


Falco Feeds extends the power of Falco by giving open source-focused companies access to expert-written rules that are continuously updated as new threats are discovered.

Learning how to monitor the Kubernetes API server is crucial when running cloud-native applications in Kubernetes environments.
The Kubernetes API server can be considered as the front end of the Kubernetes control plane. Any interaction or request from users or internal Kubernetes components with the control plane go through this component. Ensuring you monitor the Kubernetes API server properly is of vital importance to ensure your Kubernetes cluster works as expected.
Anticipate any problem in the Kubernetes API server by monitoring errors, as well as measuring latencies, requests, and saturation.
Would you like to learn more about monitoring the API server? Do you want to know what the key kube-apiserver metrics are?
You are in the right place. keep reading! 🔍
This article will cover the following topics:
- What is the Kubernetes API server?
- How to monitor Kubernetes API server
- Monitoring API server: Which metrics should you check?
- Conclusion
What is the Kubernetes API server?
The Kubernetes API server is a key component of a Kubernetes cluster. It can actually be considered as the core of the control plane. It provides a front end service, via exposing an HTTP API interface, allowing end users, other internal components of Kubernetes, and external components to establish communication. The Kubernetes API interface provides a way to query and request information on Kubernetes objects, and at the same time, it is the gateway to be used when modifying the state of API objects in Kubernetes, like Pods, Deployments, ConfigMaps, Secrets, Namespaces, etc.
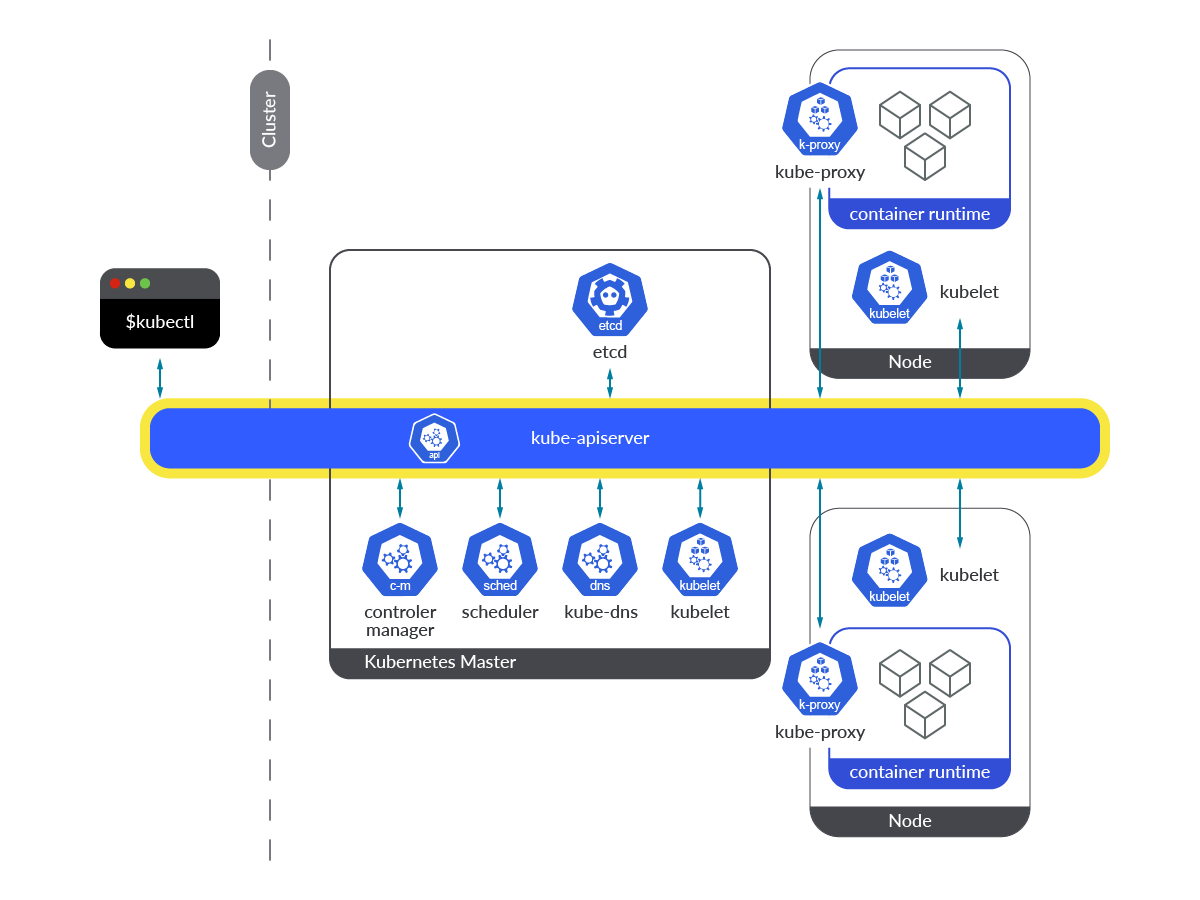
Kubernetes API server runs as a container (kube-apiserver) within Pods in the kube-system namespace. In order to make its access easier, it’s exposed through a service named kubernetes in the default namespace. Pods accessing the Kubernetes API server service (kubernetes.default.svc) are allowed to access by using a ServiceAccounttoken mounted in the Pod itself, through the secure HTTP port 443.
Any of the Kubernetes API server endpoints are accessible from each of the Kubernetes nodes or from any of the Pods running on those nodes in the cluster. In any case, the API request must be done through the default kube-apiserver endpoint port, which is 6443. If an end user tries to connect to any of these endpoints directly, it will need to possess both client certificate and key for authentication purposes, plus the CA certificate for relying on the Certificate Authority that signed the Kubernetes certificate.
Let’s see how to curl the Kubernetes API server from a random application Pod.
Another way to access the Kubernetes API server is using the kubectl CLI tool, which communicates underneath with the API, using the certificates embedded in the kubeconfig file. Every time a Kubernetes user does a kubectl get pods (or any other object), or edits any object via kubectl edit … , what is really happening is the CLI communicating with the Kubernetes API server.

How to monitor Kubernetes API server
As mentioned earlier, the API server is already instrumented to provide a metrics endpoint to monitor the Kubernetes API server. You can scrape this endpoint very easily, without the need of any additional exporter. Just get access either through the kubernetes service HTTPs port (443), or any of the endpoints HTTPs port (6443).
Let’s see how you can get access to the metrics. 🔧
Getting access to the endpoint manually
Use curl or wget to reach the kubernetes service from a Pod, either on the host network or on the default IP SDN range. You’ll need the CA (ca.crt) file for relying on the Certificate Authority that signed the Kubernetes certificate, and the token for authentication purposes. The ServiceAccount assigned to your Pod must have enough permissions to access the metrics endpoint.
Well done! You already have the kube-apiserver metrics handy!
Let’s go with the most interesting part,seeing how you can scrape these Kubernetes API server metrics from Prometheus.
How to configure Prometheus to scrape Kubernetes API server metrics
In this section, you’ll learn how to enable your Prometheus instance to scrape metrics from the Kubernetes API server metrics endpoints. If you have deployed Prometheus using the community Prometheus Helm chart, you’ll realize this and other configs are already enabled by default.
Following, you’ll find the Prometheus job. You only need edit your Prometheus ConfigMap and add it under the scrape_configs section.
Similarly, the ClusterRole you need for scraping the Kubernetes API server metrics endpoint is provided out of the box when deploying Prometheus using the community Prometheus Helm chart. Otherwise, ensure your ServiceAccount is already bound to a ClusterRole with enough permissions.
Then apply the new configuration and recreate the Prometheus-server Pod.
Once the new job is added to the ConfigMap, recreate the Prometheus Pod and wait until it starts again. Go to the Prometheus web UI and look for any of the Kubernetes API server metrics.
Monitoring API server: Which metrics should you check?
You already know how to monitor the Kubernetes API server, but there is one question that has not been answered yet: Which metrics should you check?
Grab a pen and paper if you are interested in the key Kubernetes API server metrics! 📝
Let’s split this into four different categories: the four golden signals to monitor the Kubernetes API server.
Disclaimer: API server metrics might differ between Kubernetes versions and platforms. Here, we used Kubernetes 1.25. You can check the metrics available for your version in the Kubernetes repo (link for the 1.25 version).
Latency
Latency can be considered as the time it takes to serve a request. You may want to monitor latencies on the API server requests. This way you’ll get a better understanding of how your API server is responding. High latencies, or latency growth over time, might indicate performance or availability issues in some of the API server components. The following metric used to measure latencies can be segmented by verb. That way, in the event of facing issues, you can easily identify if it is a problem reading information (GET) or writing (POST), among other things.
apiserver_request_duration_seconds_bucket: This metric measures the latency for each request to the Kubernetes API server in seconds. Data is broken down into different categories, like verb, group, version, resource, component, etc. You may want to use ahistogram_quantileto see how latency is distributed among verbs.
Traffic
The total amount of traffic handled by the API server. You may want check the total amount of requests by resource (apiservices, daemonsets, pods, namespaces, deployments, etc.), monitor how much traffic is being processed by verb (GET, POST, LIST, WATCH, etc.), or even the HTTP codes for every request or group of requests. You can evaluate whether your traffic volume is good or bad by measuring and comparing the 2xx HTTP requests vs the 4xx and 5xx HTTP requests. Saturation metrics can help identify and correlate traffic issues as well.
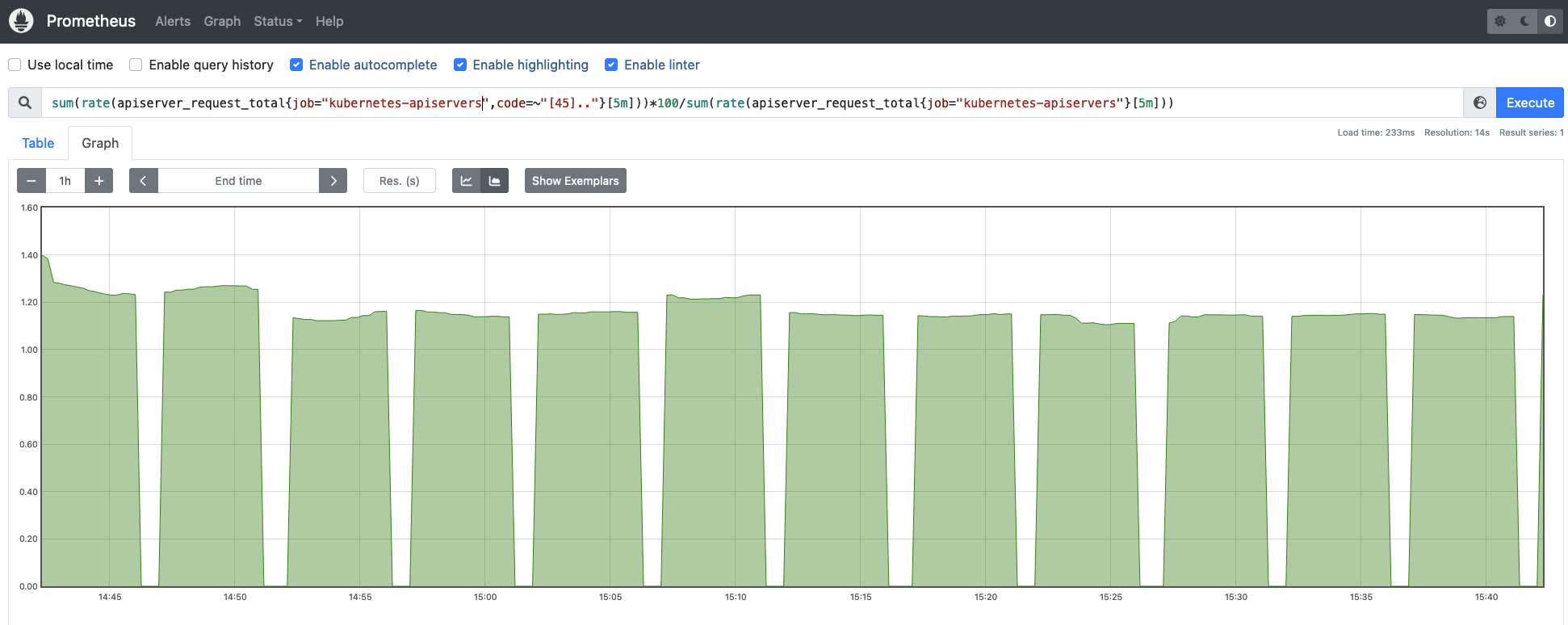
apiserver_request_total: This metric can be used to count the number of requests to the Kubernetes API server, where they are coming from, to which component it’s accessing, and whether it was successful or not. You can easily measure the successful rate of requests across the Kubernetes API service (check for 2xx HTTP response codes):
Errors
The same way you monitor the traffic, you can check the error rates and volume of errors your API server is processing. This is an easy way to identify issues at the API server level, or even on other components of the control plane.
apiserver_request_total: You can use the same metric to measure errors, this time looking for 4xx and 5xx HTTP response codes.
It is even more interesting monitoring the error rate vs the total amount of requests, this way you get the magnitude of the errors for the Kubernetes API server requests.
Saturation
You can easily monitor Kubernetes API saturation using the system resource consumption metrics, like CPU, memory, and network usage for Kubernetes API server.
There are some other metrics that will give you a better understanding of how the Kubernetes API server is performing.
workqueue_adds_total: This metric measures the number of additions handled by the workqueue.
-
workqueue_depth: This time, it measures how big the workqueue is. How many actions in the workqueue are waiting to be processed?
Conclusion
The Kubernetes API server is the core of the control plane. Queries, requests for information about the Kubernetes objects, and changes on the status of these objects are processed through this component.
Monitoring the Kubernetes API server is of vital importance if you want to ensure your Kubernetes cluster’s stability and performance. Failing in such a task may cause a lot of difficulties for your workloads and services, like not being able to stop, update, or start new Pods, Services, ReplicationController, and more.
In this article, you have learned how to monitor the Kubernetes API server, and how to use a Prometheus instance to scrape the metrics endpoint. In addition, you have learned more about the key kube-apiserver metrics, so you have all the tools you may need to be successful with monitoring the API server.
Monitor Kubernetes and troubleshoot issues up to 10x faster
Sysdig can help you monitor and troubleshoot your Kubernetes cluster with the out-of-the-box dashboards included in Sysdig Monitor. Advisor, a tool integrated in Sysdig Monitor accelerates troubleshooting of your Kubernetes clusters and its workloads by up to 10x.
Sign up for a 30-day trial account and try it yourself!