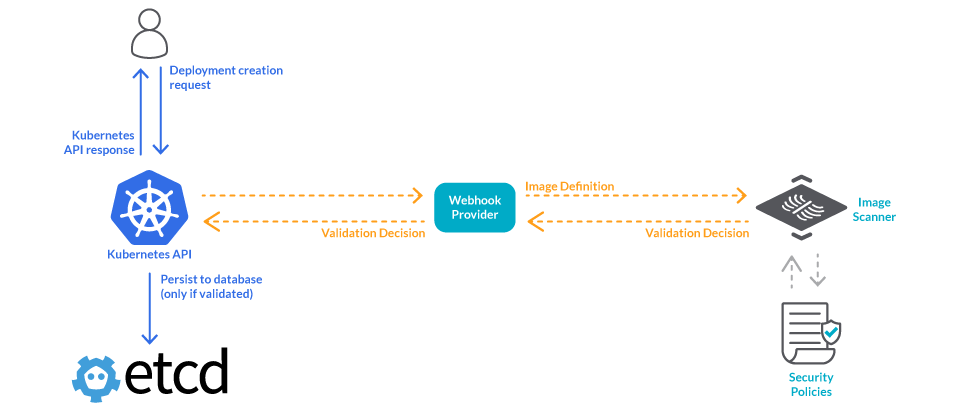
9. Catch up with new vulnerabilities
We just covered how image scanning can be used to prevent known vulnerabilities from reaching production. But what about those that haven't been disclosed yet?

A continuous scan of your runtime workloads will alert you on newly discovered vulnerabilities. So, you can hopefully implement a fix before they are exploited.
Keep in mind that image scanning does not replace runtime security. It takes some time to discover vulnerabilities. Until then, they can only be mitigated by detecting abnormal behavior in your runtime. We'll cover this later on.
So far, we presented six places where you can implement image scanning, each providing a different advantage. Isn't that a bit complicated to manage? Well, it all depends on the tools.
Look for tools that:
- Can be plugged on all those points of the container lifecycle.
- Allows the use of the same global policies at each step.
- Centralizes all the scan results in the same place, simplifying reporting.
Vulnerability assessment and management
There are all kinds of vulnerabilities, but should you block them all?
There are too many questions to be answered by your teams when a vulnerability is found. Without some global policies, your team may take too long to address important vulnerabilities, and spend too many resources on non-important ones.
Company-wide policies can help them react faster and more efficiently. Remember to cover the following points in your policy:
- How to handle pre-deployment vulnerabilities: When to block? When to pass?
- How to handle runtime vulnerabilities: When to kill? When to isolate?
- How to isolate a vulnerable service?
- Development practices to reduce attack surface and speed up response times.
- Like using company-wide base images.
- Define a versioning strategy.
Let's cover some of these points in detail.
10. Tailor vulnerability assessment and management to your specifics
The main metric you can use to prioritize vulnerabilities is the severity they are reported on.
But that's just a generalization. You should also assess how it truly affects you.
Does an exploit exist?
What is needed to exploit it?
A medium severity vulnerability may require a very specific, unusual configuration. But if you happen to have deployed that configuration, the vulnerability may be of critical severity for you.
11. Differentiate vulnerability assessment for development and production
When it comes to development, managing vulnerabilities is straightforward.
You may decide to let low severity vulnerabilities pass, but block deployment of all images containing vulnerabilities with a severity higher than medium.
What about the vulnerabilities affecting runtime workloads?
If you're lucky, you may be able to just kill that service for a while. However, if you cannot disturb the service right away, you can implement some mitigation measures.
For example, further isolate vulnerable services with tools like network policies, or move them to their own cluster. You may also put runtime security policies in place to detect when a vulnerability is exploited.
When it comes to those vulnerabilities already deployed on runtime workloads, every second counts. If your policies contemplate those scenarios, your team will save precious time right when they need it most.
12. Cover part of your development process in your policies
Implementing dockerfile best practices can highly reduce the attack surface of your containers. For example, the ubuntu:xenial-20210114 image may contain around one hundred vulnerabilities that are inherited by others that use it as a base.
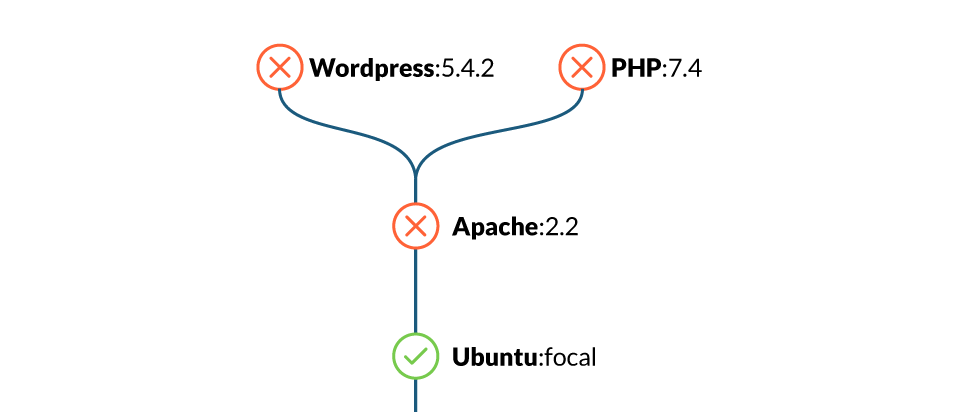
So, as a broad guideline, use well-known, minimal images to reduce the attack surface.
Applied to vulnerability management, if you build your own company-wide distroless images, you'll gain two benefits:
- By including only what is needed, you can highly reduce the number of vulnerabilities inherited from base images.
- By reusing base images, if a vulnerability is found, you can fix all the affected images at once.
13. Include updates as part of your vulnerability management process
The most common fix for a vulnerability is to update to a newer version.
However, if you haven't upgraded in a while, implementing a fix can translate into a notable development effort to address the breaking changes that may have been introduced between versions.
Planning ahead will make it easy to fix vulnerabilities quickly, and let you be ready to take action.
With that in mind, your company policy can address how to handle the versioning of software to smooth these updates. A policy like that should cover:
What versions should everyone use: Whether we are talking about libraries, applications, or base images, if everyone is using the same version, it's easier to keep track of vulnerabilities and fixes can be applied by everyone at the same time.
When should people update: It's understandable to not want to update to the latest version as soon as it's released. However, never upgrading leads to deploying year-old libraries, adding to the technical debt of your team.
You should define some guidelines so people can confidently upgrade. For example:
- Apply security patches as soon as they are out.
- Upgrade minor releases two weeks after they are released.
- Upgrade major releases one month after release.
Plan end of life: Software versions only receive security updates for a while. After that, you'll have to upgrade to a major version. As this usually includes addressing breaking changes, it's better to plan ahead and perform the big upgrade when it causes less disruption.
This is more painful with newer technologies, like Kubernetes, where the releases are more frequent and ship with bigger changes to the core components.
Starting with Kubernetes 1.19, the support window was increased to one year. If you upgrade to the latest version, you will be able to apply security updates for a year without having to worry about breaking changes.
Initiatives like that make it easier to integrate updates into your development process. For example, you can pick the least busy month of the year and dedicate it to both upgrading software components, and addressing some technical debt.
14. Make your vulnerability assessment and management reports useful
There is a huge gap between performing an inventory of your vulnerabilities and actually fixing them. The way information is presented and shared dictates how fast and efficiently that gap is closed.
As a rule of thumb, if notifying the appropriate person about a vulnerability takes too much time or effort, you are missing an opportunity.
For critical vulnerabilities, you'll want to alert the appropriate teams as soon as possible.
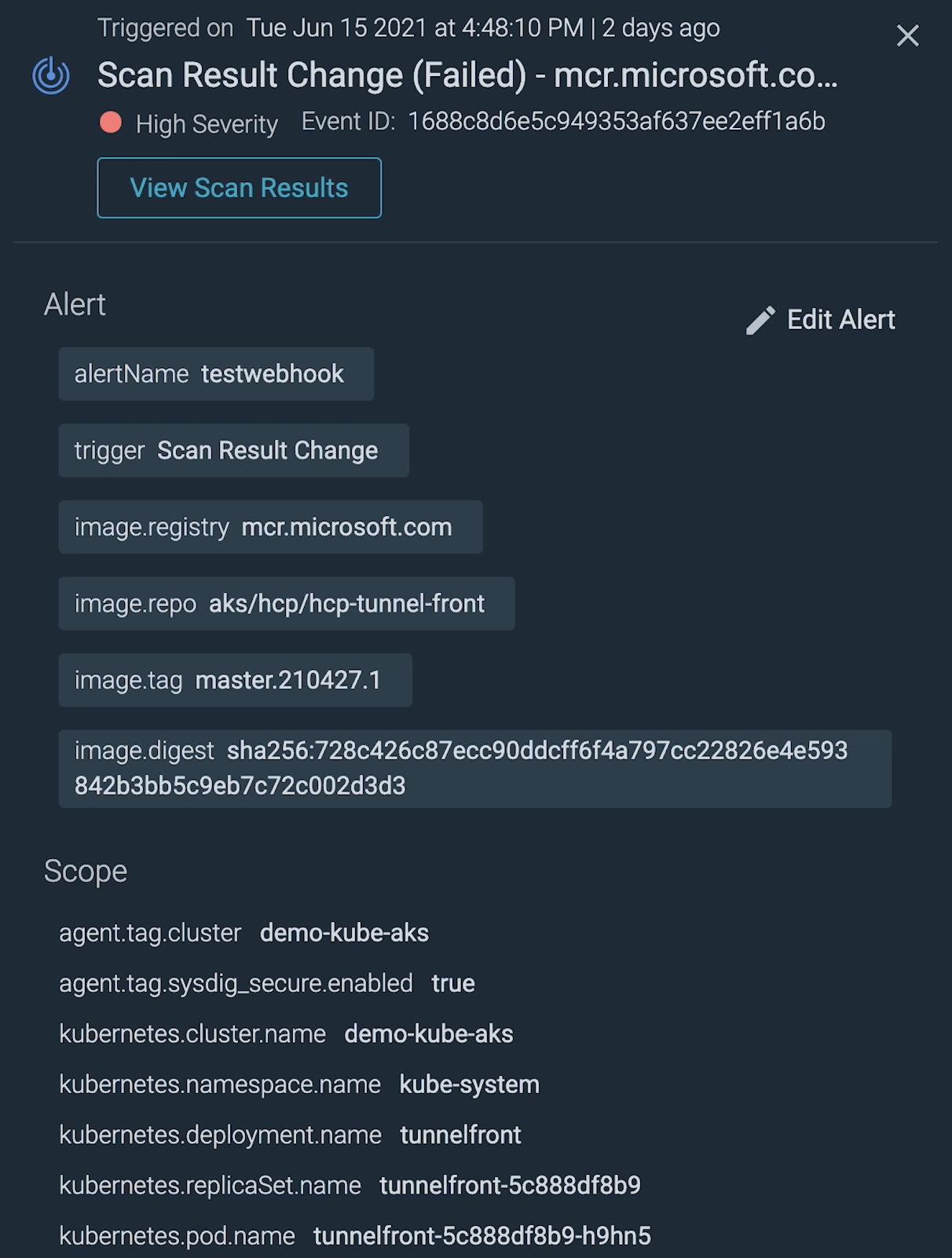
Some best practices to make alerts useful:
- Avoid noise: Only alert on the items that need immediate attention.
- Be surgical: Only alert the people that need to take action.
- Use the appropriate channels: Your team might not read an urgent email in time.
- Provide context: If the alert contains all the needed information, like what image is affected, what namespace, or what cloud task, it will save critical time.
For not so urgent vulnerabilities, reports can come quite handy.
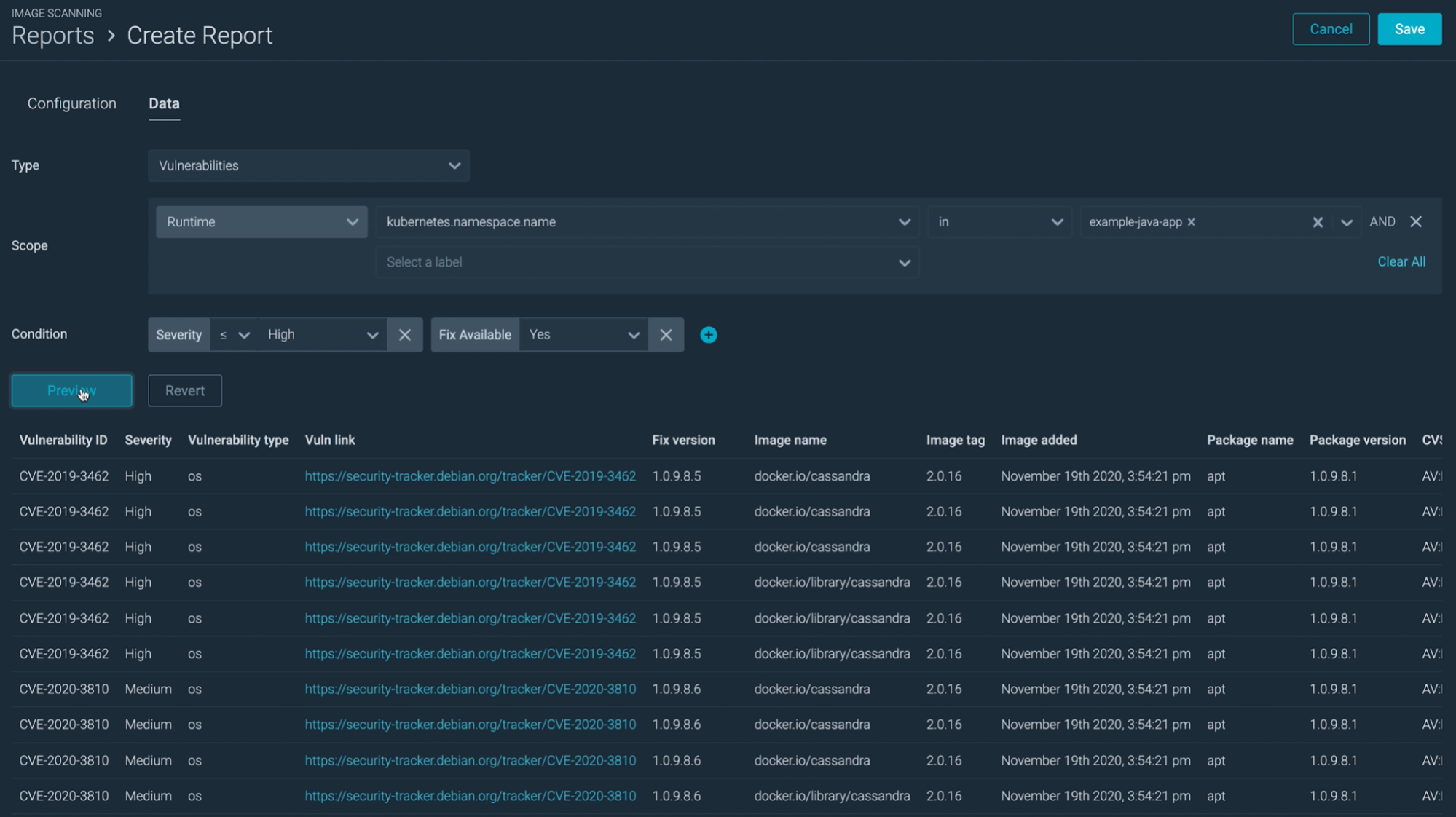
You'll want your reports to be complete and granular.
Complete enough so you can validate the compliance of your entire infrastructure without having to dig between several spreadsheets and tools.
And granular enough so you can easily group vulnerabilities by team, service, or cloud account, helping you decide where you should start acting first.
An example would be providing a weekly report for each team, consolidating all their assets that contain the information they need to plan the fixes.
When it comes to reporting, tools can be too opinionated. Make sure you can take something useful from your reporting tools beyond checking a box in your compliance requirements.
Also, what good are reports if you spend hours working with several tools to craft them? Look for tools that either consolidate all your vulnerabilities, or play well with the other tools you're using.
Plan for vulnerability exploits
We covered the limits of vulnerability management several times in this article. From vulnerabilities not yet discovered to those that we haven't fixed yet, and also vulnerable configurations, there is a lot that can go wrong.
15. Protect your runtime
Luckily, the behavior of microservices is rather predictable, so it's easy to spot when a vulnerability is exploited. That is, if you are looking for it.
Runtime security tools can read system events, so they can detect suspicious things like shells spawning on containers, new processes spawning, or configuration changes.
Like Falco, the cloud-native runtime security project, that is the de facto Kubernetes threat detection engine. Beyond Kubernetes, Falco can also protect Hosts and serverless services like AWS Fargate.
You should absolutely leverage runtime security tools.
16. Enable forensic investigations
Going one step ahead, vulnerability management and runtime security tools should enable the forensic investigation that will take place after a vulnerability is exploited.
Imagine that a vulnerability in a container is exploited, your runtime security tool detects it and immediately kills the container to block the attack.
Even if you get notified via alerts, how can you investigate the incident to prevent it from happening again? After all, once you kill the container, it doesn't exist anymore.
Knowing that the container had vulnerabilities can significantly narrow the investigation, but you'll need actual evidence to reconstruct the incident. The following features in security tools can help you:
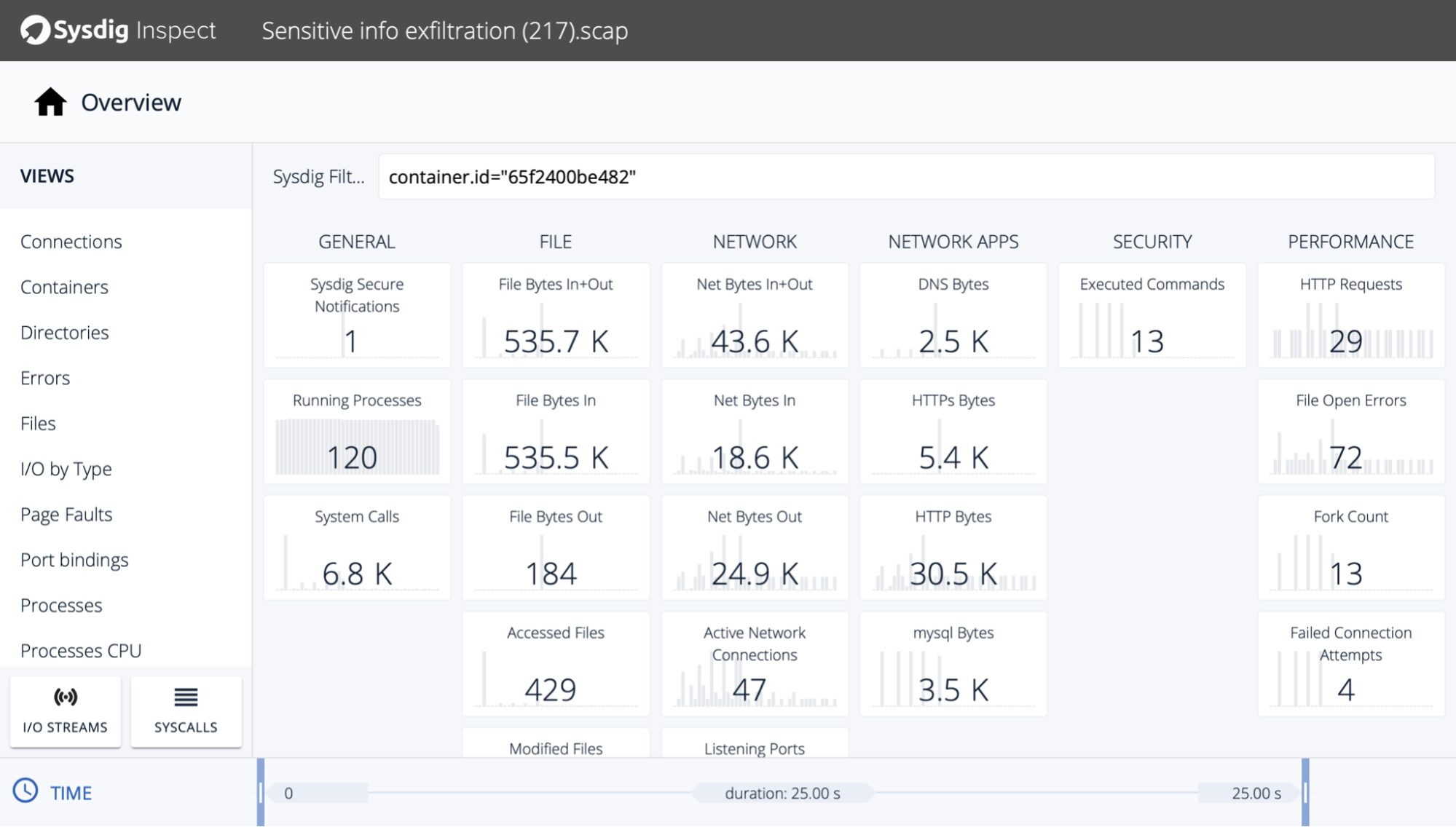
Capture system activity: Runtime security tools rely on system events to keep track of what's happening on your system. Some tools can go further and record those events in the time around a security event. With them, you can know what processes the attacker ran, what files they changed, and what network activity was involved.
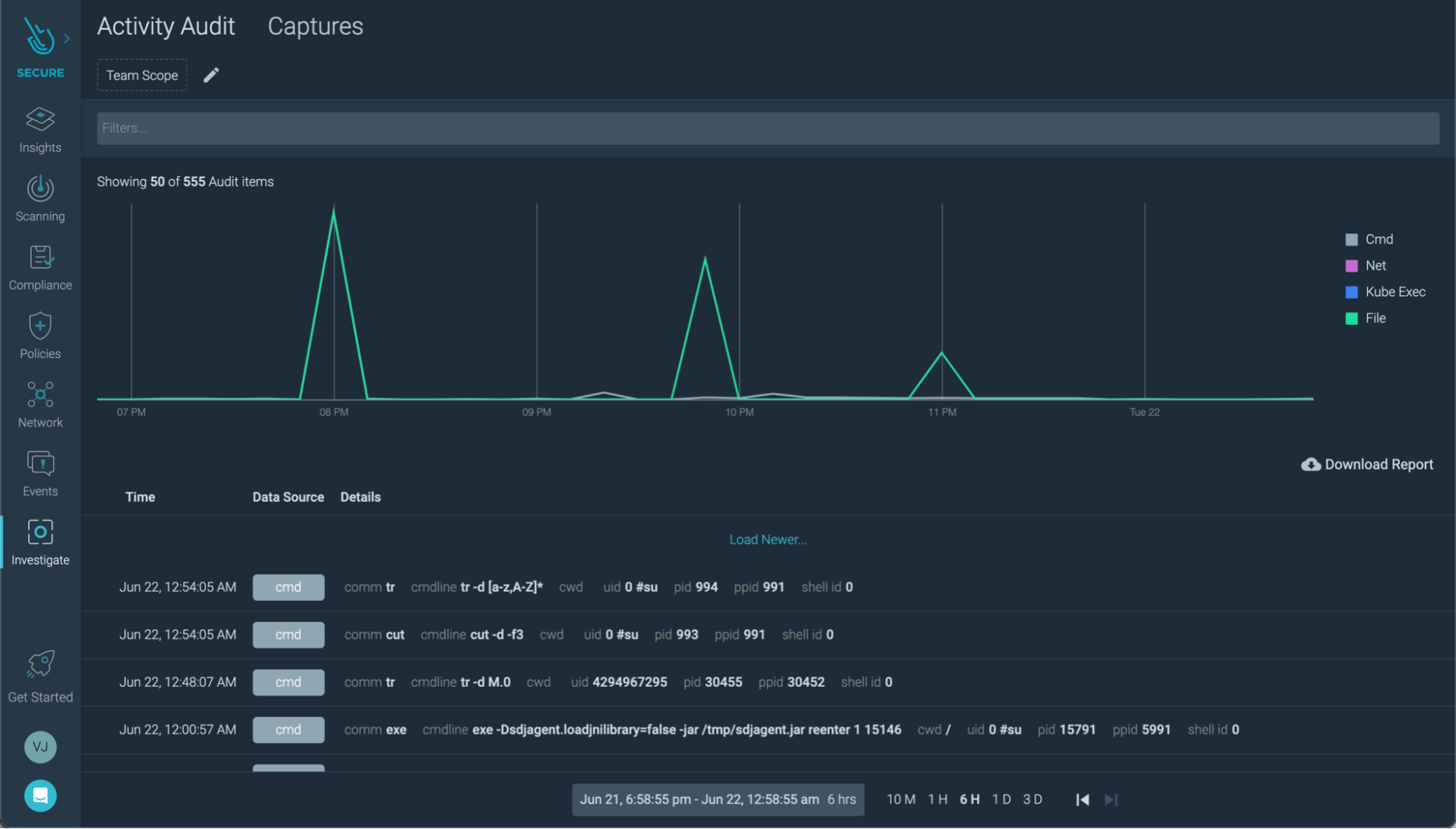
Activity Audit: Sometimes, you don't need all the system activity of a machine to investigate an event. Keeping separate audit logs per workload can be a less noisy complement. You can check the audit log of a specific container, then jump into a system event capture if you need to fill the gaps.
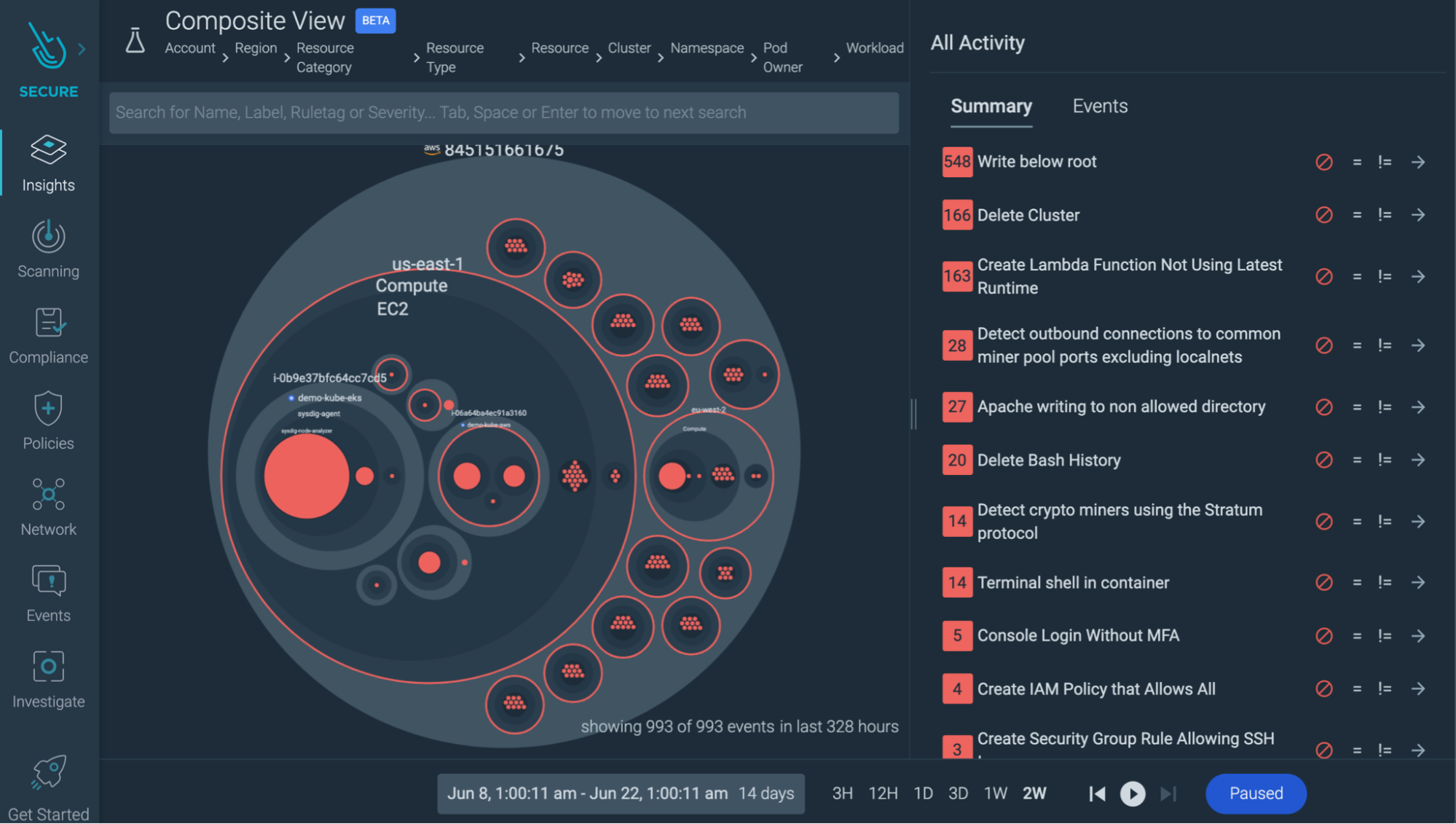
Correlated data: In the cloud and microservices world, incidents are rarely isolated. You may find a crypto miner running in a container, kill the container, and call it a day.
But if you could watch security events from your whole infrastructure in a single overview, you may also find that right before the attack, one of your developers signed without multi-factor authentication. Maybe what was compromised wasn't just a container, but some user credentials? The investigation just gained another dimension.
Look for tools that help you correlate misconfigurations with security events.
Conclusion
Software is not perfect and that causes security issues. Thankfully, with image scanning and other best practices, we can mitigate the impact of vulnerabilities.
Blocking vulnerabilities is not always enough, so keep an eye on runtime security.
And overall, look for security tools that make your life easier. Better reporting and faster response times can mark the difference between a security incident and becoming a trending topic.
Implement vulnerability assessment and vulnerability management with Sysdig Secure
Sysdig Secure consolidates image and host scanning, speeding up fixes and making it easier to validate compliance across your whole infrastructure. And it's radically simple to deploy.
With Sysdig Secure for cloud, you can continuously flag cloud misconfigurations before the bad guys get in, and detect suspicious activity like unusual logins from leaked credentials. This all happens in a single console, making it easier to validate your cloud security posture. And it only takes a few minutes to get started!
Start securing your cloud for free with our Sysdig Free Tier!